Kinesis Data Analyticsでストリーミングデータをリアルタイム分析する
Kinesis Data Analyticsの入門ということで、AWS公式で紹介されている構成を、実際に構築して検証します。
構築する環境
分析に使用するストリーミングデータは、Lambda関数で生成します。関数で実行するスクリプトは、先述の公式サイトで紹介されているPythonコードをベースにして作成します。
スクリプトは、株価をイメージしたデータを生成します。Lambda関数で生成したデータを、Kinesis Data Streamでキャプチャします。Kinesis Data Streamでキャプチャしたデータを、Kinesis Data Analyticsでリアルタイムにフィルタリングします。フィルタリングはSQLベースで実施します。Kinesis Data Analyticsは、SQLでストリーミングデータで操作することができます。具体的な検証のシナリオですが、Lambda関数で生成する株価データは、以下の5つのティッカー用のデータを対象とします。
- AAPL
- AMZN
- MSFT
- INTC
- TBV
この中から1つ選び、ランダムに株価を意味する数値を生成します。今回は上記データを100個分生成し、その中からKinesis Data Analyticsで、「AAPL」のデータのみを抽出することを目標します。
CloudFormationテンプレートファイル
上記の構成をCloudFormationで構築します。以下のURLにCloudFormationテンプレートファイルを設置しています。
https://github.com/awstut-an-r/awstut-saa/tree/main/04/001
テンプレートファイルのポイント解説
今回のアーキテクチャを構成するための、各テンプレートファイルのポイントを取り上げます。
Lambda関数でKinesis検証用データを生成する
saa-04-001-lambda.yamlでLambda関係のリソースを作成します。
Resources:
DataSourceLambda:
Type: AWS::Lambda::Function
Properties:
Environment:
Variables:
KINESIS_STREAM_NAME: !Ref KinesisDataStreamName
Runtime: python3.8
Role: !GetAtt DataSourceLambdaRole.Arn
Timeout: !Ref Timeout
Handler: index.lambda_handler
Code:
ZipFile: |
...
Code language: YAML (yaml)Environmentプロパティにて、関数に渡す環境変数を設定することができます。今回は後述のKinesis Data Streamsのストリーム名を渡します。Codeプロパティにて、関数内で実行するスクリプトを設定します。今回はZipFileプロパティに、直接コードを記述します。Lmabda関数の詳細については、以下のページをご確認ください。

インラインにて、株価データを生成する関数を定義します。今回は100個分の株価データを用意しますが、この関数はその1つ分のデータを生成します。
def get_data():
return {
'EVENT_TIME': datetime.datetime.now().isoformat(),
'TICKER': random.choice(['AAPL', 'AMZN', 'MSFT', 'INTC', 'TBV']),
'PRICE': round(random.random() * 100, 2)}
Code language: Python (python)データは以下の3つの情報で構成されます。
- EVENT_TIME:現在日時。
- TICKER:銘柄のティッカー。ランダムに5銘柄から1つ選ぶ。
- PRICE:株価。ランダムに生成する。
上記の関数を呼び出して、順次、Kinesis Data Streamに配信します。
STREAM_NAME = os.environ['KINESIS_STREAM_NAME']
LIMIT = 100
def generate(stream_name, kinesis_client, limit):
for i in range(limit):
data = get_data()
print(data)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data).encode('utf-8'),
PartitionKey="partitionkey")
def lambda_handler(event, context):
generate(STREAM_NAME, boto3.client('kinesis'), LIMIT)
Code language: Python (python)put_recordメソッドを呼び出してKinesis Data Streamsに配信します。引数として、配信先のストリーム名、JSON化した株価データ、パーティションキーを渡します。ストリーム名は環境変数を参照して取得します。
ポイントはパーティションキーです。パーティションキーとは、配信先のシャードを決定するためのパラメータです。
パーティションキーは、ストリーム内のデータをシャード単位でグループ化するために使用されます。Kinesis Data Streams は、ストリームに属するデータレコードを複数のシャードに配分します。この際、各データレコードに関連付けられたパーティションキーを使用して、配分先のシャードを決定します。
Amazon Kinesis Data Streams の用語と概念
Kinesis Data Streamsに複数のシャードを作成した場合、配信先のシャードに偏りが発生しないようなパーティションキーを設定する必要があります。今回はハンズオンということで、後述の通り、シャード数を1に設定するため、統一的に「partitionkey」という文字列を指定します。
Kinesis Data Streamsにデータを配信するためには、kinesis:PutRecordの権限を付与する
Lambda関数用のIAMロールを定義します。
Resources:
DataSourceLambdaRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service:
- lambda.amazonaws.com
Policies:
- PolicyName: PutRecordIntoKinesisDataStream
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- kinesis:PutRecord
Resource:
- !Ref KinesisDataStreamArn
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Code language: YAML (yaml)ポイントはIAMロール内の、インラインポリシーで許可するアクションです。Kinesis Data Streamsにデータを配信するために必要な権限は「kinesis:PutRecord」です。同アクションをActionプロパティに指定します。また配信先として、Resourceプロパティに、後述のKinesis Data StreamsのストリームのARNを指定します。
Kinesis Data Streamsのスループットはシャード数で決まる
saa-04-001-kinesis.yamlでKinesis関係のリソースを定義します。まず後述のLambda関数で生成されたデータをキャプチャするKinesis Data Streamsを定義します。
Resources:
KinesisDataStream:
Type: AWS::Kinesis::Stream
Properties:
Name: KinesisDataStream
ShardCount: 1
Code language: YAML (yaml)Kinesis Data Streamsで重要なパラメータはシャードです。シャードはShardCountプロパティで設定します。シャードはKinesis Data Streamsのスループットを決定します。
シャードは、ストリーム内の一意に識別されたデータレコードのシーケンスです。ストリームは複数のシャードで構成され、各シャードが容量の 1 単位になります。各シャードは、読み取りに対して最大 5 トランザクション/秒をサポートし、最大合計データ読み取りレートは 2 MB /秒、最大合計データ読み取りレートは 1,000 レコード、最大合計データ書き込みレートは 1 秒あたり 1 MB(パーティションキーを含む)までサポートできます。ストリームのデータ容量は、ストリームに指定したシャードの数によって決まります。ストリームの総容量はシャードの容量の合計です。
Amazon Kinesis Data Streams の用語と概念
つまりシャード数を増やすことによって、Kinesis Data Streams全体のスループットを高めることができます。今回は検証ということで、先述の通り、シャード数は最小の「1」に設定します。
Kinesis Data Analytics用語
テンプレートファイルの具体的な記載内容を確認する前に、Kinesis Data Analyticsに関する用語を整理します。
Kinesis Data Analyticsで処理する対象のストリーミングデータのことを、ストリーミングソースと呼びます。今回の検証で言うと、Kinesis Data Streamsをストリーミングソースと呼びます。Kinesis Data Analyticsを起動すると、アプリケーション内ストームが生成されます。
アプリケーションを起動すると、Kinesis Data Analytics によって指定されたアプリケーション内ストリームが作成されます。この名前を使用して、アプリケーションコードでアプリケーション内ストリームにアクセスします。
アプリケーション入力の設定
つまりKinesis Data Analyticsで処理の対象とするデータは、Kinesis Data Streams等のストリーミングデータそのものではなく、Kinesis Data Analyticsが生成するアプリケーション内ストームであるということです。
1つのアプリケーション内ストームで処理できる速度には限度があります。
1 つのアプリケーション内ストリームに対して推奨される最大スループットは、アプリケーションのクエリの複雑さに応じて、2 ~ 20 MB/秒です。
Limits
それ以上の性能が必要の場合は、アプリケーション内ストームは複数作成することが可能です。
オプションで、ストリーミングリソースを複数のアプリケーション内ストリームにマッピングできます。 (中略) この場合、Amazon Kinesis Data Analytics では、次の名前で、アプリケーション内ストリームを指定された数だけ作成します。プレフィックス_001,プレフィックス_002, およびプレフィックス_003。
Limits
上記のように、アプリケーション内ストームは自動的に作成されますが、デフォルトで作成されたものに加え、手動で作成することも可能です。
必要に応じて、中間クエリ結果を保存するためにアプリケーション内ストリームをさらに作成することもできます。
アプリケーション内ストリームとポンプ
手動で作成したアプリケーション内ストームを使用するためには、デフォルトのアプリケーション内ストームから、データをポンプする必要があります。
ポンプとは、1 つのアプリケーション内ストリームから別のアプリケーション内ストリームにデータを挿入する、連続して実行される挿入クエリです。
アプリケーション内ストリームとポンプ
Kinesis Data AnalyticsはストリーミングデータをSQLでフィルタリングできる
用語がわかりましたので、実際にKinesis Data Analyticsを定義を確認します。
Resources:
KinesisDataAnalytics:
Type: AWS::KinesisAnalytics::Application
Properties:
ApplicationName: !Sub "${Prefix}-application"
ApplicationDescription: sample application.
ApplicationCode:
!Sub |
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (event_time VARCHAR(20), ticker VARCHAR(5), price REAL);
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM event_time, ticker, price
FROM "${NamePrefix}_001"
WHERE ticker = 'AAPL';
Inputs:
- NamePrefix: !Ref NamePrefix
InputSchema:
RecordColumns:
- Name: EVENT_TIME
SqlType: VARCHAR(20)
Mapping: $.EVENT_TIME
- Name: TICKER
SqlType: VARCHAR(5)
Mapping: $.TICKER
- Name: PRICE
SqlType: REAL
Mapping: $.PRICE
RecordFormat:
RecordFormatType: JSON
MappingParameters:
JSONMappingParameters:
RecordRowPath: $
KinesisStreamsInput:
ResourceARN: !GetAtt KinesisDataStream.Arn
RoleARN: !GetAtt KinesisAnalyticsRole.Arn
Code language: YAML (yaml)Inputsプロパティ内でストリーミングソースに関する設定を行います。
NamePrefixプロパティで、自動的に作成されるアプリケーション内ストリームのプレフィックスを指定します。先述の通り、ストリーム名には数字のサフィックスが付与されますので、今回作成されるストリーム名は「SAMPLE_APP_001」となります。
KinesisStreamsInputプロパティでストリーミングソースを指定します。ResourceARNプロパティに、定義済みのKinesis Data StreamsのストリームのARNを指定します。RoleARNプロパティに、同ストリームにアクセスするために必要な権限をまとめたIAMロールのARNを指定します。
RecordFormatプロパティは、ストリーミングソースから受け取るデータに関する設定を行います。RecordFormatプロパティでは受け取るデータの形式を指定します。今回の検証用のデータは、Lambda関数からJSON形式で配信されるため、「JSON」を指定します。MappingParametersプロパティでは、後述のパラメータマッピング用として、1つのデータを意味する変数を定義します。今回は、「$」で1データを示すことにします。
RecordColumnsプロパティで、ストリーミングソースから受け取るデータ内の要素と、アプリケーション内ストリーム内部のカラムのマッピングを定義します。今回は1データに3つの情報(日時、ティッカー、株価)を持っていますので、3つのプロパティでそれらを割り当てます。Nameプロパティはアプリケーション内ストリームに作成するカラムです。SqlTypeプロパティはカラムの型です。取れる型はData Typesに詳しいですが、今回は、文字列はVARCHAR、数値はREALを指定します。Mappingプロパティで、カラムが参照する元データを指定します。先述のマッピング用変数「$」を使用します。
ApplicationCodeプロパティで実行するSQLを定義します。1行目の「CREATE OR REPLACE STREAM」文で、新しいアプリケーション内ストリーム「DESTINATION_SQL_STREAM」を作成します。デフォルトのアプリケーション内ストリーム「SAMPLE_APP_001」と同様に、3カラムを定義します。2行目の「CREATE OR REPLACE PUMP」文で、ポンプを作成します。「STREAM_PUMP」という名前のポンプを作成します。ポンプでアプリケーション内ストリーム間でデータを連携します。今回は先ほど作成した「DESTINATION_SQL_STREAM」に連携するように指定します。3~5行目でポンプで連携するカラムおよび連携元を指定します。今回はFROM句で「SAMPLE_APP_001」を連携元のストリームを指定し、3カラムを「DESTINATION_SQL_STREAM」に渡すように指定します。加えてWHERE句でティッカー名が「AAPL」のデータに抽出するように指定します。
環境構築
CloudFormationを使用して、本環境を構築し、実際の挙動を確認します。
CloudFormationスタックを作成し、スタック内のリソースを確認する
CloudFormationスタックを作成します。スタックの作成および各スタックの確認方法については、以下のページをご確認ください。

各スタックのリソースを確認した結果、今回作成された主要リソースの情報は以下の通りです。
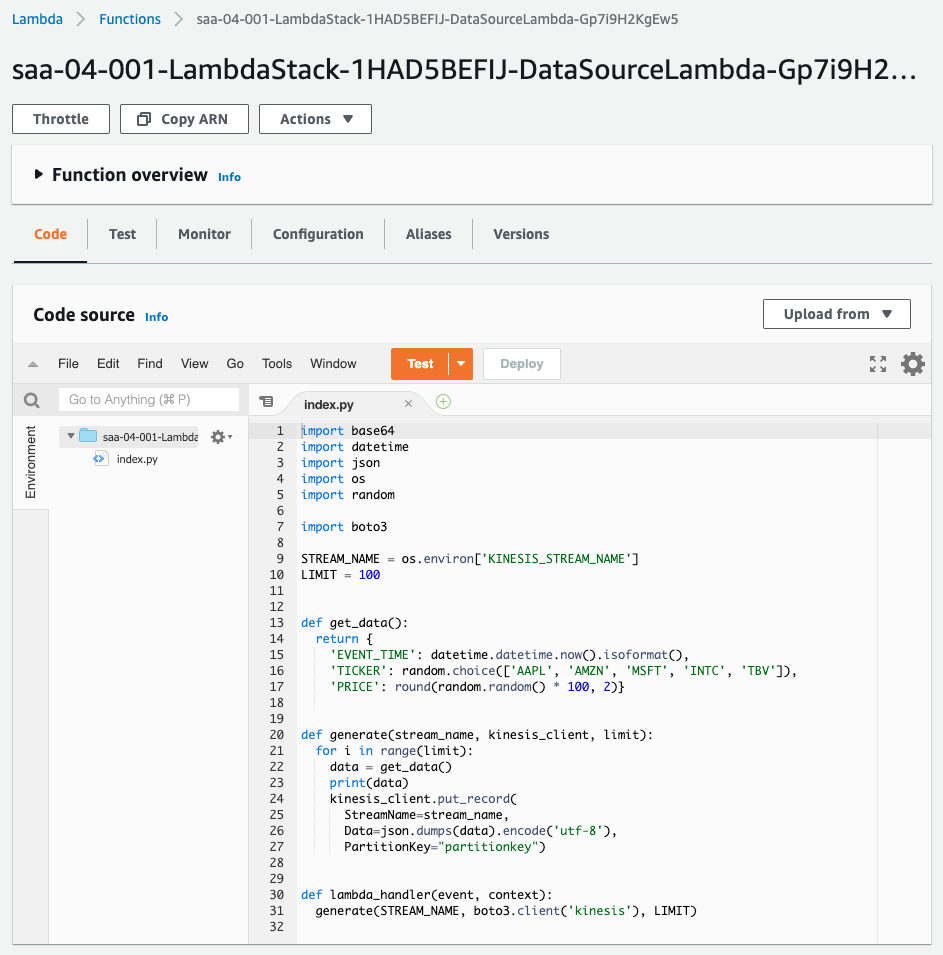
- Lambda関数:saa-04-001-LambdaStack-1HAD5BEFIJ-DataSourceLambda-Gp7i9H2KgEw5
- Kinesis Data Stream:KinesisDataStream
- Kinesis Data Analytics:saa-04-001-application
AWS Management Consoleからも、リソースの作成状況を確認します。まずLambda関数の作成状況をチェックします。
次にKinesis Data Streamを確認します。
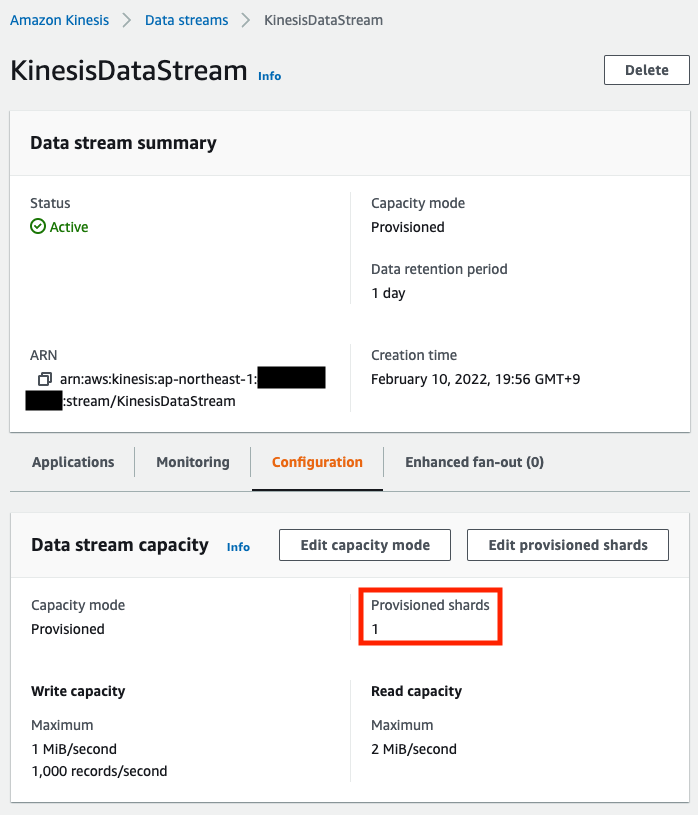
シャード数が1つの設定でストリームが作成されていますので、テンプレートファイルで指定した通りに作成されています。最後にKinesis Data Analyticsを確認します。
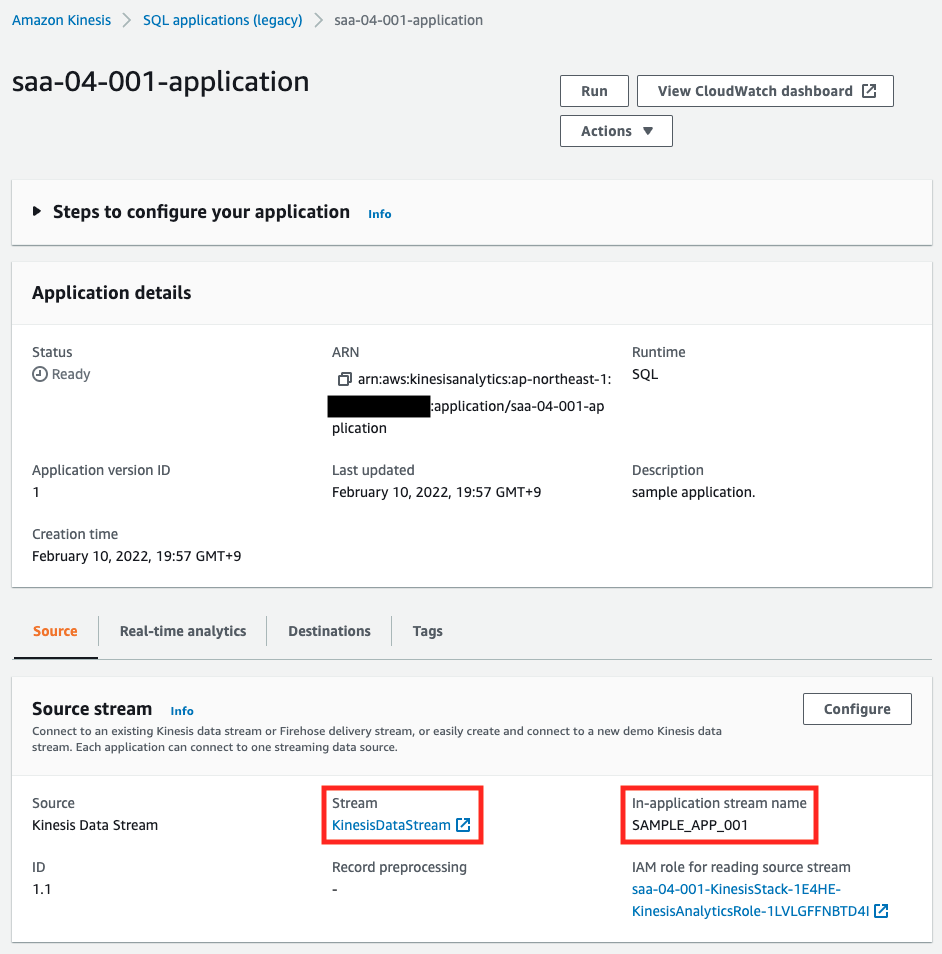
ソースが先述のストリーム、アプリケーション内ストリーム名が「SAMPLE_APP_001」であることがわかります。指定通りです。
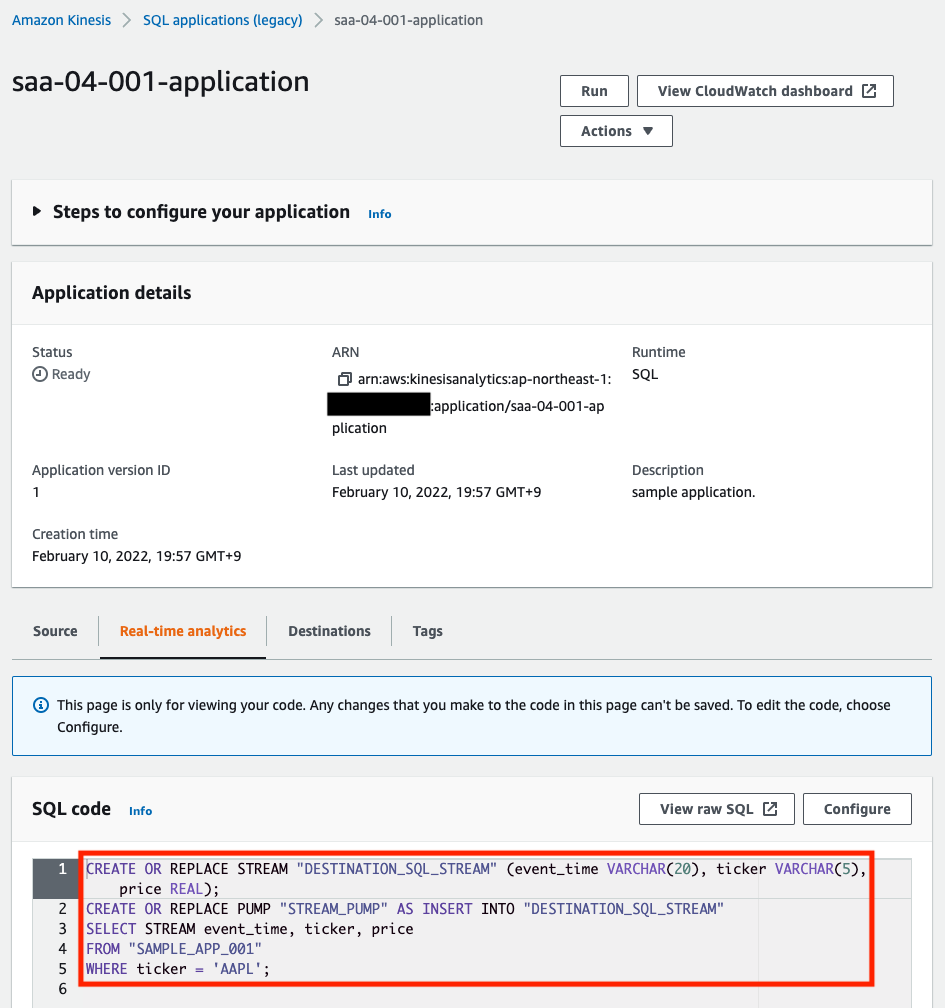
フィルタリング用のSQLも指定通りに設定されていることがわかります。
Kinesis Data Analyticsアプリを起動する
検証を始めるために、Kinesis Data Analyticsアプリケーションを起動します。起動もAWS Management Consoleから実行します。

「Run」ボタンを押下します。
確認用のポップアップが表示されますので、「Run」を押下します。
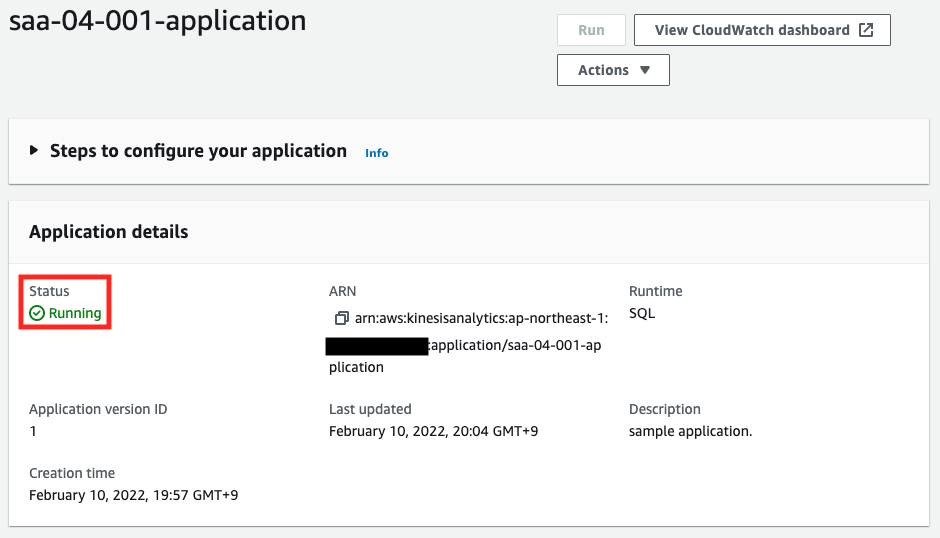
しばらく待つと、ステータスが「Running」となります。これでKinesis Data Analyticsアプリが起動しました。続いてリアルタイム分析ページにアクセスします。
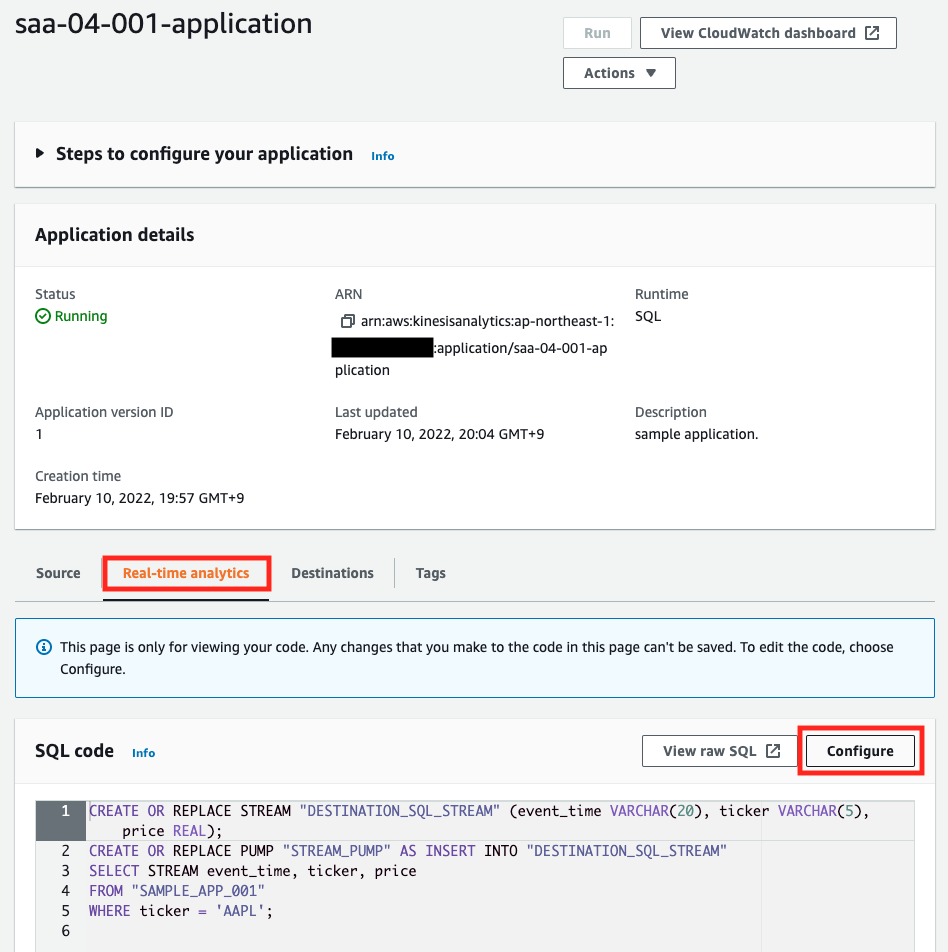
「Real-time analytics」タブの「Configure」を押下します。
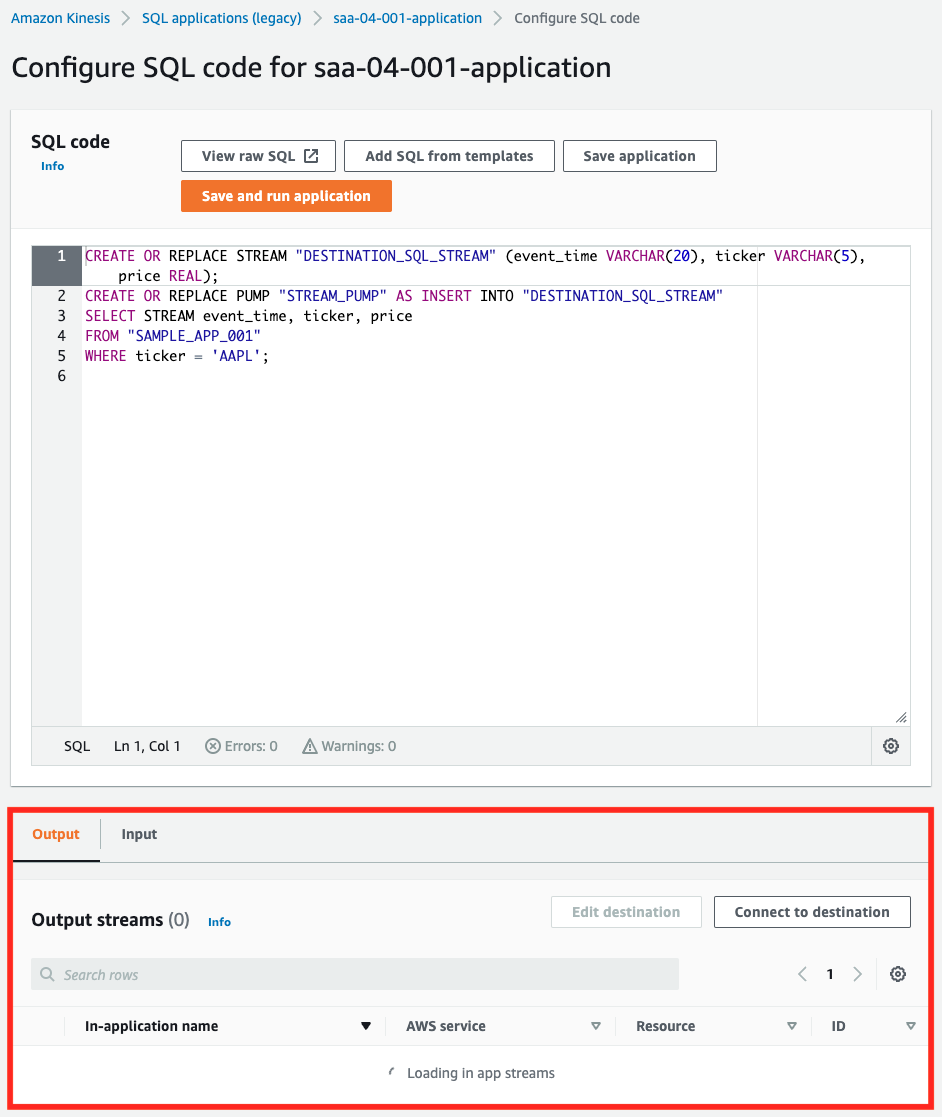
ページ下部にストリームに流れてくるデータや、SQLでフィルタした結果が表示されます。
Lambdaを実行して、検証用データをKinesis Data Streamに送信する
準備が整いましたので、検証を始めます。早速、Lambdaを実行します。
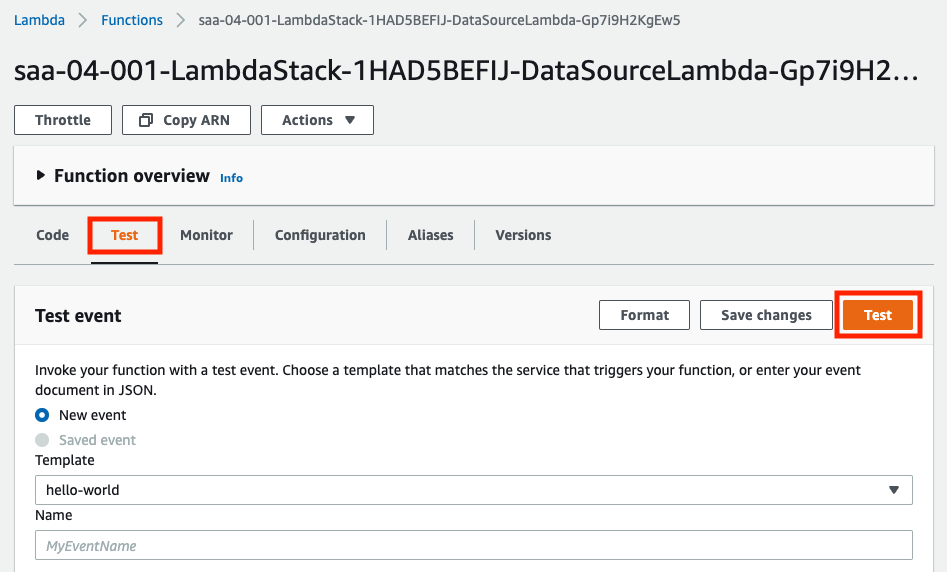
「Test」タブの「Test」を押下します。Test eventは何でも構いません。今回はデフォルトの「hello-world」を選択して実行しました。実行直後に、先ほどのKinesis Data Analyticsのリアルタイム分析ページを確認します。
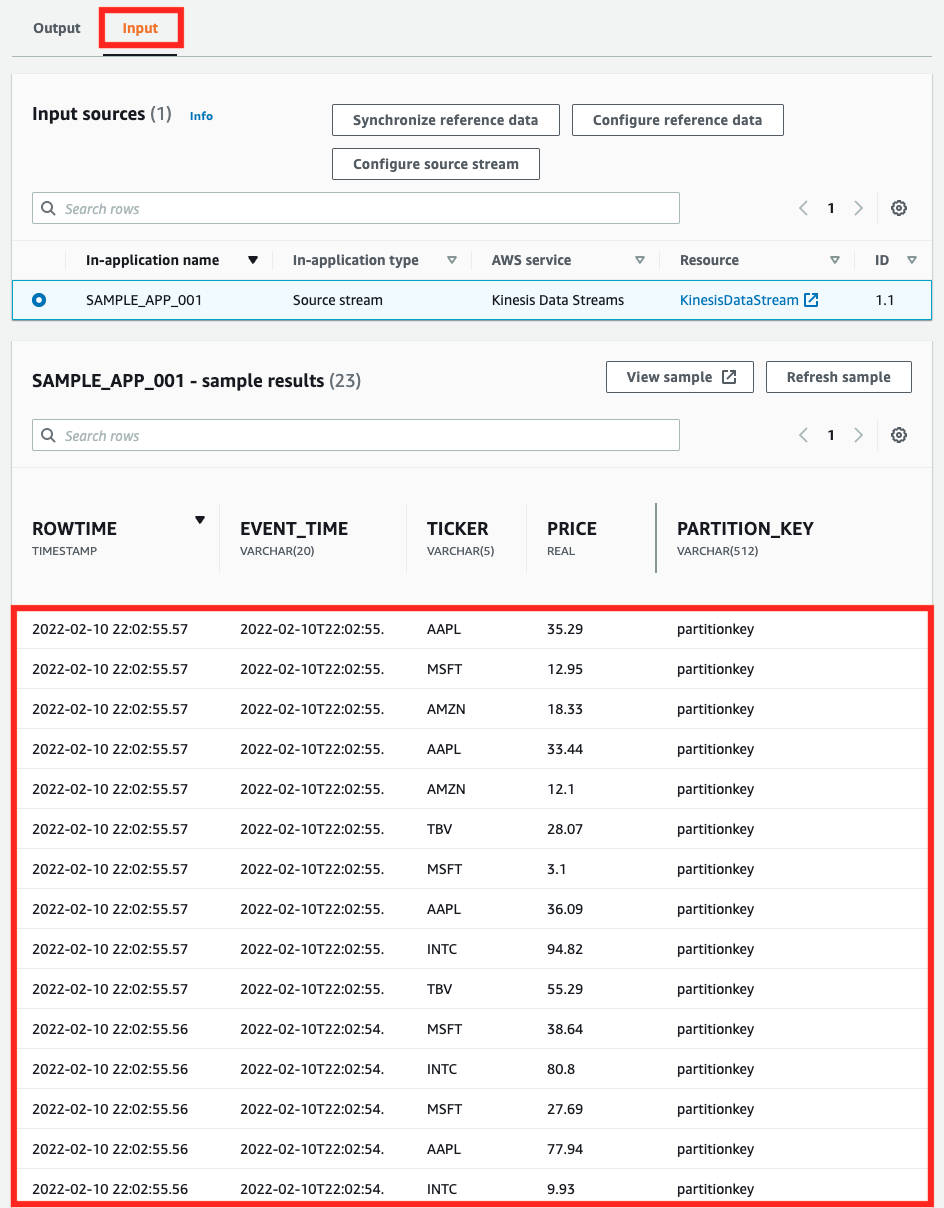
「Input」タブでは、Lambdaから送信されたテストデータを確認することができました。続いて「Output」タブも確認します。「Output」タブを選択後、もう一度Lambda関数を実行します。
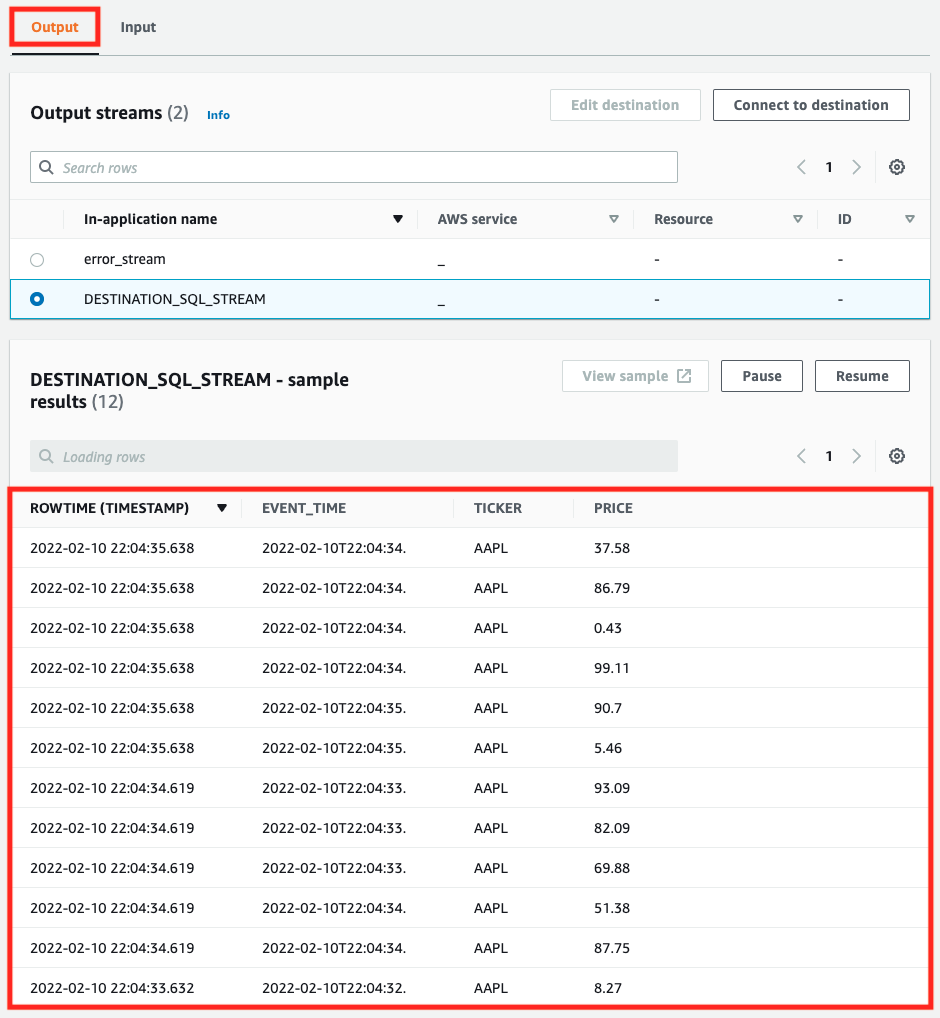
こちらのタブでは、SQLでフィルタした結果が表示されました。ティッカーの値が「AAPL」のデータのみが抽出されていることがわかります。
まとめ
Kinesisサービスを2つ使用し、ストリーミングデータを扱いました。
Lambda関数で生成したテスト用のストリーミングデータを、Kinesis Data Streamsに配信しました。
配信されたデータをKinesis Data Analyticsで受け付け、SQLベースでリアルタイムに処理できることを確認しました。