Building Simple DB for Review Data with DynamoDB
This is one of the AWS DVA topics related to development with AWS services.
As an introduction to DynamoDB, we will create a simple database.
We will design the database assuming it is for a review system.
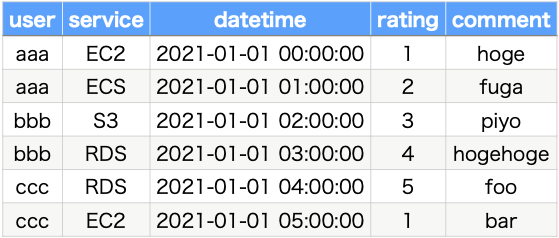
Database to be built
We will store the following data in the database.
- user: User name
- service: Service name
- datetime: Posting date and time
- rating: Rating value (1~5)
- comment:rating text
In concrete terms, the following data will be stored.
We assume that the following queries will be executed against the database:
- To retrieve all reviews posted by a specific user.
- To retrieve the reviews posted by a specific user for a specific service.
- To retrieve the reviews posted by a specific user, starting with the most recent.
- To retrieve reviews for a specific service, starting with the highest rated reviews.
DynamoDB Terms
Keys in DynamoDB
First, let’s look at keys in DynamoDB. There are Partition Key and Sort Key.
Partition Key
In DynamoDB, it is necessary to define a primary key that uniquely identifies the items stored in a table. The primary key can be defined as a partition key alone or as a combination of a partition key and a sort key. A partition key is a key that defines a physical partition where data is stored.
DynamoDB uses the partition key’s value as input to an internal hash function. The output from the hash function determines the partition (physical storage internal to DynamoDB) in which the item will be stored.
Primary Key
A partition key can act as a primary key on its own by specifying unique data, such as a user ID, as the partition key.
Sort Key
The sort key is a key that defines the order of data in the partition defined by the partition key.
DynamoDB uses the partition key value as input to an internal hash function. The output from the hash function determines the partition (physical storage internal to DynamoDB) in which the item will be stored. All items with the same partition key value are stored together, in sorted order by sort key value.
Primary Key
If the data specified in the partition key and the sort key can be combined to uniquely identify an item, the combination of the two will act as the primary key. This is called a composite primary key.
Secondary Indexes
Next, let’s review secondary indexes. There is a global secondary index and a local secondary index.
The assumption is that DynamoDB is a Key – Value type database, so the basic usage is to specify a primary key and retrieve the corresponding item. In addition, it is possible to execute a query to search for items that satisfy specific conditions. Queries can only be executed against a sort key. However, a sort key can only be set for a single attribute. This means that the query cannot be executed on any attribute other than the one specified as the sort key. To solve this problem, we define a secondary index.
Global Secondary Index
The first is a global secondary index.
Global secondary index – An index with a partition key and sort key that can be different from those on the table.
Secondary Indexes
By defining a global secondary index, you are defining a new partition key and sort key for search, separate from the original partition key and sort key, and you can use it to perform queries.
Local Secondary Index
The second is a local secondary index.
Local secondary index – An index that has the same partition key as the table, but a different sort key.
Secondary Indexes
By defining a local secondary index, you are defining a second sort key for the existing partition key, which allows you to query the existing partition using a different attribute.
Points to consider when designing DynamoDB
Consider primary key first
As mentioned earlier, the primary key is used to uniquely identify an item in a table. The primary key can be defined as a partition key alone or as a composite primary key combining a partition key and a sort key.
In this scenario, there are four data to be stored in the table, and among them, the following two data can be candidates for the primary key.
- user
- service
However, neither of them by themselves can uniquely identify an item. For example, a user may review many services, or many users may review a single service. Therefore, we combine the two attributes into a primary key, and by combining the two data, we can uniquely identify a review.
And looking at the search requirements again, we can see that there are several queries that focus on user information. Specifically, (1), (2), and (3). So we will use user as the partition key and service as the sort key. This will allow us to deal with search patterns (1) and (2).
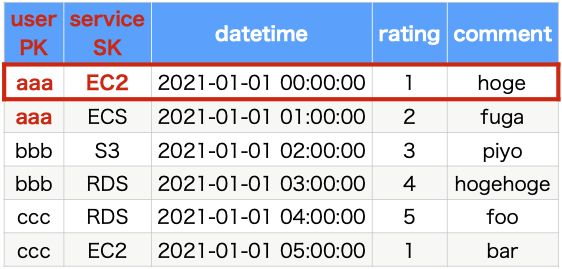
Define local secondary index and query with second sort key
Next, let’s consider how to deal with search pattern (3). This pattern is based on user information, and the query will be performed on the date and time the review was posted. As mentioned earlier, the query can only be executed against the attribute specified in the sort key. However, since we specified service as the sort key, we cannot execute queries using the date and time information at present.
This time, we will create a local secondary index to support this search pattern. Since it is a local secondary index, leave the partition key as user and specify datetime as the new sort key. This will allow us to execute the query of search pattern (3).
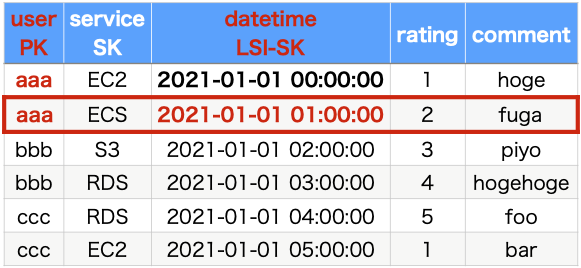
Define global secondary index and query with second primary key
Finally, we will consider how to deal with search pattern ④. This pattern is based on service information, and queries are to be executed on evaluated values. Currently, the index for this search is not prepared, so it is not possible to execute the query.
This time, we will create a global index to support the main search pattern. Since it is a global index, specify service as the new partition key and rating as the new sort key. Now, the query of search pattern 4) can be executed.
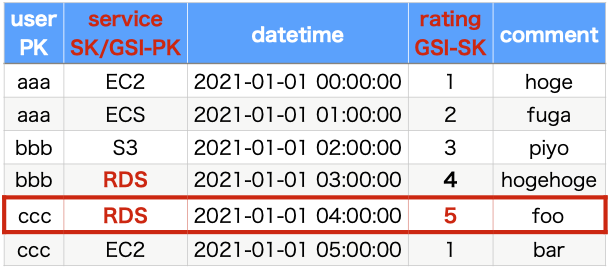
Summary of DB design for review data
Let’s summarize the key points in the configuration.
First, the primary key should be as follows
- Partition key: user
- Sort key: service
Next, the local secondary index is as follows
- Partition key: user
- Sort key: datetime
Finally, the global secondary index is as follows
- Partition key: service
- Sort key: rating
CloudFormation Template File
We will use CloudFormation to build a DynamoDB table for hands-on use.
The CloudFormation template file and the JSON file for the sample data to be fed into DynamoDB are placed at the following URL.
https://github.com/awstut-an-r/awstut-dva/tree/main/03/002
Explanation of points in template file
We will cover the key points of the template file to configure this architecture.
Specify only what is specified for keys in attributes
Check the parameters related to the table attributes.
Resources:
Table:
Type: AWS::DynamoDB::Table
Properties:
AttributeDefinitions:
- AttributeName: user
AttributeType: S
- AttributeName: service
AttributeType: S
- AttributeName: datetime
AttributeType: S
- AttributeName: rating
AttributeType: N
#- AttributeName: comment
# AttributeType: S
Code language: YAML (yaml)The AttributeDefinitions property is used to set the attributes of the table.
The caveat of this property is that it does not specify all the attributes that are planned for the table.
AttributeDefinitions
A list of attributes that describe the key schema for the table and indexes.
AWS::DynamoDB::Table
In other words, only the attributes that are specified as keys in defining primary keys and secondary indexes should be set to this property. In this table, five attributes will be created, but only four attributes (user, service, datetime, rating) will be used as the primary key or secondary index. Therefore, comment is not specified in this property. Please note that if you specify comment as well, an error will occur and the CloudFormation stack will not be created properly.
Hash key is partition key, range key is sort key
Next, let’s check the primary key settings.
Resources:
Table:
Type: AWS::DynamoDB::Table
Properties:
KeySchema:
- AttributeName: user
KeyType: HASH
- AttributeName: service
KeyType: RANGE
Code language: YAML (yaml)Define the primary key in the KeySchema property. Specify the partition key or sort key in the KeyType property in the same property, and specify the corresponding attribute. The specifications for both keys are as follows
- Partition key: HASH (hash key)
- Sort key: RANGE (range key)
The reason why the partition key is referred to as the hash key and the sort key as the range key is a remnant of how they used to be called.
In this case, we will specify user as the partition key and service as the sort key.
Specifying projection when creating secondary index
Next, let’s check the local secondary index (LSI).
Resources:
Table:
Type: AWS::DynamoDB::Table
Properties:
LocalSecondaryIndexes:
- IndexName: lsi-user-datetime
KeySchema:
- AttributeName: user
KeyType: HASH
- AttributeName: datetime
KeyType: RANGE
Projection:
NonKeyAttributes:
- service
- comment
ProjectionType: INCLUDE
Code language: YAML (yaml)Local secondary indexes can be configured with the LocalSecondaryIndexes property.
In the KeySchema property, specify the attribute that is the original partition key and the attribute that will be the sort key for LSI. In this case, the partition key is user and datetime is specified as the LSI sort key.
The key point in defining the secondary index is the projection. Projection is specified by the Projection property. Projection is a setting that determines whether or not attributes other than the primary key will be included in the query results when a search is performed using the secondary index.
In this case, if the projection is not set, only the user and datetime attributes will be available in the query results.
However, this is not enough for the attributes that are important for review data. Therefore, by specifying “INCLUDE” in the ProjectionType property and attributes in the NonKeyAttributes property, we can specify the attributes to be included in the projection. In this case, by specifying the service and comment attributes, we will be able to include both attributes in the query result.
The settings for the global secondary index (GSI) are the same as in LSI.
Resources:
Table:
Type: AWS::DynamoDB::Table
Properties:
GlobalSecondaryIndexes:
- IndexName: gsi-service-rating
KeySchema:
- AttributeName: service
KeyType: HASH
- AttributeName: rating
KeyType: RANGE
Projection:
NonKeyAttributes:
- user
- comment
ProjectionType: INCLUDE
Code language: YAML (yaml)This time, we will specify service as the GSI partition key and rating as the sort key.
Architecting
We will use CloudFormation to build this environment and check its actual behavior.
Create CloudFormation stack and check resources in stack
For information on how to create a stack and check each stack, please refer to the following page

The DynamoDB table created this time is “dva-03-002-table”, check the creation status from the AWS Management Console.
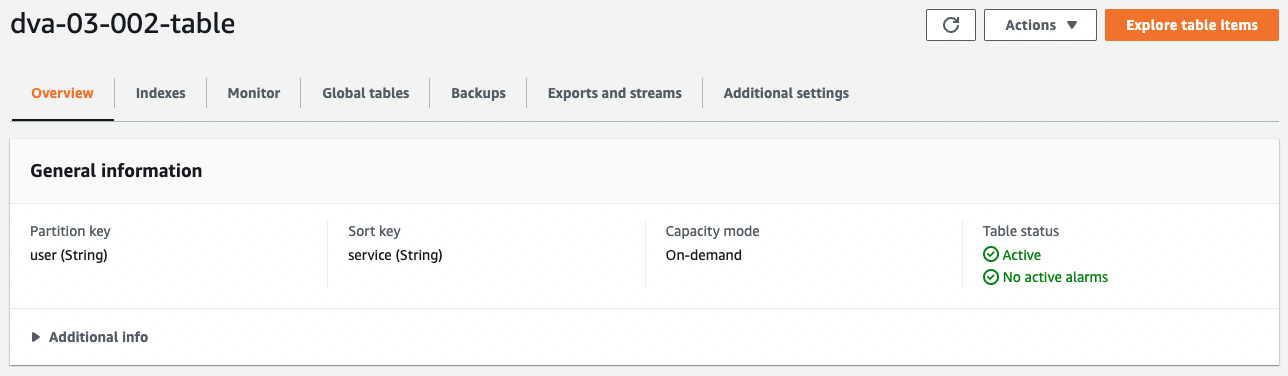
You can see that the table has been created successfully. Next, we will check the secondary index.
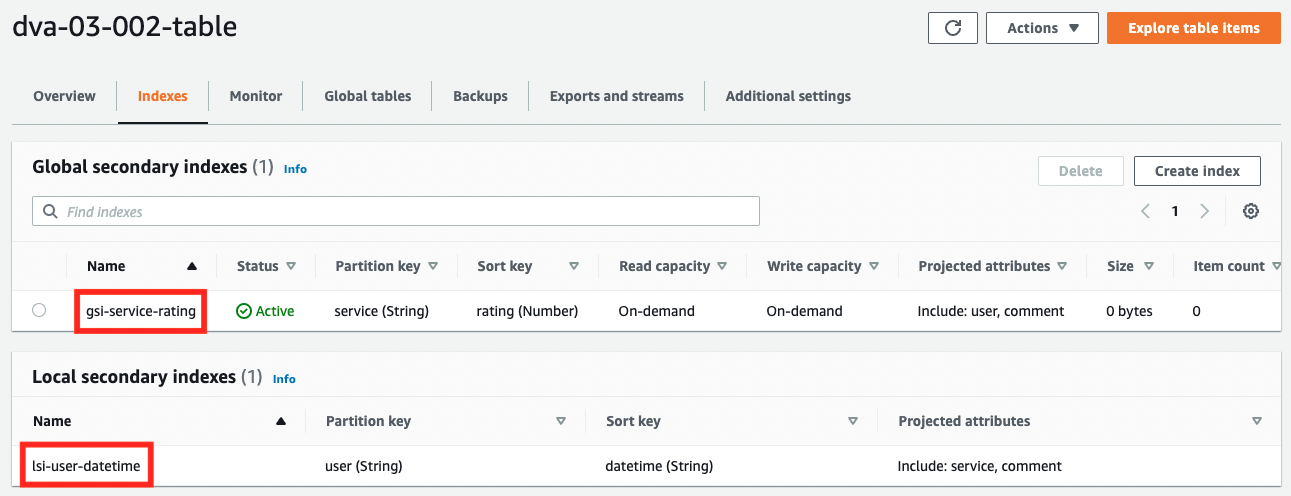
We can see that both indexes have been created successfully. The partition key, sort key, and projection are also set as specified.
Writing test data to the table
From the AWS CLI, submit the data to the table you created.
$ aws dynamodb batch-write-item \
--request-items file://request-items.json
Code language: Bash (bash)Prepare the data to be written as a JSON file (request-items.json) and pass the file to the request-items option.
Preparing for table operations
To perform operations on a table from the AWS Management Console, click the “Explore table items” button.

From this page, you can scan or query the table.
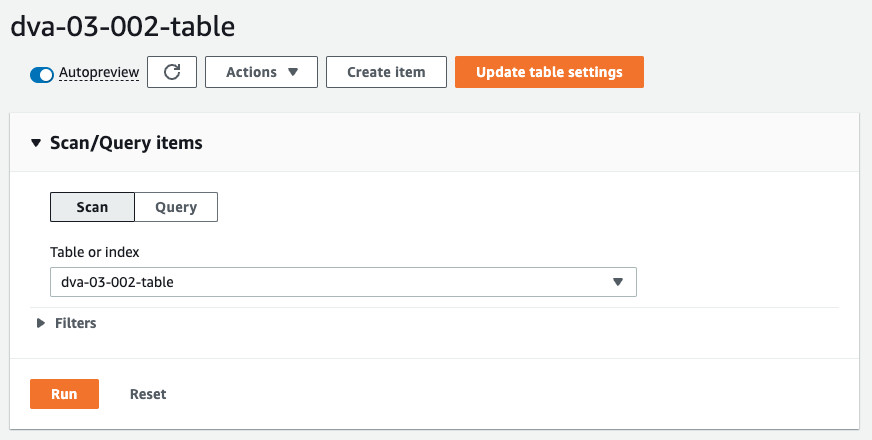
Table operations: scan
Now that we are ready, we will perform a search on the table. First, we will perform a scan to retrieve all the data in the table.
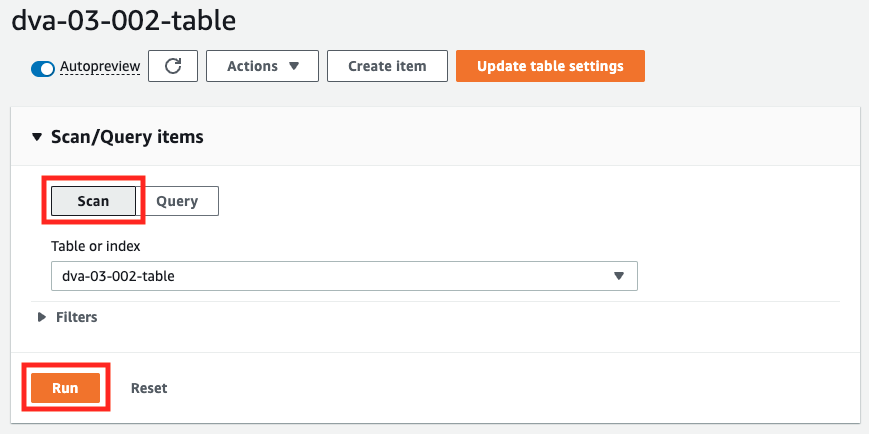
After selecting “Scan”, click on the “Run” button.
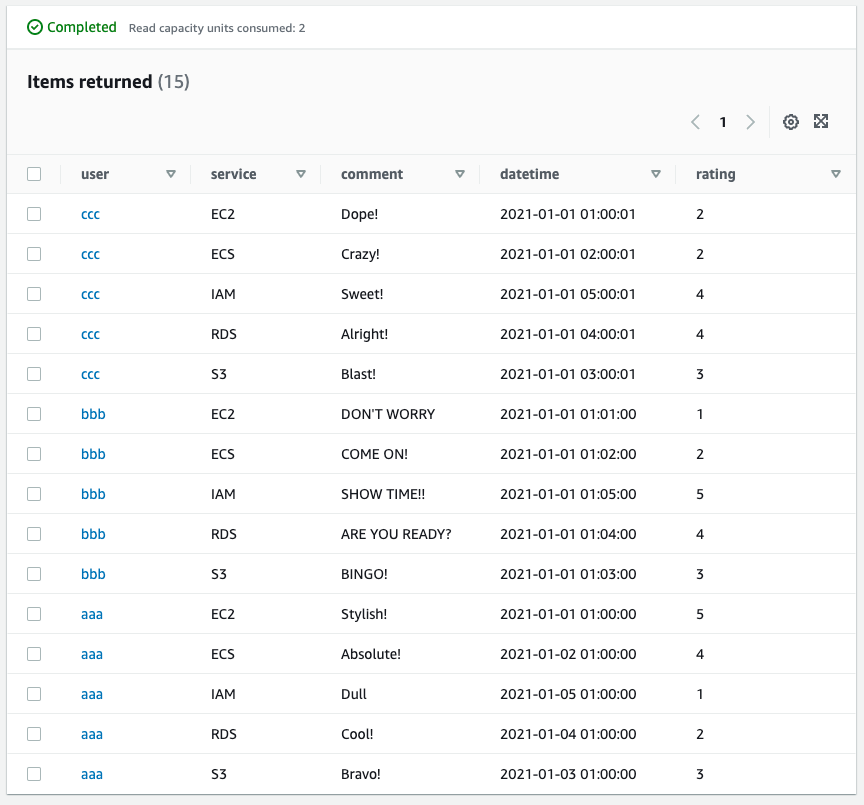
The results of the scan will be displayed at the bottom of the page. All the data (15 items) were successfully displayed. There are no settings such as projection in Scan, and all attributes can be acquired.
Table operations: query ①
Next, let’s check the operation of the query.
Let’s say we want to retrieve all the review data for user aaa.
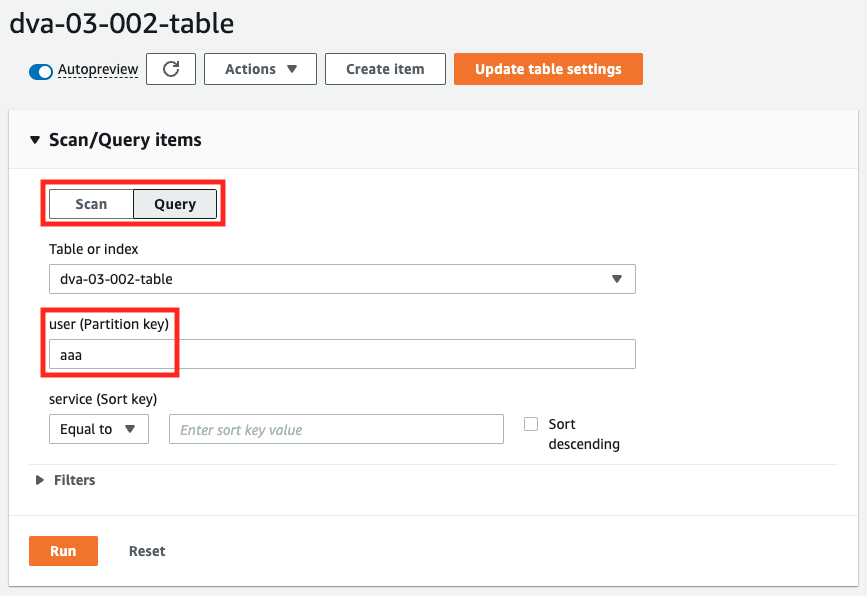
After selecting “Query”, specify only the partition key “user”.
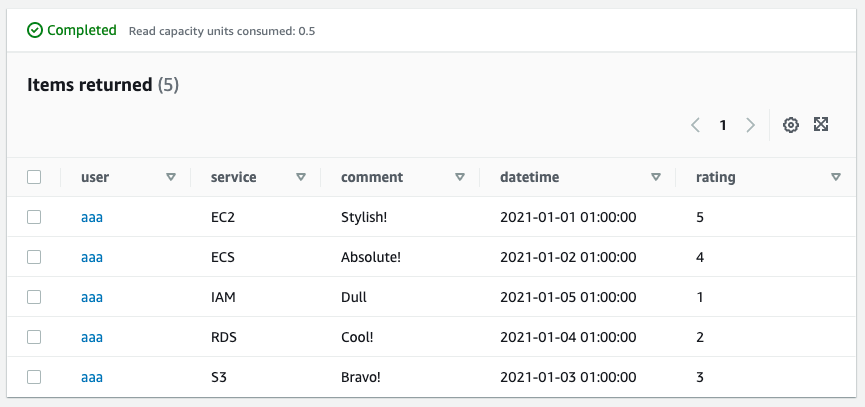
Looking at the result of query execution, we can see that we have retrieved the five reviews posted by user aaa. This means that the search requirement (1) “Retrieve all reviews posted by a specific user. was achieved.
Table operation: query ②
Suppose we want to retrieve the reviews of EC2 by user aaa.
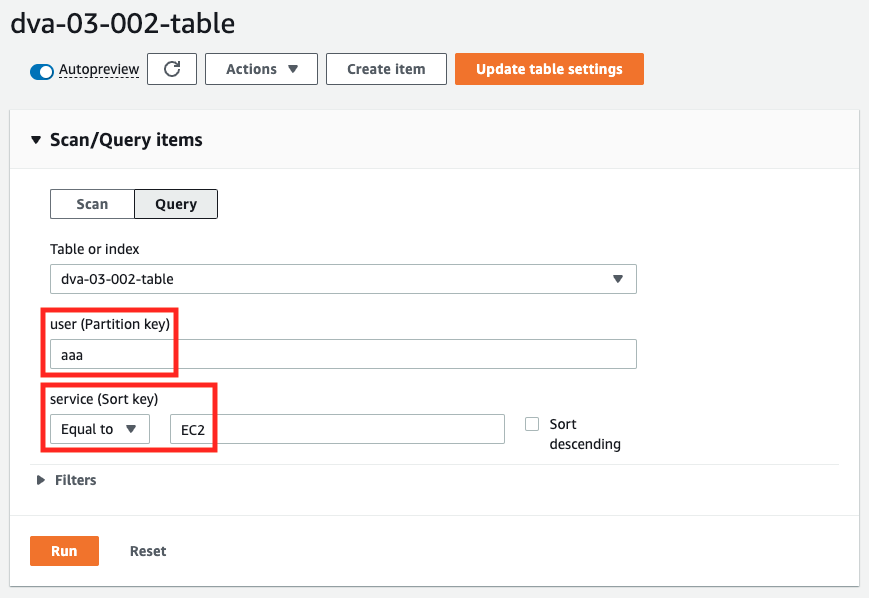
Specify “aaa” as the partition key (user) and “EC2” as the sort key (service).
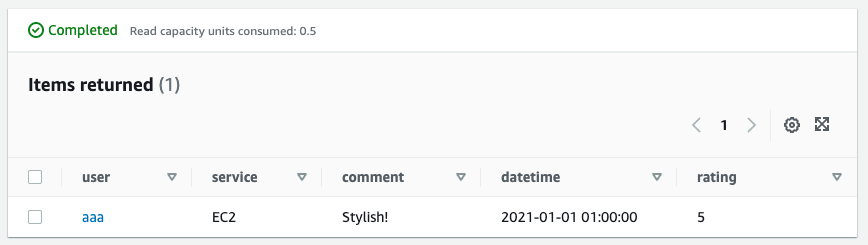
Looking at the result of the query execution, we can see that we have obtained the review data for EC2 posted by user aaa. From the above, we have satisfied the search requirement (2) “To retrieve reviews posted by a specific user for a specific service. of the search requirement was achieved.
Table operation: query ③
Suppose we want to retrieve the reviews of user bbb, starting with the most recent one.
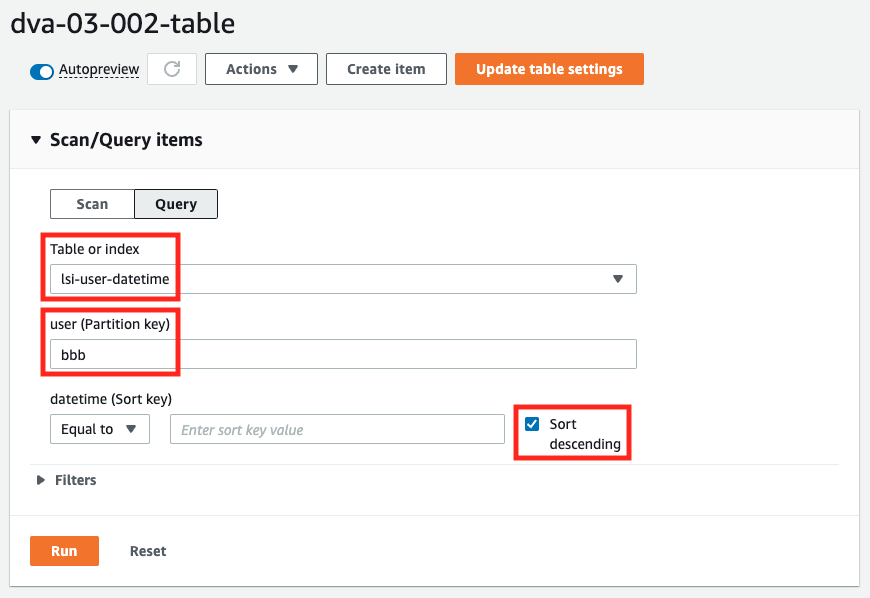
We will execute the query against the local secondary index, so select “lsi-user-datetime”, specify “bbb” for user, and specify the sort order as descending.
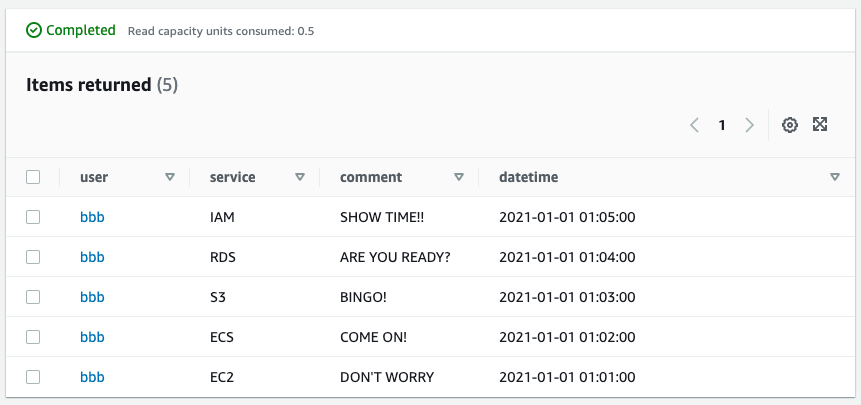
The result of the query shows that the reviews posted by user bbb are retrieved in order from the most recent one. This satisfies the search requirement (3) “retrieve reviews posted by a specific user in the order of the most recent reviews. was achieved.
Table operation: query ④
Let’s consider retrieving the reviews with the highest rating for the service IAM.
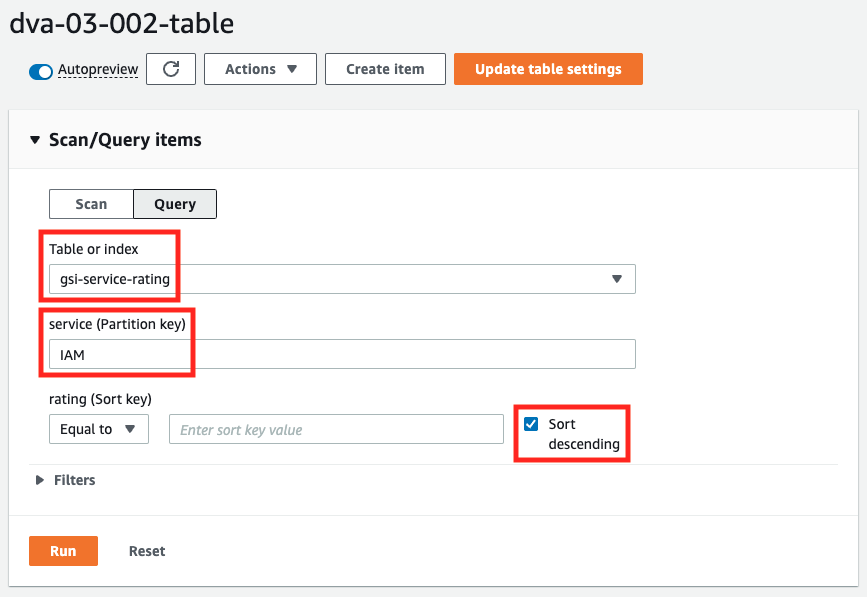
We will execute the query against the global secondary index, so we will select “gsi-service-rating”, specify “IAM” for service, and specify the sort order as descending.
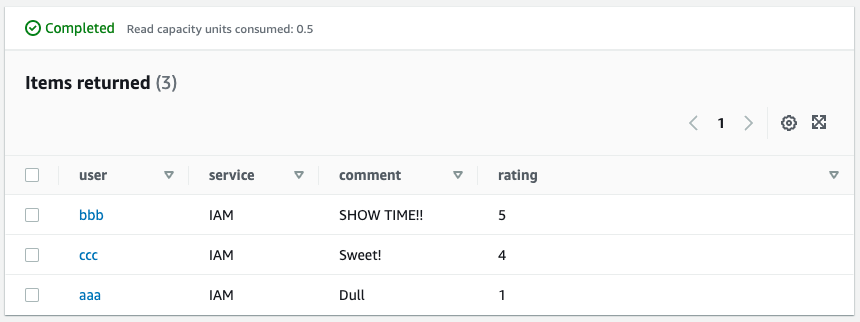
Looking at the results of the query execution, we can see that three of the IAM reviews were retrieved from those with the highest ratings. As a result, we have satisfied the search requirement (4), “Obtain the reviews with the highest rating among the reviews for a specific service. was achieved.
Summary
We have reviewed the DynamoDB primary key and secondary index.
By setting the primary key and secondary index according to the search requirements, we confirmed that it is possible to respond to a variety of queries.