AppSyncのデータソースにOpenSearchを設定する
AppSyncは以下のサービスの中からデータソースを選択することができます。
- Lambda
- DynamoDB
- OpenSearch
- None
- HTTPエンドポイント
- RDS
今回はLambdaをデータソースにする構成を確認します。
なおAppSyncの基本的な解説と、DynamoDBをデータソースとする構成については、以下のページをご確認ください。

構築する環境

データソースとして動作するOpenSearchを作成します。
OpenSearchドメインに、AWS公式で公開されている映画データを格納します。
AppSyncでこのOpenSearchドメインを操作するために、スキーマ・リゾルバを定義します。
AWS公式で紹介されているサンプルを参考にして、以下のクエリ・ミューテーションを定義します。
https://docs.aws.amazon.com/ja_jp/appsync/latest/devguide/tutorial-elasticsearch-resolvers.html
- listMovies:保存されている全映画データを取得する。
- getMovie:IDを指定して映画データを取得する。
- getMovieByActor:出演者名を指定して映画データを取得する。
- addMovie:映画データを追加する。
2つのLambda関数を作成します。
関数のランタイム環境はPython3.8とします。
1つ目の関数はカスタムリソースに関連付けて、スタック作成時に実行されるように設定します。
この関数の働きは、OpenSearchドメインにJSONファイルをアップロードすることです。
先述のデータをJSONファイルという形でS3バケットに保存し、これをドメインにアップロードします。
2つ目の関数はGraphQL APIを実行するクライアントとして設定します。
Function URLを有効化し、URLクエリパラメータで実行する操作を指定できるようにします。
CloudFormationテンプレートファイル
上記の構成をCloudFormationで構築します。
以下のURLにCloudFormationテンプレートを配置しています。
https://github.com/awstut-an-r/awstut-fa/tree/main/056
テンプレートファイルのポイント解説
データソース
Resources:
DataSource:
Type: AWS::AppSync::DataSource
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
Name: DataSource
OpenSearchServiceConfig:
AwsRegion: !Ref AWS::Region
Endpoint: !Sub "https://${DomainEndpoint}"
ServiceRoleArn: !Ref DataSourceRoleArn
Type: AMAZON_OPENSEARCH_SERVICE
Code language: YAML (yaml)ポイントはTypeプロパティです。
OpenSearchをデータソースとする場合は、「AMAZON_OPENSEARCH_SERVICE」を指定します。
またOpenSearchServiceConfigプロパティで詳細を設定します。
ドメインのエンドポイント等を設定します。
データソース用IAMロール
Resources:
DataSourceRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service: appsync.amazonaws.com
Policies:
- PolicyName: !Sub "${Prefix}-DataSourcePolicy"
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- es:ESHttpDelete
- es:ESHttpHead
- es:ESHttpGet
- es:ESHttpPost
- es:ESHttpPut
Resource:
- !Sub "arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${DomainName}/*"
Code language: YAML (yaml)データソースにOpenSearchを指定するため、AppSyncがOpenSearchにアクセスできる権限を与えます。
スキーマ
Resources:
GraphQLSchema:
Type: AWS::AppSync::GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
Definition: |
schema {
query: Query
mutation: Mutation
}
type Query {
listMovies: [Movie]
getMovie(_id: ID!): Movie
getMovieByActor(actor: String!): [Movie]
}
type Mutation {
addMovie(director: String, genre: [String], year: Int, actor: [String], title: String): Movie
}
type Movie {
_id: ID!
director: String
genre: [String]
year: Int
actor: [String]
title: String
}
Code language: YAML (yaml)冒頭で取り上げたAWS公式ページを参考にスキーマを定義します。
リゾルバ
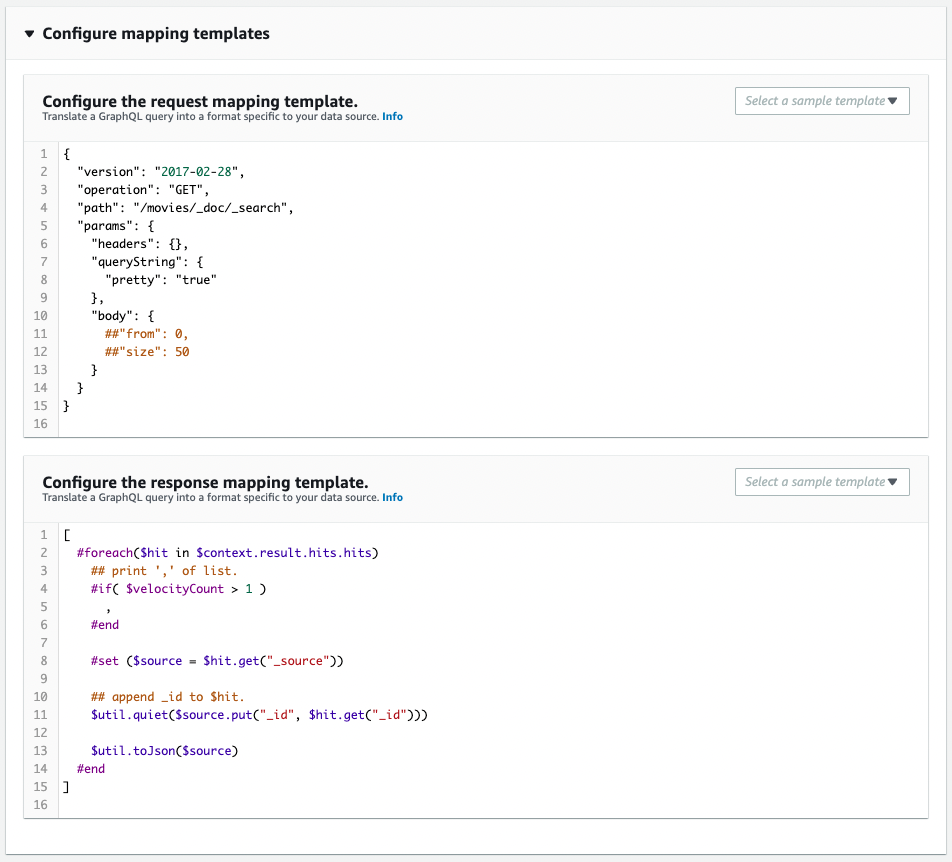
listMoviesクエリ用リゾルバ
OpenSearchドメインに保存されている全データを取得するためのリゾルバです。
Resources:
ListMoviesResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: listMovies
Kind: UNIT
RequestMappingTemplate: !Sub |
{
"version": "2017-02-28",
"operation": "GET",
"path": "/${IndexName}/_doc/_search",
"params": {
"headers": {},
"queryString": {
"pretty": "true"
},
"body": {}
}
}
ResponseMappingTemplate: |
[
#foreach($hit in $context.result.hits.hits)
## print ',' of list.
#if( $velocityCount > 1 )
,
#end
#set ($source = $hit.get("_source"))
## append _id to $hit.
$util.quiet($source.put("_id", $hit.get("_id")))
$util.toJson($source)
#end
]
TypeName: Query
Code language: YAML (yaml)ポイントはリゾルバのリクエストマッピングとレスポンスマッピングの設定です。
AppSyncをデータソースとする場合のマッピングの設定は以下のページに詳しいです。
まずリクエストマッピング(RequestMappingTemplateプロパティ)を確認します。
operationフィールドはOpenSearchドメインに対して実行する操作を指定します。本リゾルバはデータを取得するクエリ用ですので、「GET」を指定します。
pathフィールドは、OpenSearchドメインに対して処理を実行するエンドポイントを指定します。検索を実行する場合、以下のPATHを指定します。
/[index name]/_doc/_search
今回はCloudFormationの組み込み関数Fn::Subを使用して、インデックス名を埋め込みます。
bodyフィールドで検索条件を設定することができます。このマッピングは全データを取得するクエリ用ですので、何も設定を行いません。
次にレスポンスマッピング(ResponseMappingTemplateプロパティ)を確認します。
本プロパティの最初の行に「[」、最後の行に「]」を記述します。これでレスポンスマッピングの戻り値として、リストオブジェクトを返すということになります。
$context.result.hits.hitsで検索結果にアクセスすることができます。このオブジェクトはリスト型でして、#foreachを使用してループ処理を行うことができます。
#setで変数を定義できます。$hit._sourceに格納されている検索結果をsourceという変数に格納します。
putメソッドを使って、sourceに_idというデータを追加します。その際に、$util.quietを使用します。これはputメソッドの動作によって、戻り値に影響が出ないようにするための対応です。
$util.toJsonで変数sourceの中身をJSON化した上で出力します。これが戻り値となります。
先述の通り、戻り値はリストオブジェクトです。そのためループ処理の2周目以降は、1周前の値との間に区切り文字「,」が必要となります。ですから#ifで$velocityCount、つまりループ回数の値を確認し、2周目以降は「,」を出力するように設定します。
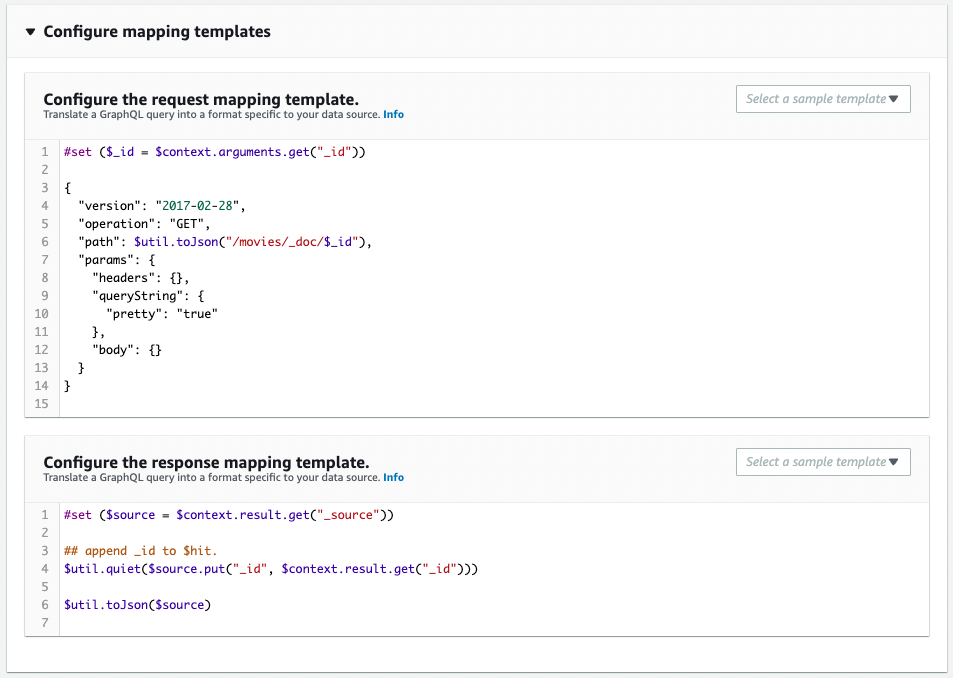
getMovieクエリ用リゾルバ
IDを指定して、特定の映画データを取得するためのリゾルバです。
Resources:
GetMovieResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: getMovie
Kind: UNIT
RequestMappingTemplate: !Sub |
#set ($_id = $context.arguments.get("_id"))
{
"version": "2017-02-28",
"operation": "GET",
"path": $util.toJson("/${IndexName}/_doc/$_id"),
"params": {
"headers": {},
"queryString": {
"pretty": "true"
},
"body": {}
}
}
ResponseMappingTemplate: |
#set ($source = $context.result.get("_source"))
## append _id.
$util.quiet($source.put("_id", $context.result.get("_id")))
$util.toJson($source)
TypeName: Query
Code language: YAML (yaml)こちらもリクエストマッピングとレスポンスマッピングがポイントです。
まずリクエストマッピングを確認します。
$context.argumentsにGraphQLの引数が格納されています。今回は引数_idを同名の変数に格納します。
pathフィールドですが、IDを指定して検索をかける場合、本フィールドに以下のURLを指定します。
/[index name]/_doc/[id]
インデックス名は組み込み関数Fn::Subを使用して埋め込みます。
IDは先述のGraphQLの引数の値を使用します。
次にレスポンスマッピングを確認します。
IDを指定して検索をかける場合、$context.result._sourceに検索結果が格納されています。
後の流れは先ほどのリゾルバと同様でして、IDデータを追加した上でJSON化して出力し、戻り値を作成します。
getMovieByActorクエリ用リゾルバ
出演者の名前から映画データを検索するためのリゾルバです。
Resources:
GetMovieByActorResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: getMovieByActor
Kind: UNIT
RequestMappingTemplate: !Sub |
#set ($actor = $context.arguments.get("actor"))
{
"version": "2017-02-28",
"operation": "GET",
"path": "/${IndexName}/_doc/_search",
"params": {
"headers": {},
"queryString": {
"pretty": "true"
},
"body": {
"query": {
"match": {
"actor": $util.toJson($actor)
}
}
}
}
}
ResponseMappingTemplate: |
[
#foreach($hit in $context.result.hits.hits)
## print ',' of list.
#if( $velocityCount > 1 )
,
#end
#set ($source = $hit.get("_source"))
## append _id to $hit.
$util.quiet($source.put("_id", $hit.get("_id")))
$util.toJson($source)
#end
]
TypeName: Query
Code language: YAML (yaml)リクエストマッピングがポイントです。
bodyフィールド内のqueryで検索条件を設定します。出演者名で検索を行いますので、matchクエリに出演者名を設定します。
レスポンスマッピングは1つ目のリゾルバと同様です。
検索結果をループ処理して戻り値を作成します。
addMovieミューテーション用リゾルバ
映画データを追加するためのリゾルバです。
Resources:
AddMovieResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: addMovie
Kind: UNIT
RequestMappingTemplate: !Sub |
#set ($_id = $util.autoId())
#set ($director = $context.arguments.director)
#set ($genre = $context.arguments.genre)
#set ($year = $context.arguments.year)
#set ($actor = $context.arguments.actor)
#set ($title = $context.arguments.title)
{
"version": "2017-02-28",
"operation": "PUT",
"path": $util.toJson("/${IndexName}/_doc/$_id"),
"params": {
"headers": {},
"queryString": {
"pretty": "true"
},
"body": {
"director": $util.toJson($director),
"genre": $util.toJson($genre),
"year": $util.toJson($year),
"actor": $util.toJson($actor),
"title": $util.toJson($title)
}
}
}
ResponseMappingTemplate: |
#set ($source = $context.result.get("_source"))
## append _id to $hit.
$util.quiet($source.put("_id", $context.result.get("_id")))
$util.toJson($source)
TypeName: Mutation
Code language: YAML (yaml)リクエストマッピングがポイントです。
映画データを構成する6つの値を準備します。5つはGraphQLの引数を使用します。IDに関しては、$util.autoId()で自動生成したIDを使用します。
operationフィールドは「PUT」を指定します。データを追加するためです。
pathフィールドはIDベースで検索する場合と同様です。
bodyフィールドにIDを除く5つのデータを指定します。
リクエストマッピングは2つ目のリゾルバと同様です。
IDデータを追加して戻り値を作成します。
(参考) OpenSearch
OpenSearchに関する基本的な事項は、以下のページをご確認ください。

本ページでは、OpenSearchをAppSyncのデータソースとする上でのポイントを取り上げます。
Resources:
Domain:
Type: AWS::OpenSearchService::Domain
Properties:
AccessPolicies:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
AWS:
- !Ref DataSourceRoleArn
- !Ref FunctionRole2Arn
Action:
- es:ESHttpDelete
- es:ESHttpHead
- es:ESHttpGet
- es:ESHttpPost
- es:ESHttpPut
Resource: !Sub "arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${DomainName}/*"
#AdvancedSecurityOptions:
# Enabled: true
# InternalUserDatabaseEnabled: true
# MasterUserOptions:
# MasterUserName: !Ref MasterUserName
# MasterUserPassword: !Ref MasterUserPassword
ClusterConfig:
DedicatedMasterEnabled: false
InstanceCount: !Ref InstanceCount
InstanceType: !Ref InstanceType
WarmEnabled: false
ZoneAwarenessEnabled: false
CognitoOptions:
Enabled: false
DomainEndpointOptions:
CustomEndpointEnabled: false
EnforceHTTPS: true
TLSSecurityPolicy: Policy-Min-TLS-1-0-2019-07
DomainName: !Ref DomainName
EBSOptions:
EBSEnabled: true
VolumeSize: !Ref VolumeSize
VolumeType: gp2
EncryptionAtRestOptions:
Enabled: true
KmsKeyId: !Ref Key
EngineVersion: !Ref EngineVersion
NodeToNodeEncryptionOptions:
Enabled: true
Code language: YAML (yaml)AccessPoliciesプロパティがポイントです。
本プロパティはドメインアクセスポリシーと呼ばれるセキュリティレイヤーに対応する項目でして、ドメインへのアクセスを許可する対象をIAMポリシー形式で設定します。
今回は先述のAppSyncに適用したIAMロールと、後述のデータ投入用Lambda関数のIAMロールを指定します。
本プロパティに関連して、2つ注意点があります。
1点目はプリンシパル設定です。
今回のようにIAM認証情報を使ってアクセス許可を与える場合、ワイルドカードを使った全リソースを指定するような記述は認められません。
先述の通り、IAMロールなどの具体的なリソースを指定する必要があります。
2点目はFGAC(Fine-grained access control)を使用したマスターユーザーによる認証についてです。
本節の冒頭でご紹介したページでは、マスターユーザーによる認証を有効化した構成をご紹介しました。
ただし今回のようにIAM認証情報を使ってアクセス許可を与える場合、以下に引用した通り、マスターユーザーによる認証は不可能ですのでご注意ください。
リソースベースのアクセスポリシーに IAM ユーザーまたはロールが含まれる場合、クライアントは AWS 署名バージョン 4 を使用して署名付きリクエストを送信する必要があります。そのため、アクセスポリシーは、特に内部ユーザーデータベースと HTTP 基本認証を使用する場合、きめ細かなアクセスコントロールと競合することがあります。ユーザー名とパスワードで、かつ IAM 認証情報で、リクエストに署名することはできません。
Amazon OpenSearch Service のきめ細かなアクセスコントロール
(参考) GraphQLクライアントLambda関数
import json
import os
import time
from gql import Client, gql
from gql.transport.aiohttp import AIOHTTPTransport
api_key = os.environ['API_KEY']
graphql_url = os.environ['GRAPHQL_URL']
transport = AIOHTTPTransport(
url=graphql_url,
headers={
'x-api-key': api_key
})
client = Client(transport=transport, fetch_schema_from_transport=True)
LIST = 'List'
GET = 'Get'
ACTOR = 'Actor'
ADD = 'Add'
def lambda_handler(event, context):
operation = ''
document = None
result = None
if not 'queryStringParameters' in event or (
not 'operation' in event['queryStringParameters']):
operation = LIST
else:
operation = event['queryStringParameters']['operation']
if operation == LIST:
document = gql(
"""
query ListMovies {
listMovies {
_id
title
}
}
"""
)
result = client.execute(document)
elif operation == GET:
document = gql(
"""
query GetMovie($_id: ID!) {
getMovie(_id: $_id) {
_id
director
genre
year
actor
title
}
}
"""
)
_id = event['queryStringParameters']['_id']
params = {
'_id': _id
}
result = client.execute(document, variable_values=params)
elif operation == ACTOR:
document = gql(
"""
query GetMovieByActor($actor: String!) {
getMovieByActor(actor: $actor) {
_id
actor
title
}
}
"""
)
actor = event['queryStringParameters']['actor']
params = {
'actor': actor
}
result = client.execute(document, variable_values=params)
elif operation == ADD:
document = gql(
"""
mutation AddMovie($director: String, $genre: [String], $year: Int, $actor: [String], $title: String) {
addMovie(director: $director, genre: $genre, year: $year, actor: $actor, title: $title) {
_id
director
genre
year
actor
title
}
}
"""
)
director = event['queryStringParameters']['director']
genre = event['queryStringParameters']['genre'].split(',')
year = int(event['queryStringParameters']['year'])
actor = event['queryStringParameters']['actor'].split(',')
title = event['queryStringParameters']['title']
params = {
'director': director,
'genre': genre,
'year': year,
'actor': actor,
'title': title
}
result = client.execute(document, variable_values=params)
return {
'statusCode': 200,
'body': json.dumps(result, indent=2)
}
Code language: Python (python)GraphQLクエリを実行するLambda関数です。
今回はPython用GraphQLクライアントライブラリとして、GQLを使用します。
https://github.com/graphql-python/gql
GQLを使って、スキーマで定義したクエリ・ミューテーションを実行します。
Pythonの場合、event[‘queryStringParameters’]でURLクエリパラメータを取得することがきます。
URLクエリパラメータで必要なパラメータを渡します。
operationパラメータで実行するGraphQLクエリを指定する形となります。
(参考) CloudFormationカスタムリソース用Lambda関数
カスタムリソースを使って、OpenSearchドメインを作成時に、自動的にS3バケットに設置されているJSONファイルをアップロードして、インデックスを作成する方法については、以下のページをご確認ください。

本ページでは、上記ページと異なる点を取り上げます。
まず関数用のIAMロールを確認します。
Resources:
FunctionRole2:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service:
- lambda.amazonaws.com
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Policies:
- PolicyName: !Sub "${Prefix}-CustomResourceFunctionPolicy"
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- s3:GetObject
Resource:
- !Sub "arn:aws:s3:::${BulkS3Bucket}/*"
- Effect: Allow
Action:
- es:ESHttpDelete
- es:ESHttpHead
- es:ESHttpGet
- es:ESHttpPost
- es:ESHttpPut
Resource:
- !Sub "arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${DomainName}/*"
Code language: YAML (yaml)JSONファイルが格納されているS3バケットへのアクセスと、OpenSearchに対するアクセスを許可する内容となっています。
特に後者はAppSync用のIAMロールと同様です。
次にLambda関数のコードを確認します。
import boto3
import cfnresponse
import json
import os
import requests
from requests.auth import HTTPBasicAuth
from requests_aws4auth import AWS4Auth
BULK_ENDPOINT = os.environ['BULK_ENDPOINT']
BULK_S3_BUCKET = os.environ['BULK_S3_BUCKET']
BULK_S3_KEY = os.environ['BULK_S3_KEY']
REGION = os.environ['REGION']
CREATE = 'Create'
response_data = {}
s3_client = boto3.client('s3')
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(
region=REGION,
service='es',
refreshable_credentials=credentials
)
def lambda_handler(event, context):
try:
if event['RequestType'] == CREATE:
s3_response = s3_client.get_object(
Bucket=BULK_S3_BUCKET,
Key=BULK_S3_KEY)
# binary
bulk = s3_response['Body'].read()
print(bulk)
requests_response = requests.post(
BULK_ENDPOINT,
data=bulk,
auth=awsauth,
headers={'Content-Type': 'application/json'}
)
print(requests_response.text)
cfnresponse.send(event, context, cfnresponse.SUCCESS, response_data)
except Exception as e:
print(e)
cfnresponse.send(event, context, cfnresponse.FAILED, response_data)
Code language: Python (python)OpenSearchの節で確認した通り、ドメインへのアクセスはIAM認証情報を使用します。
今回はrequestsを使ってHTTPリクエストを生成し、JSONファイルをドメインにアップロードする処理を実装します。
つまりこのHTTPリクエストにAWS 署名バージョン 4 を使用して署名付きリクエストとする必要があります。
そのためrequests_aws4authを使用します。
詳細は以下のページをご確認いただきたいですが、先述のIAMロールの認証情報を使って、HTTPリクエストに署名して対応します。
https://pypi.org/project/requests-aws4auth/
環境構築
CloudFormationを使用して、本環境を構築し、実際の挙動を確認します。
事前準備
以下のページを参考に、3つの準備を行います。
- OpenSearchドメインにアップロードするドキュメントを用意する
- Lambda関数用のデプロイパッケージを用意する
- Lambdaレイヤー用のデプロイパッケージを用意する
なおLambdaレイヤー用パッケージを作成ためのコマンドは以下となります。
sudo pip3 install requests -t python
sudo pip3 install requests-aws4auth -t python
sudo pip3 install --pre gql[all] -t python
[cfnresponse.py]
zip -r layer.zip python
Code language: Bash (bash)加えてcfnresponseモジュールもLambdaレイヤーに含めることとします。
cfnresponseに関しては、以下の公式ページをご確認ください。
CloudFormationスタックを作成し、スタック内のリソースを確認する
AWS CLIを使ってCloudFormationスタックを作成します。
今回の構成は複数のテンプレートファイルに分割して構成されていますが、これらを任意のバケットに設置します。
以下は任意のS3バケットに配置したテンプレートファイルを参照して、スタックを作成する例です。
なおスタック名は「fa-056」、バケット名は「awstut-bucket」、ファイルを設置しているフォルダ名は「fa-056」とします。
$ aws cloudformation create-stack \
--stack-name fa-056 \
--template-url https://awstut-bucket.s3.ap-northeast-1.amazonaws.com/fa-056/fa-056.yaml \
--capabilities CAPABILITY_IAM
Code language: Bash (bash)
各スタックのリソースを確認した結果、今回作成された主要リソースの情報は以下の通りです。
- AppSync API:fa-056-GraphQLApi
- OpenSearchドメイン名:fa-056
- OpenSearchドメインエンドポイントURL:https://search-fa-056-3grntiuisivzu6h6oy7nowjgze.ap-northeast-1.es.amazonaws.com
- GraphQLクライアントLambda関数のFunction URL:https://42rvtqzk4lna3b5xaruvsoiv240wnuwy.lambda-url.ap-northeast-1.on.aws/
AWS Management ConsoleからAppSyncを確認します。
まずデータソースです。
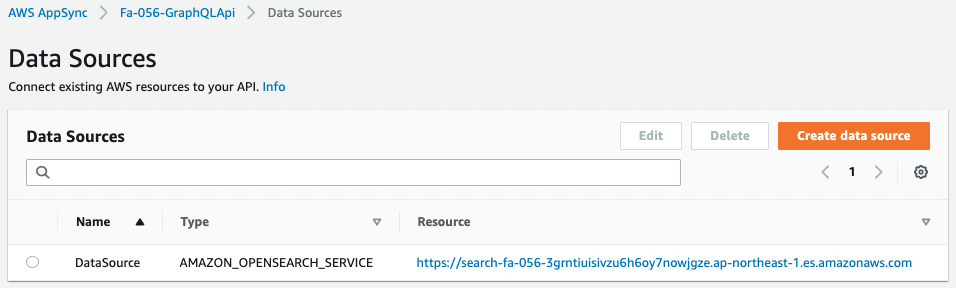
データソースを見ると、Typeが「AMAZON_OPENSEARCH_SERVICE」とあります。
次にスキーマ・リゾルバを確認します。
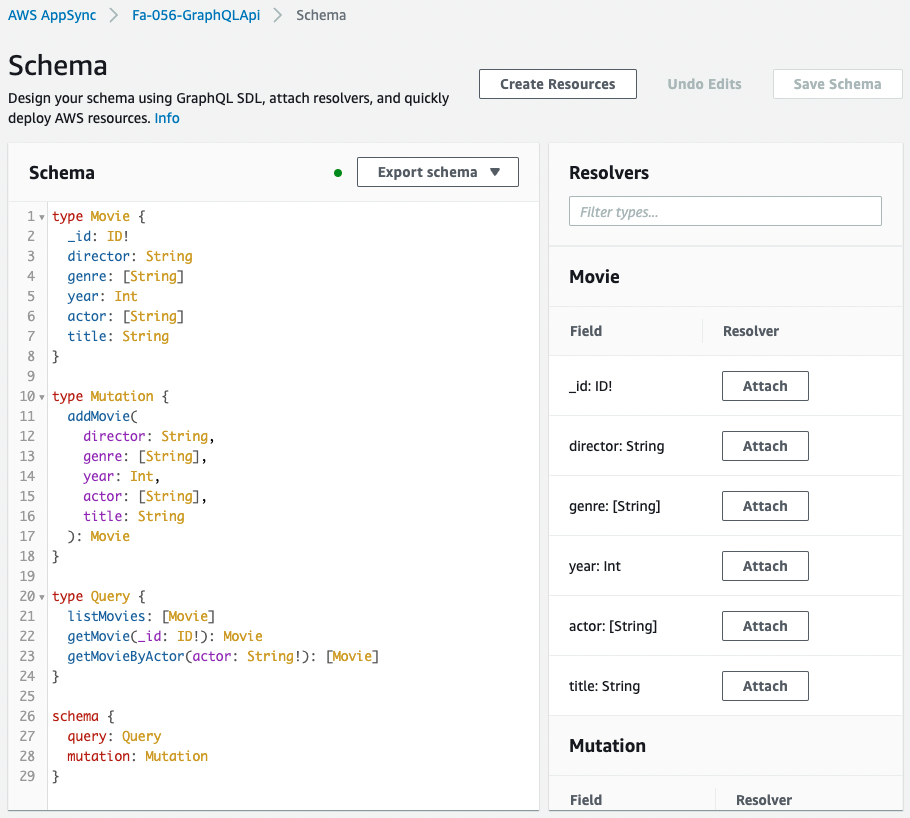
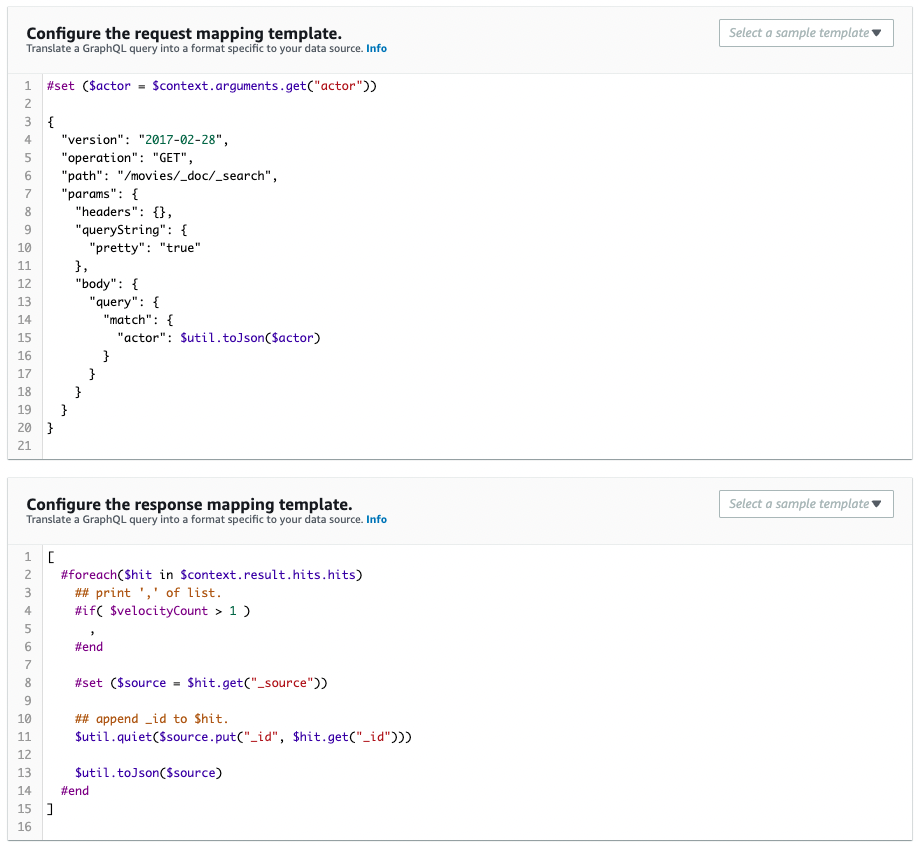
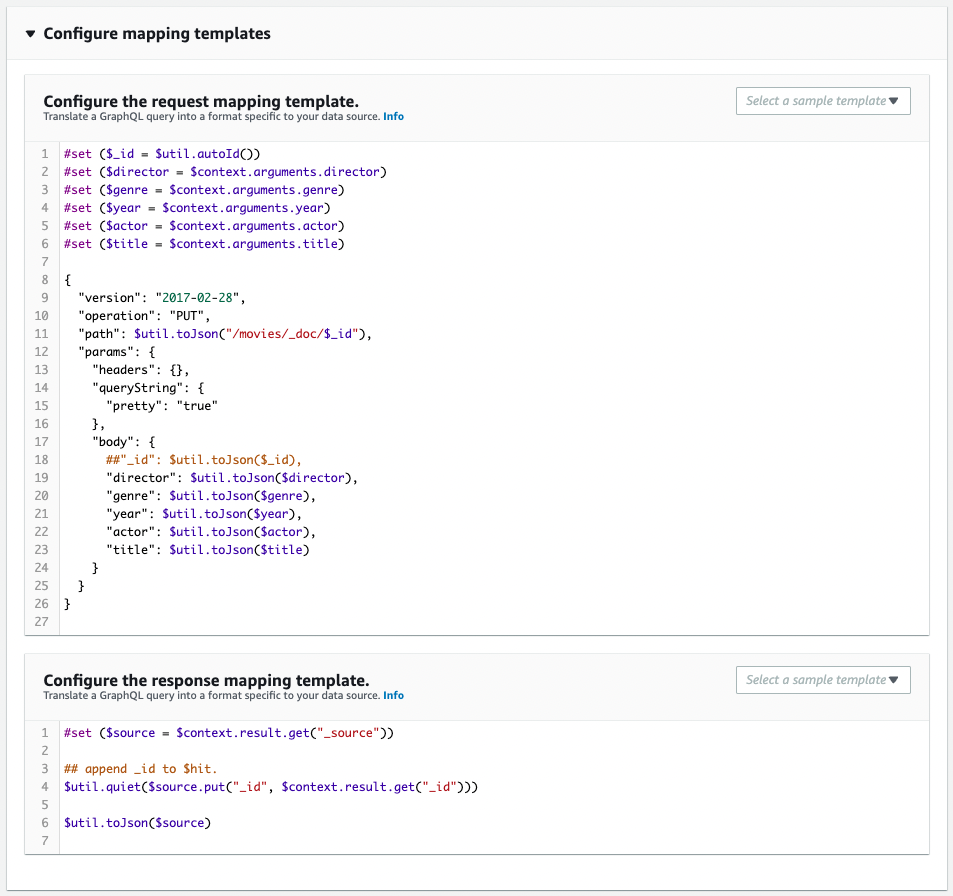
CloudFormationテンプレートファイルで定義した通りに作成されています。
続いてOpenSearchを確認します。
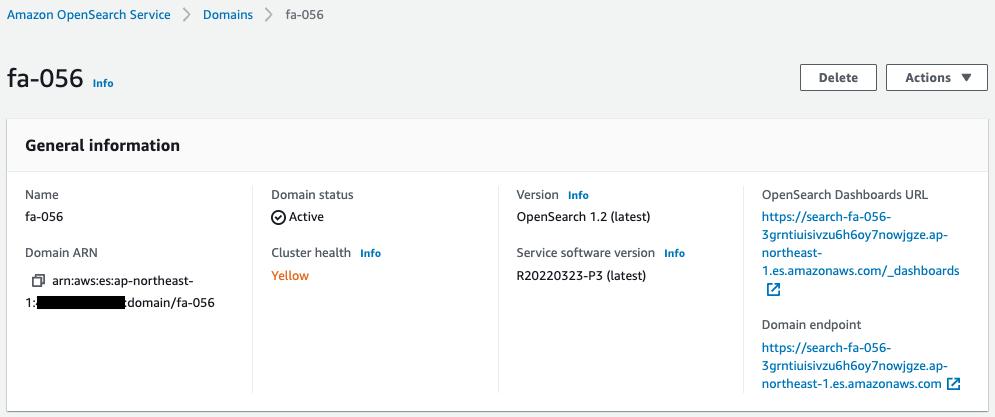
こちらも正常に作成されています。
動作確認
準備が整いましたので、GraphQLクライアントLambda関数のFunction URLにアクセスします。
listMovies
まず保存されている全データを取得します。
URLクエリのoperationの値に「List」を指定します。
これで以下のGraphQLクエリを実行することになります。
query ListMovies {
listMovies {
_id
title
}
}
Code language: plaintext (plaintext)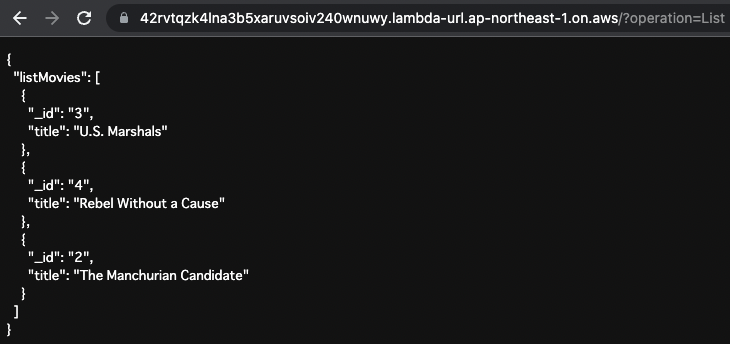
保存されている全データの_idとtitleが返ってきました。
getMovie
次にIDを指定してデータを取得します。
URLクエリのoperationの値に「Get」を、_idに「3」を指定します。
これで以下のGraphQLクエリを実行することになります。
query GetMovie($_id: ID!) {
getMovie(_id: $_id) {
_id
director
genre
year
actor
title
}
}
Code language: plaintext (plaintext)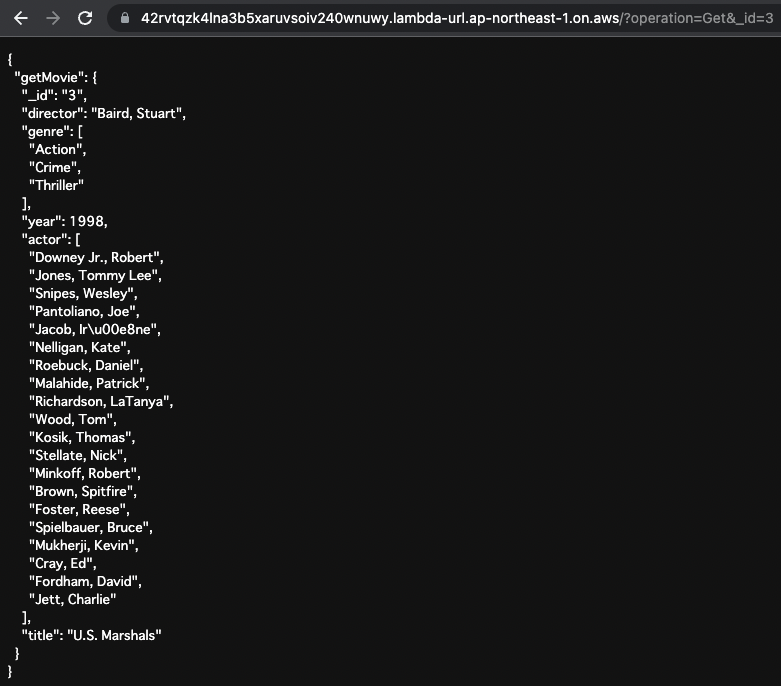
IDが「3」の動画データが返ってきました。
getMovieByActor
次に出演者の名前を指定してデータを取得します。
URLクエリのoperationの値に「Actor」を、actorに「Jr.」を指定します。
これで以下のGraphQLクエリを実行することになります。
query GetMovieByActor($actor: String!) {
getMovieByActor(actor: $actor) {
_id
actor
title
}
}
Code language: plaintext (plaintext)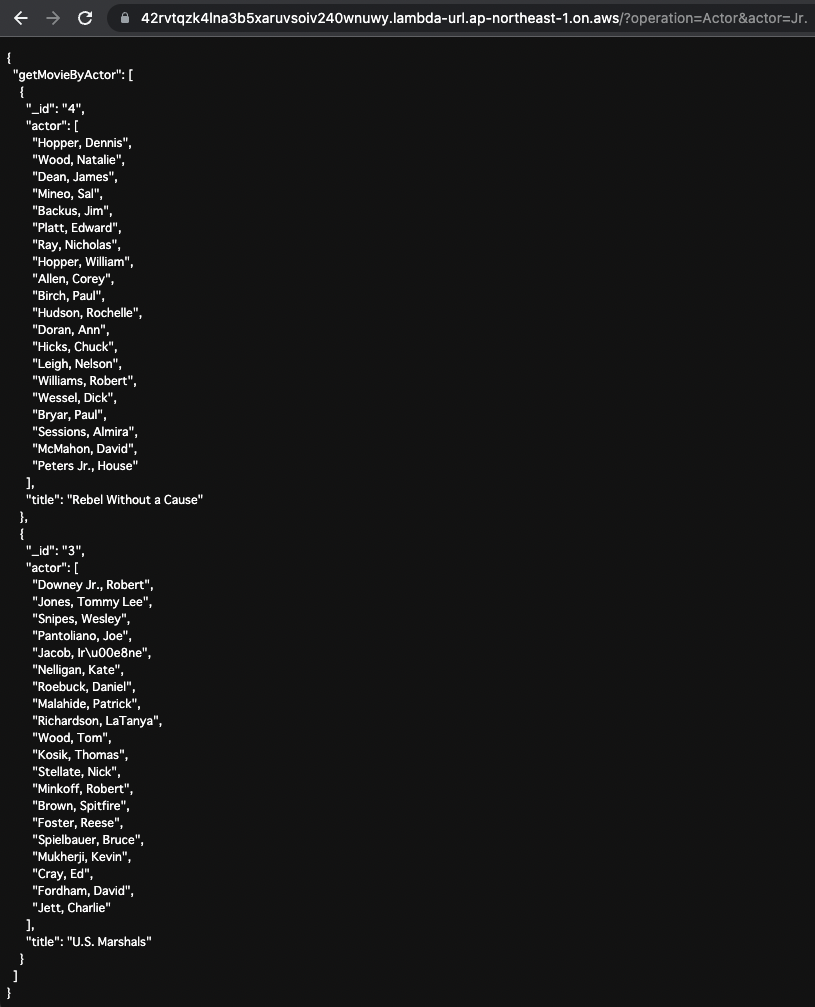
出演者名に「Jr.」が含まれる映画データが返ってきました。
AddMovie
最後に新規で動画データを保存します。
以下の通りにURLクエリを設定します。
- operation:Add
- director:hoge
- genre:aaa,bbb
- year:2022
- actor:XXX,YYY,ZZZ
- title:foo
これで以下のGraphQLミューテーションを実行することになります。
mutation AddMovie($director: String, $genre: [String], $year: Int, $actor: [String], $title: String) {
addMovie(director: $director, genre: $genre, year: $year, actor: $actor, title: $title) {
_id
director
genre
year
actor
title
}
}
Code language: plaintext (plaintext)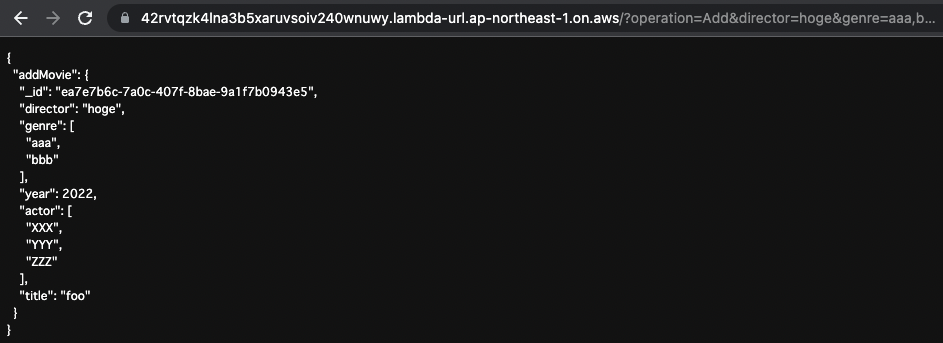
指定した通りに動画データが保存されました。
_idに関しては、自動で生成された値が使用されています。
改めてIDを指定し、保存されたデータを確認します。
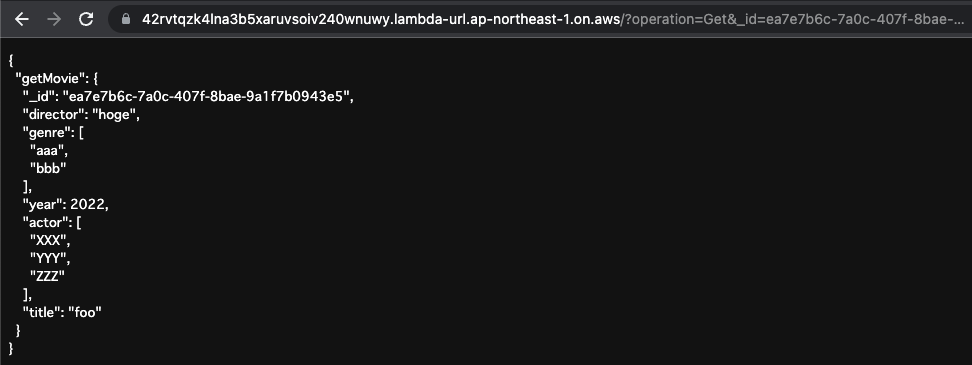
正常にデータが返ってきました。
まとめ
AppSyncのデータソースにOpenSearchを設定する構成をご紹介しました。