AppSyncのデータソースにRDS(Aurora Serverless)を設定する
AppSyncは以下のサービスの中からデータソースを選択することができます。
- Lambda
- DynamoDB
- OpenSearch
- None
- HTTPエンドポイント
- RDS
今回はRDSをデータソースにする構成を確認します。
RDSとして指定できるリソースはAurora Serverlessです。
なおAppSyncの基本的な解説と、DynamoDBをデータソースとする構成については、以下のページをご確認ください。

構築する環境
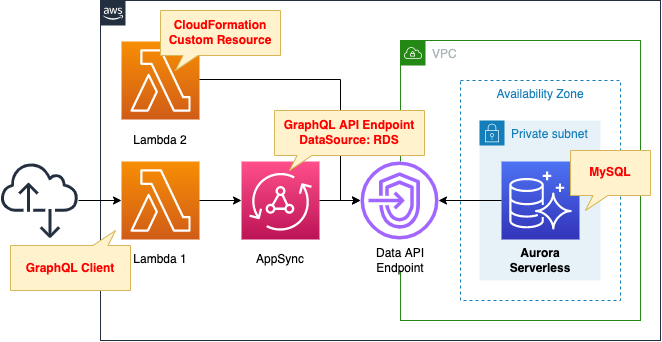
データソースとして動作するAurora Serverlessを作成します。
AppSyncからAurora Serverlessを操作するために、スキーマ・リゾルバを定義します。
本ページは、以下のAWS公式ページを参考に進めます。
https://docs.aws.amazon.com/ja_jp/appsync/latest/devguide/tutorial-rds-resolvers.html
2つのLambda関数を作成します。
関数のランタイム環境はPython3.8とします。
1つ目の関数はCloudFormationカスタムリソースに関連付けて、スタック作成時に実行されるように設定します。
この関数の働きは、Aurora Serverless DBを初期化することです。
2つ目の関数はGraphQL APIを実行するクライアントとして設定します。
Function URLを有効化し、URLクエリパラメータで実行する操作を指定できるようにします。
CloudFormationテンプレートファイル
上記の構成をCloudFormationで構築します。
以下のURLにCloudFormationテンプレートを配置しています。
https://github.com/awstut-an-r/awstut-fa/tree/main/061
テンプレートファイルのポイント解説
本ページはAppSyncのデータソースにAurora Serverlessを指定する方法を中心に取り上げます。
Aurora Serverless作成に関しては、以下のページをご確認ください。

Aurora ServerlessのData APIを有効化する方法については、以下のページをご確認ください。

データソース
Resources:
DataSource:
Type: AWS::AppSync::DataSource
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
Name: DataSource
RelationalDatabaseConfig:
RdsHttpEndpointConfig:
AwsRegion: !Ref AWS::Region
AwsSecretStoreArn: !Ref SecretArn
DatabaseName: !Ref DBName
DbClusterIdentifier: !Ref DBClusterArn
RelationalDatabaseSourceType: RDS_HTTP_ENDPOINT
ServiceRoleArn: !GetAtt DataSourceRole.Arn
Type: RELATIONAL_DATABASE
Code language: YAML (yaml)ポイントはTypeプロパティです。
Aurora Serverlessをデータソースとする場合は、「RDS_HTTP_ENDPOINT」を指定します。
またRelationalDatabaseConfigプロパティで詳細を設定します。
Aurora ServerlessのクラスターのARNや、クラスターに接続するために使用するSecrets Managerのシークレット等を指定します。
データソース用IAMロール
Resources:
DataSourceRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service: appsync.amazonaws.com
Policies:
- PolicyName: !Sub "${Prefix}-DataSourcePolicy"
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- rds-data:DeleteItems
- rds-data:ExecuteSql
- rds-data:ExecuteStatement
- rds-data:GetItems
- rds-data:InsertItems
- rds-data:UpdateItems
Resource:
- !Ref DBClusterArn
- !Sub "${DBClusterArn}:*"
- Effect: Allow
Action:
- secretsmanager:GetSecretValue
Resource:
- !Ref SecretArn
- !Sub "${SecretArn}:*"
Code language: YAML (yaml)AppSyncがAurora Serverlessに接続して、SQL文を実行するためのIAMロールです。
AWS公式サイトで紹介されているポリシーを参考に作成しました。
スキーマ
Resources:
GraphQLSchema:
Type: AWS::AppSync::GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
Definition: |
type Mutation {
createPet(input: CreatePetInput!): Pet
updatePet(input: UpdatePetInput!): Pet
deletePet(input: DeletePetInput!): Pet
}
input CreatePetInput {
type: PetType
price: Float!
}
input UpdatePetInput {
id: ID!
type: PetType
price: Float!
}
input DeletePetInput {
id: ID!
}
type Pet {
id: ID!
type: PetType
price: Float
}
enum PetType {
dog
cat
fish
bird
gecko
}
type Query {
getPet(id: ID!): Pet
listPets: [Pet]
listPetsByPriceRange(min: Float, max: Float): [Pet]
}
schema {
query: Query
mutation: Mutation
}
Code language: YAML (yaml)AWS公式ページを参考に、スキーマを定義します。
リゾルバ
リゾルバもAWS公式ページを参考に作成します。
参考としてcreatePetミューテーション用リゾルバを取り上げます。
Resources:
CreatePetResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: createPet
Kind: UNIT
RequestMappingTemplate: |
#set($id=$utils.autoId())
{
"version": "2018-05-29",
"statements": [
"insert into Pets VALUES ('$id', '$ctx.args.input.type', $ctx.args.input.price)",
"select * from Pets WHERE id = '$id'"
]
}
ResponseMappingTemplate: |
$utils.toJson($utils.rds.toJsonObject($ctx.result)[1][0])
TypeName: Mutation
Code language: YAML (yaml)RequestMappingTemplateおよびResponseMappingTemplateプロパティに、公式ページで紹介されているテンプレートマッピングを記述します。
(参考) GraphQLクライアントLambda関数
AppSyncによるGraphQL APIを実行するクライアントとして、Lambda関数を作成します。
この関数のFunction URLを有効化します。
Function URLに関する詳細は、以下のページをご確認ください。

以下に、関数で実行するPythonコードを取り上げます。
import json
import os
import time
from gql import Client, gql
from gql.transport.aiohttp import AIOHTTPTransport
api_key = os.environ['API_KEY']
graphql_url = os.environ['GRAPHQL_URL']
transport = AIOHTTPTransport(
url=graphql_url,
headers={
'x-api-key': api_key
})
client = Client(transport=transport, fetch_schema_from_transport=True)
CREATE_PET = 'createPet'
UPDATE_PET = 'updatePet'
DELETE_PET = 'deletePet'
GET_PET = 'getPet'
LIST_PETS = 'listPets'
LIST_PETS_BY_PRICE_RANGE = 'listPetsByPriceRange'
def lambda_handler(event, context):
operation = ''
document = None
result = None
if not 'queryStringParameters' in event or (
not 'operation' in event['queryStringParameters']):
operation = LIST_PETS
else:
operation = event['queryStringParameters']['operation']
if operation == CREATE_PET:
document = gql(
"""
mutation add($type: PetType!, $price: Float!) {
createPet(input: {
type: $type,
price: $price
}){
id
type
price
}
}
"""
)
params = {
'type': event['queryStringParameters']['type'],
'price': event['queryStringParameters']['price']
}
result = client.execute(document, variable_values=params)
elif operation == UPDATE_PET:
document = gql(
"""
mutation update($id: ID!, $type: PetType!, $price: Float!) {
updatePet(input: {
id: $id,
type: $type,
price: $price
}){
id
type
price
}
}
"""
)
params = {
'id': event['queryStringParameters']['id'],
'type': event['queryStringParameters']['type'],
'price': event['queryStringParameters']['price']
}
result = client.execute(document, variable_values=params)
elif operation == DELETE_PET:
document = gql(
"""
mutation delete($id: ID!) {
deletePet(input: {
id: $id
}){
id
type
price
}
}
"""
)
params = {
'id': event['queryStringParameters']['id']
}
result = client.execute(document, variable_values=params)
elif operation == GET_PET:
document = gql(
"""
query get($id: ID!) {
getPet(id: $id){
id
type
price
}
}
"""
)
params = {
'id': event['queryStringParameters']['id']
}
result = client.execute(document, variable_values=params)
elif operation == LIST_PETS:
document = gql(
"""
query allpets {
listPets {
id
type
price
}
}
"""
)
result = client.execute(document)
elif operation == LIST_PETS_BY_PRICE_RANGE:
document = gql(
"""
query list($min: Float!, $max: Float!) {
listPetsByPriceRange(min: $min, max: $max) {
id
type
price
}
}
"""
)
params = {
'min': event['queryStringParameters']['min'],
'max': event['queryStringParameters']['max']
}
result = client.execute(document, variable_values=params)
return {
'statusCode': 200,
'body': json.dumps(result, indent=2)
}
Code language: Python (python)GraphQLクエリを実行するLambda関数のコードです。
今回はPython用GraphQLクライアントライブラリとして、GQLを使用します。
https://github.com/graphql-python/gql
GQLを使って、スキーマで定義したクエリ・ミューテーションを実行します。
Pythonの場合、event[‘queryStringParameters’]でURLクエリパラメータを取得することがきます。
URLクエリパラメータで必要なパラメータを渡します。
operationパラメータで実行するGraphQLクエリを指定する形となります。
(参考) CloudFormationカスタムリソース
CloudFormationカスタムリソースを使用して、Aurora Serverlessの初期化処理を実行します。
Aurora ServerlessをCloudFormationカスタムリソースを使って初期化する方法については、以下のページをご確認ください。

以下にカスタムリソースとして実行するLambda関数を取り上げます。
Resources:
Function2:
Type: AWS::Lambda::Function
Properties:
Environment:
Variables:
DBCLUSTER_ARN: !Ref DBClusterArn
DBNAME: !Ref DBName
DBTABLE: !Ref DBTableName
REGION: !Ref AWS::Region
SECRET_ARN: !Ref SecretArn
Code:
ZipFile: |
import boto3
import cfnresponse
import json
import os
dbcluster_arn = os.environ['DBCLUSTER_ARN']
dbname = os.environ['DBNAME']
dbtable = os.environ['DBTABLE']
region = os.environ['REGION']
secret_arn = os.environ['SECRET_ARN']
sql1 = 'create table {table}(id varchar(200), type varchar(200), price float)'.format(table=dbtable)
client = boto3.client('rds-data', region_name=region)
schema = 'mysql'
CREATE = 'Create'
response_data = {}
def lambda_handler(event, context):
try:
if event['RequestType'] == CREATE:
response1 = client.execute_statement(
database=dbname,
resourceArn=dbcluster_arn,
schema=schema,
secretArn=secret_arn,
sql=sql1
)
print(response1)
cfnresponse.send(event, context, cfnresponse.SUCCESS, response_data)
except Exception as e:
print(e)
cfnresponse.send(event, context, cfnresponse.FAILED, response_data)
FunctionName: !Sub "${Prefix}-function2"
Handler: !Ref Handler
Runtime: !Ref Runtime
Role: !GetAtt FunctionRole2.Arn
Code language: YAML (yaml)環境構築
CloudFormationを使用して、本環境を構築し、実際の挙動を確認します。
事前準備
以下の2つの準備を行います。
- Lambda関数用のデプロイパッケージを用意してS3バケットにアップロードする
- Lambdaレイヤー用のデプロイパッケージを用意してS3バケットにアップロードする
なおLambdaレイヤー用パッケージを作成ためのコマンドは以下となります。
$ sudo pip3 install --pre gql[all] -t python
zip -r layer.zip python
Code language: Bash (bash)Lambdaレイヤーに関する詳細については、以下のページをご確認ください。

CloudFormationスタックを作成し、スタック内のリソースを確認する
CloudFormationスタックを作成します。
スタックの作成および各スタックの確認方法については、以下のページをご確認ください。

各スタックのリソースを確認した結果、今回作成された主要リソースの情報は以下の通りです。
- AppSync API:fa-061-GraphQLApi
- Aurora ServerlessのID:fa-061-dbcluster
- GraphQLクライアントLambda関数のFunction URL:https://dzmbqhvhyhkzm4pyufkzmketsy0gdoxt.lambda-url.ap-northeast-1.on.aws/
AWS Management ConsoleからAppSyncを確認します。
まずデータソースです。
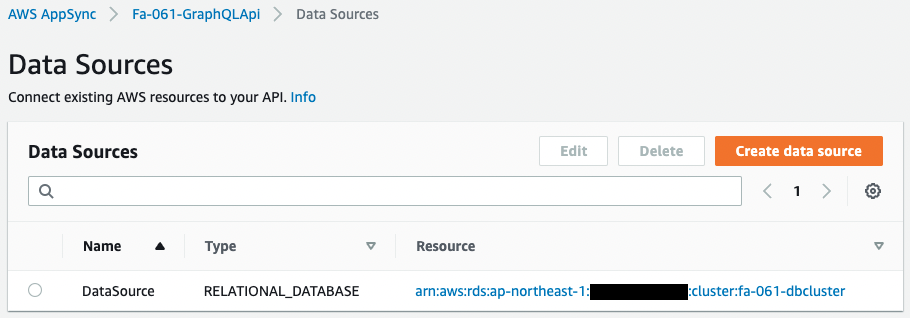
データソースを見ると、Typeが「RELATIONAL_DATABASE」とあります。
正常にAurora Serverlessがデータソースとして設定されています。
次にスキーマ・リゾルバを確認します。
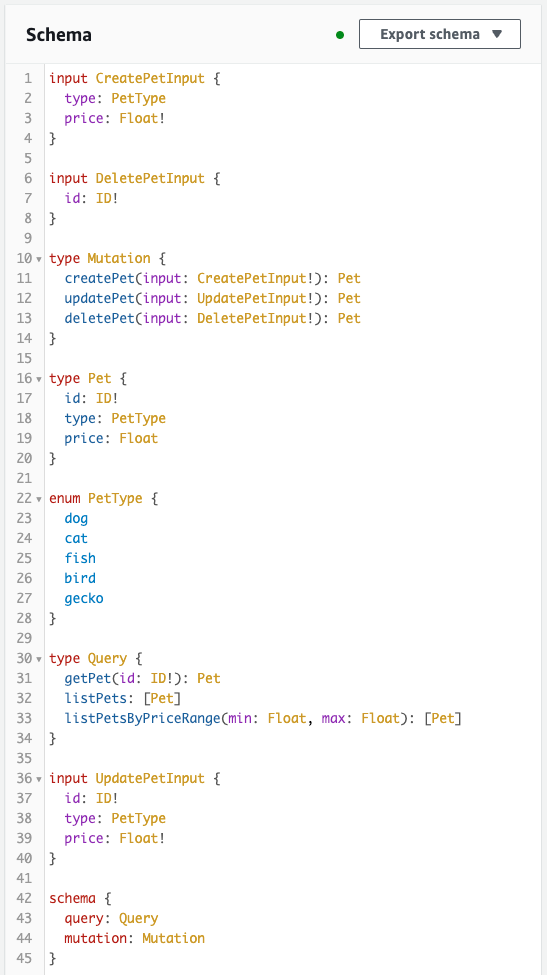
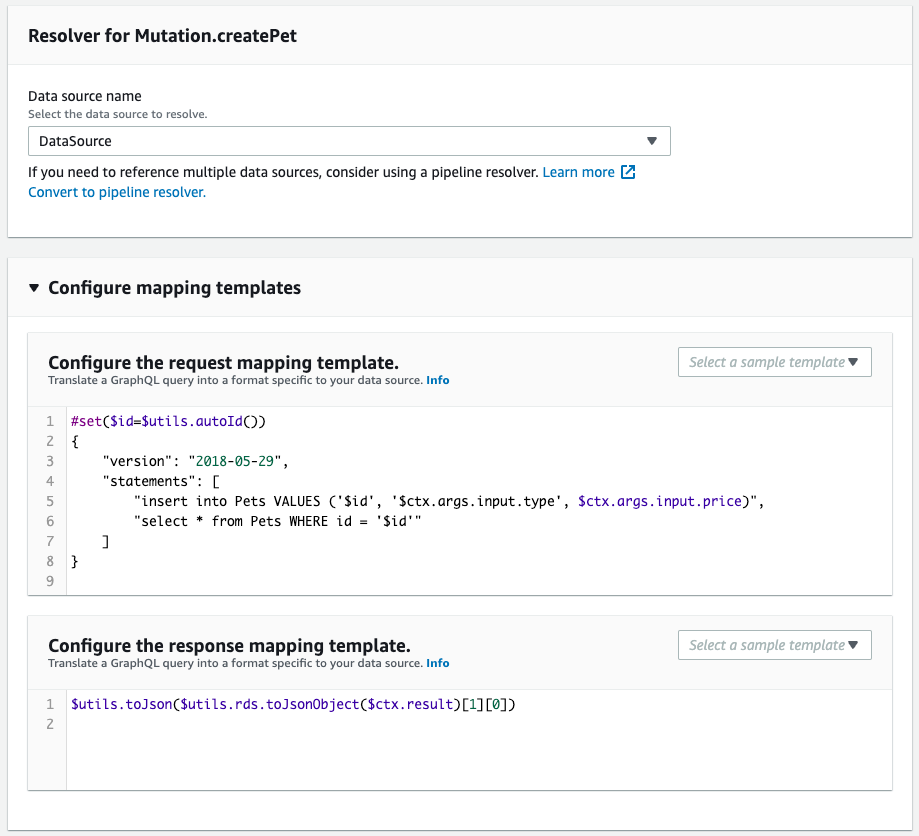
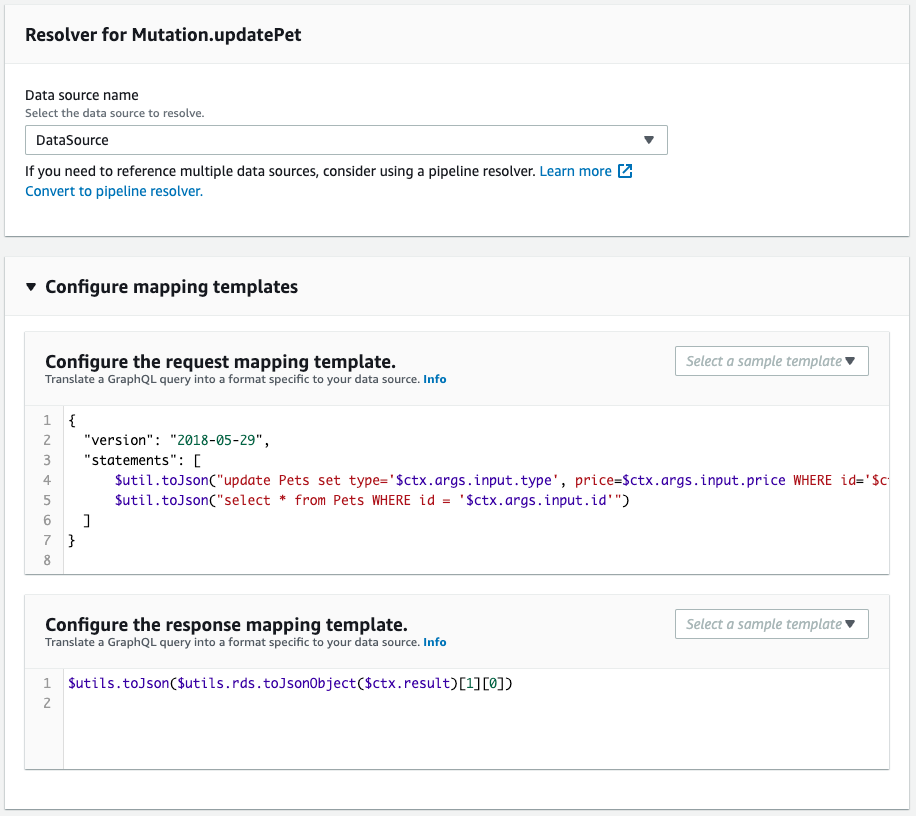
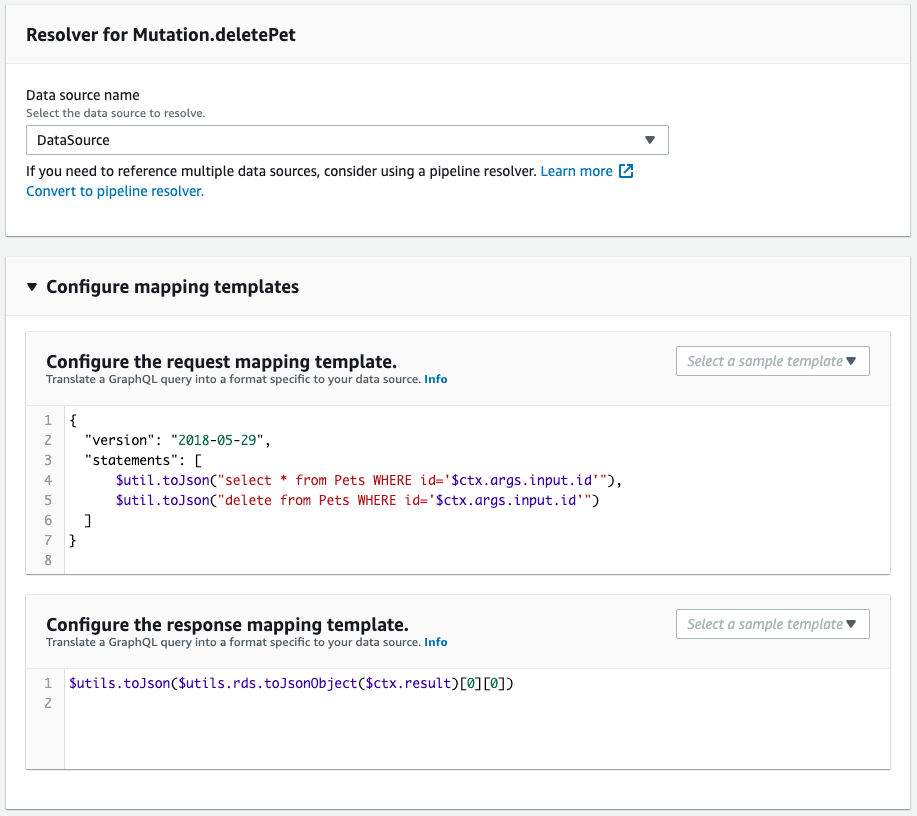
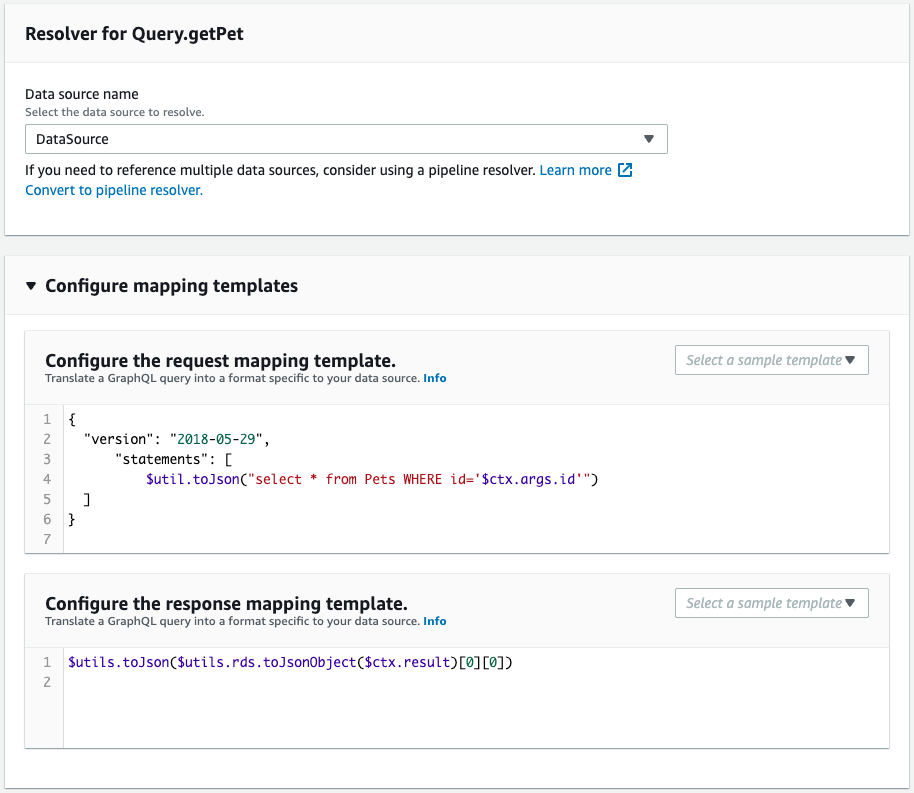
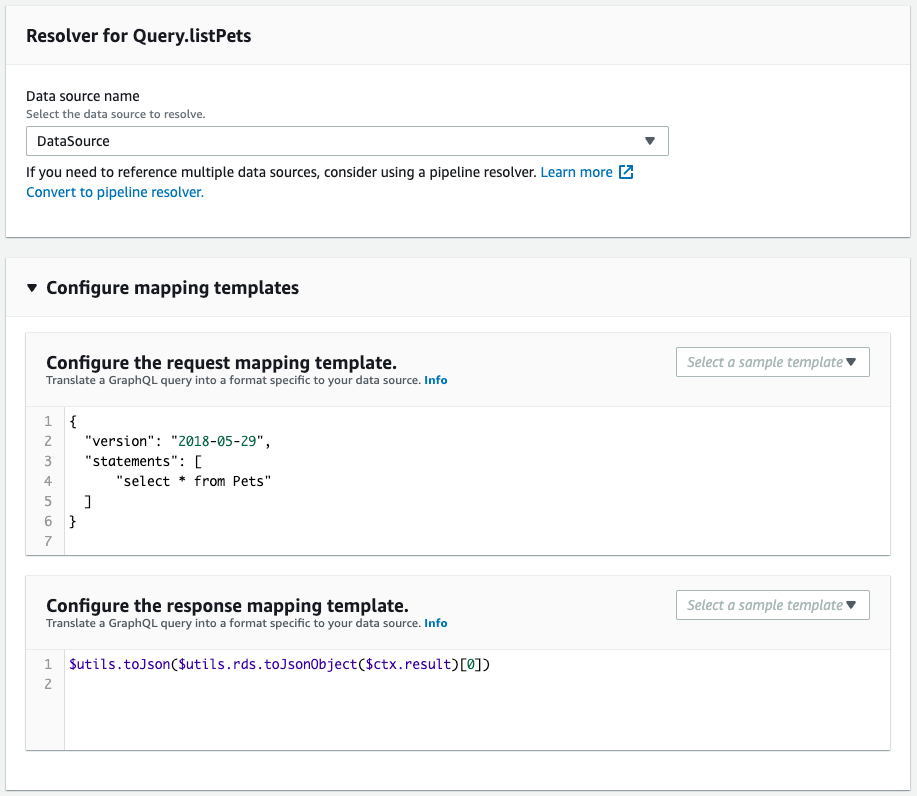
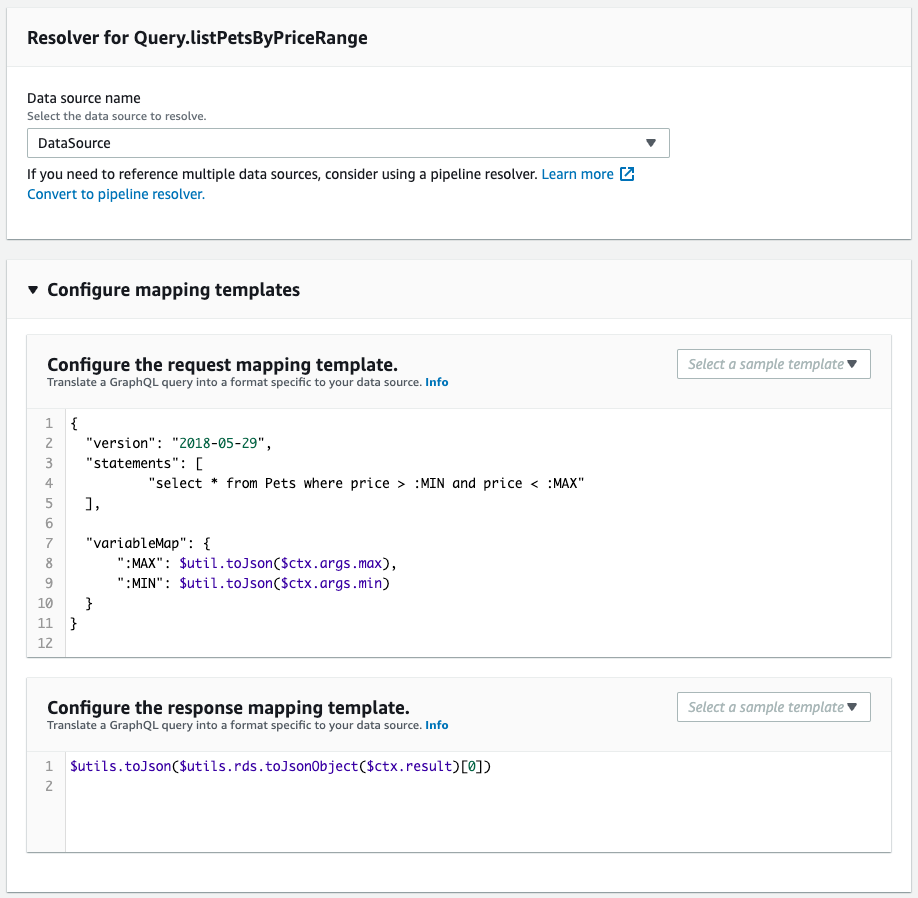
CloudFormationテンプレートファイルで定義した通りに作成されています。
続いてAurora Serverlessを確認します。
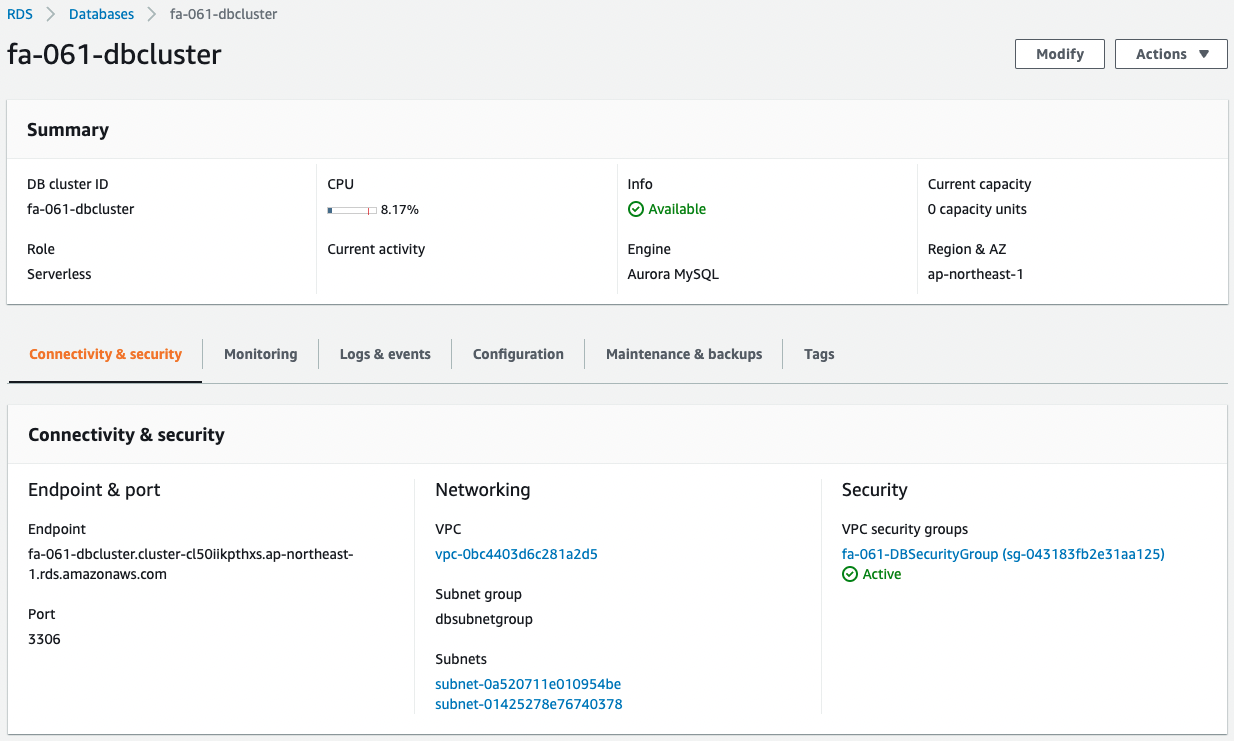
こちらも正常に作成されています。
動作確認
準備が整いましたので、GraphQLクライアントLambda関数のFunction URLにアクセスします。
createPet
まずデータを保存します。
URLクエリのoperationの値に「createPet」を指定し、typeとpriceに任意の値を指定します。
これで以下のGraphQLクエリを実行することになります。
mutation add($type: PetType!, $price: Float!) {
createPet(input: {
type: $type,
price: $price
}){
id
type
price
}
}
Code language: plaintext (plaintext)以下が実行結果です。

正常にデータが追加されました。
getPet
次にIDを指定してデータを取得します。
URLクエリのoperationの値に「getPet」を、idに先ほど確認したIDを指定します。
これで以下のGraphQLクエリを実行することになります。
query get($id: ID!) {
getPet(id: $id){
id
type
price
}
}
Code language: plaintext (plaintext)以下が実行結果です。

先ほど保存されたデータが返ってきました。
updatePet
次にIDを指定してデータを更新します。
URLクエリのoperationの値に「updatePet」を、idに先ほど確認したIDを、typeとpriceに任意の値を設定します。
これで以下のGraphQLクエリを実行することになります。
mutation update($id: ID!, $type: PetType!, $price: Float!) {
updatePet(input: {
id: $id,
type: $type,
price: $price
}){
id
type
price
}
}
Code language: plaintext (plaintext)以下が実行結果です。

typeの値が「fish」から「bird」、priceの値が「10.0」から「50.0」に更新されました。
listPets
listPetsを実行する前に、もう一度getPetを実行し、データを追加しておきます。
保存されているデータの一覧を取得します。
URLクエリのoperationの値に「listPets」を指定します。
これで以下のGraphQLクエリを実行することになります。
query allpets {
listPets {
id
type
price
}
}
Code language: plaintext (plaintext)以下が実行結果です。
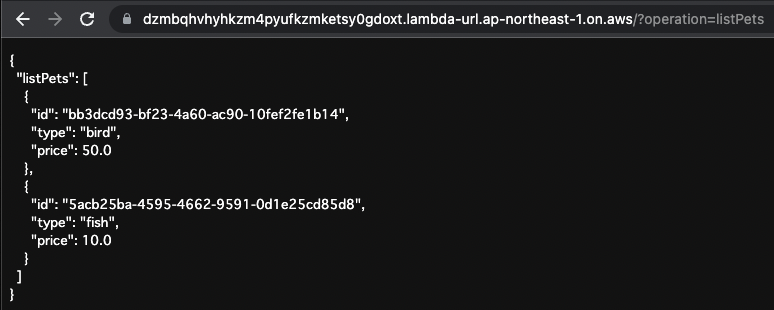
保存されている2つのデータが返ってきました。
listPetsByPriceRange
priceの値で条件付けした上で、保存されたデータを取得します。
URLクエリのoperationの値に「listPetsByPriceRange」を、minとmaxに任意の値を設定します。
これで以下のGraphQLクエリを実行することになります。
query list($min: Float!, $max: Float!) {
listPetsByPriceRange(min: $min, max: $max) {
id
type
price
}
}
Code language: plaintext (plaintext)以下が実行結果です。
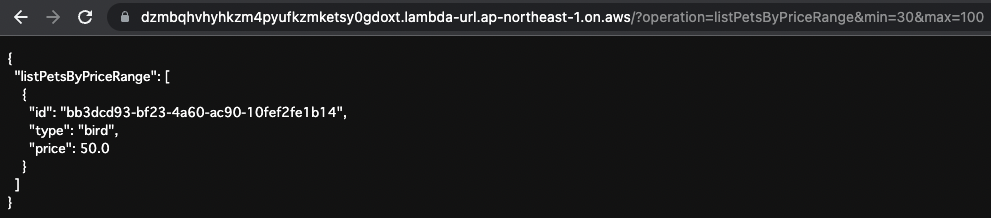
30<=price<=100の条件を満たす「bird」のデータが返ってきました。
deletePet
IDを指定してデータを削除します。
URLクエリのoperationの値に「deletePet」を、idに保存されているデータのIDを設定します。
これで以下のGraphQLクエリを実行することになります。
mutation delete($id: ID!) {
deletePet(input: {
id: $id
}){
id
type
price
}
}
Code language: plaintext (plaintext)以下が実行結果です。

「bird」のデータが削除されました。
改めてlistPetsを実行します。
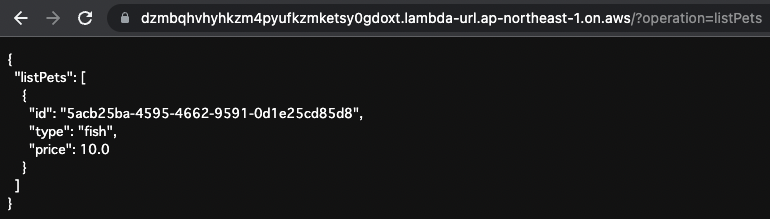
「fish」のデータのみが返ってきました。
「bird」が削除されたことがわかります。
まとめ
AppSyncのデータソースにAurora Serverlessを設定する構成をご紹介しました。