Configuration to check scaling based on all predefined metrics
As an introduction to EC2 Auto Scaling, I have introduced a configuration that scales the number of instances based on CPU utilization in the following page.

In addition to the above CPU, there are four predefined metrics.
・ASGAverageCPUUtilization—Average CPU utilization of the Auto Scaling group.
・ASGAverageNetworkIn—Average number of bytes received on all network interfaces by the Auto Scaling group.
・ASGAverageNetworkOut—Average number of bytes sent out on all network interfaces by the Auto Scaling group.
・ALBRequestCountPerTarget—Average Application Load Balancer request count per target for your Auto Scaling group.
Target tracking scaling policies for Amazon EC2 Auto Scaling
In this article, we will use the above four metrics to actually create a scaling configuration and check its behavior.
Environment
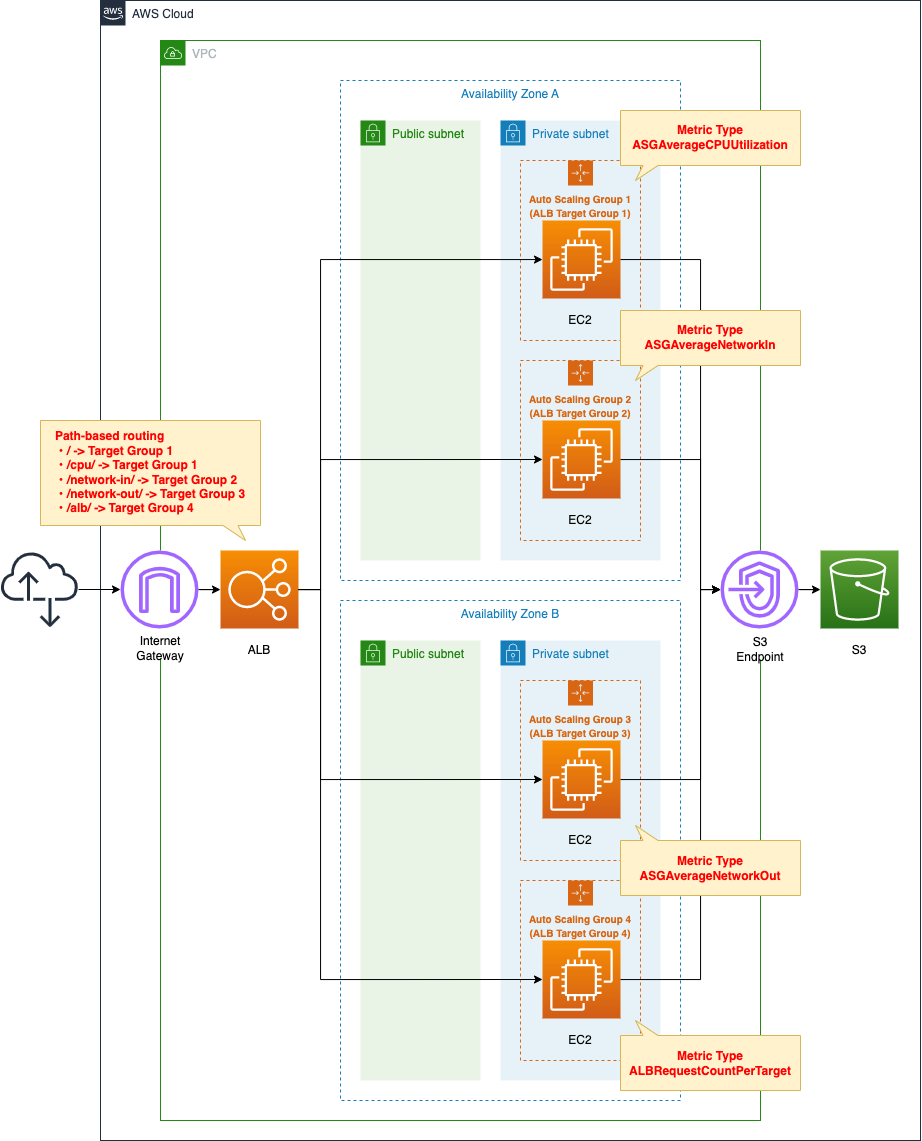
Create an ALB and four ALB target groups. For each group, associate an Auto Scaling group. For each Auto Scaling group, prepare a scaling policy so that it scales based on the four metric types described earlier.
Using path-based routing, associate each target group with an ALB. the correspondence between URLs and target groups is as follows
- /cpu/:ALB Target Group 1
- /network-in/:ALB Target Group 2
- /network-out/:ALB Target Group 3
- /alb/:ALB Target Group 4
The EC2 instances we are going to create will have Apache installed in common, will run as a web server, and will listen for HTTP at 80/tcp.
CloudFormation template files
We will build the above configuration using CloudFormation. We have placed the CloudFormation template at the following URL.
https://github.com/awstut-an-r/awstut-fa/tree/main/027
Explanation of points in template files
The basic configuration is the same as the configuration for scaling by CPU usage described above. In this page, we will focus on the differences.
For more information about path-based routing in ALB, please refer to the following page.

Predefined metrics (CPU, Network in/out)
First, let’s check the scaling policy for the three metrics. The key is to select the metric type and specify the threshold value.
Resources:
ScalingPolicy:
Type: AWS::AutoScaling::ScalingPolicy
Properties:
AutoScalingGroupName: !Ref AutoScalingGroup
PolicyType: TargetTrackingScaling
TargetTrackingConfiguration:
PredefinedMetricSpecification:
PredefinedMetricType: !Ref PredefinedMetricType
TargetValue: !Ref TargetTrackingConfigurationTargetValue
Code language: YAML (yaml)The metric type is set by the PredefinedMetricType Property and the threshold is set by the TargetValue property.
In this case, we will use the following settings for verification.
| Auto Scaling Group | Metric Type | Threshold |
| Group 1 | ASGAverageCPUUtilization | 5(%) |
| Group 2 | ASGAverageNetworkIn | 1000(Byte) |
| Group 3 | ASGAverageNetworkOut | 10000(Byte) |
Predefined metric (number of ALB requests)
Check the scaling policy for group 4. The key to using this metric is that you need to specify the ALBs to be targeted in the form of resource labels.
Resources:
ScalingPolicy:
Type: AWS::AutoScaling::ScalingPolicy
Properties:
...
PredefinedMetricSpecification:
PredefinedMetricType: ALBRequestCountPerTarget
ResourceLabel: !Ref ALBResourceLabel
TargetValue: !Ref TargetTrackingConfigurationTargetValue
Code language: YAML (yaml)This time we set the threshold value to 10.
The resource label consists of two elements.
The format is app/load-balancer-name/load-balancer-id/targetgroup/target-group-name/target-group-id , where
・app/load-balancer-name/load-balancer-id is the final portion of the load balancer ARN, and
・targetgroup/target-group-name/target-group-id is the final portion of the target group ARN.
AWS::AutoScaling::ScalingPolicy PredefinedMetricSpecification
These values can be retrieved from the ALB and target group resources using the built-in function Fn::GetAtt.
Outputs:
ALBResourceLabel:
Value: !Sub
- "${LoadBalancerFullName}/${TargetGroupFullName}"
- LoadBalancerFullName: !GetAtt ALB.LoadBalancerFullName
TargetGroupFullName: !GetAtt ALBTargetGroup4.TargetGroupFullName
Code language: YAML (yaml)Use the built-in function Fn::Sub to create a resource label from the two values.
Architecting
We will use CloudFormation to build this environment and check its actual behavior.
Create CloudFormation stacks and check resources in stacks
We will create a CloudFormation stack.
For information on how to create a stack and check each stack, please refer to the following page

After checking the resources in each stack, here is the information on the main resources created this time
- ALB: fa-027-ALB
- Target group 1: fa-027-ALBTargetGroup1
- Target group 2: fa-027-ALBTargetGroup2
- Target group 3: fa-027-ALBTargetGroup3
- Target group 4: fa-027-ALBTargetGroup4
We will also check the resource creation status from the AWS Management Console.
First, we will check the ALB.
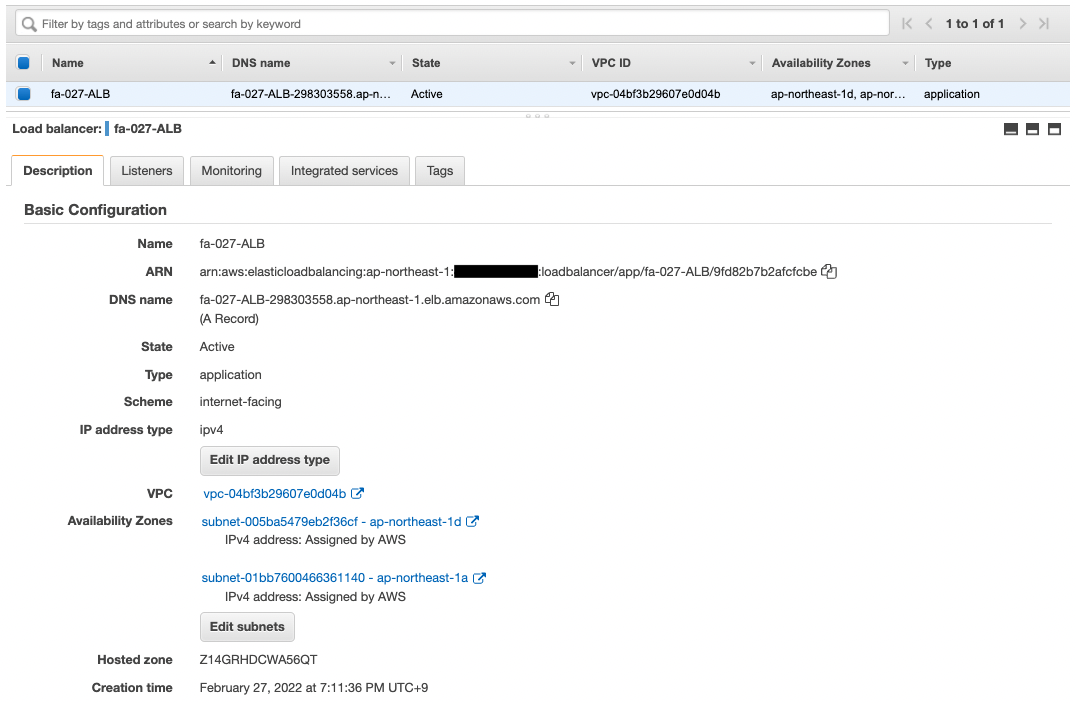
The ALB has been created successfully.
Check each Auto Scaling group.
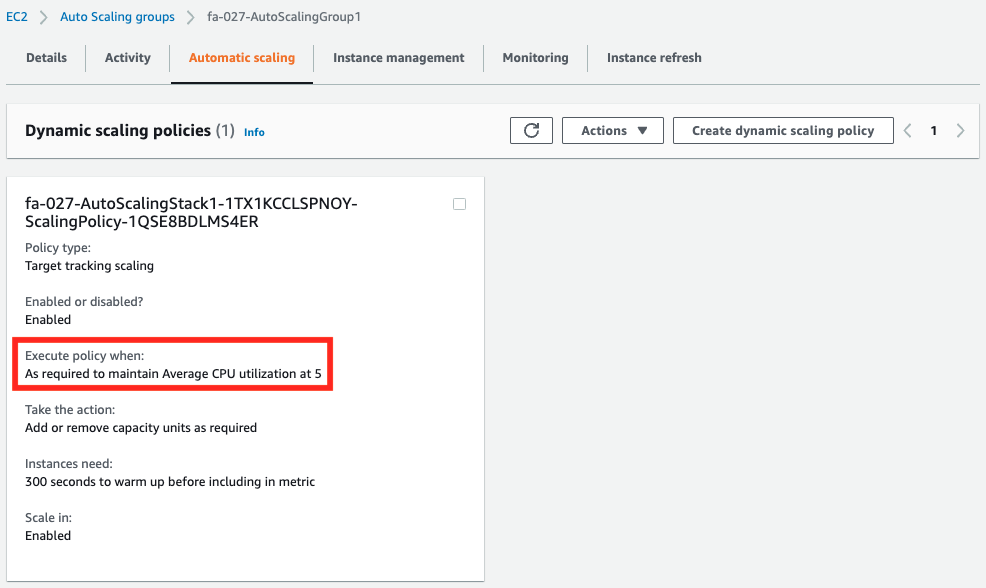
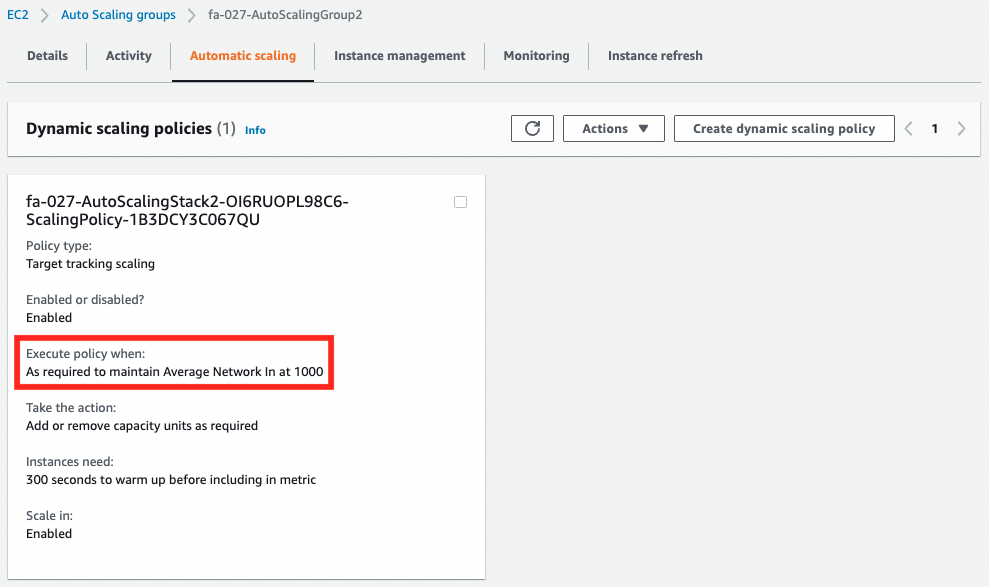
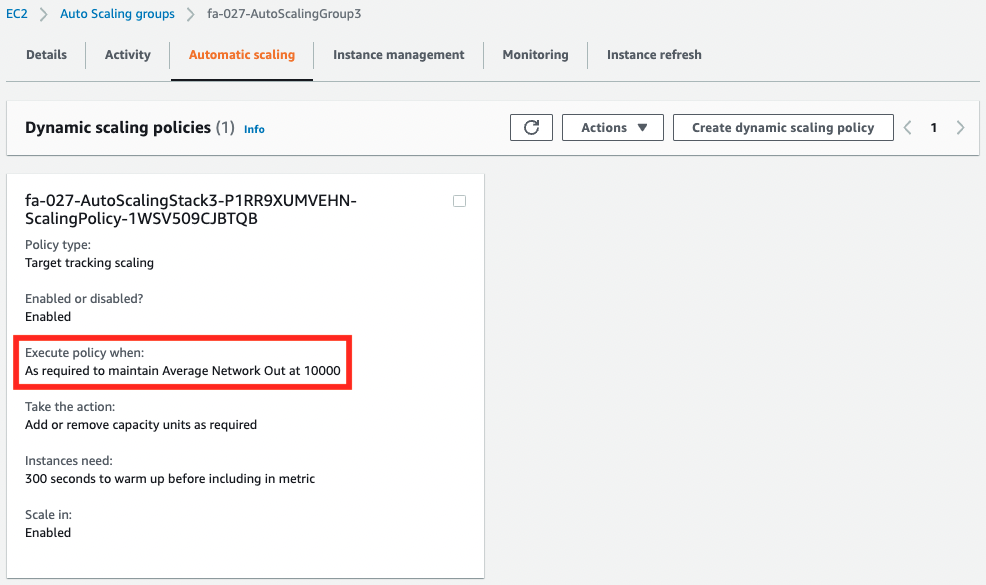
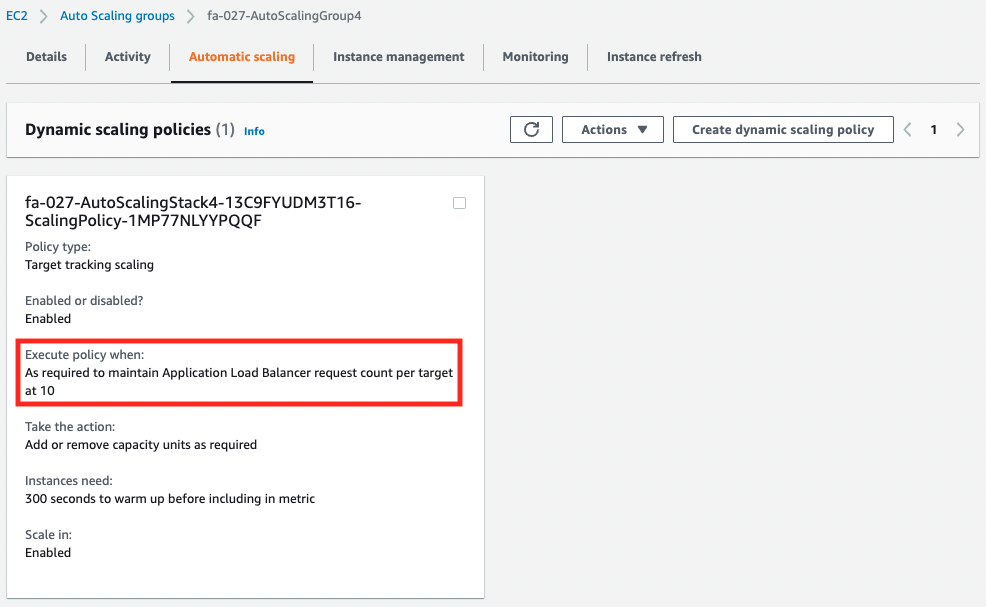
You can see that separate metrics have been set.
Operation check
Now that everything is ready, let’s access the ALB.
ASGAverageCPUUtilization
The behavior of CPU utilization has already been verified in another page, so we will skip it. Please refer to that page for details.
ASGAverageNetworkIn
Go to /network-in/ and check the behavior of ALB target group 2.

The metric type for this group is ASGAverageNetworkIn, which means that scaling occurs according to the number of bytes received. After reloading repeatedly for a while, the number of bytes received exceeds the threshold (1000Byte).
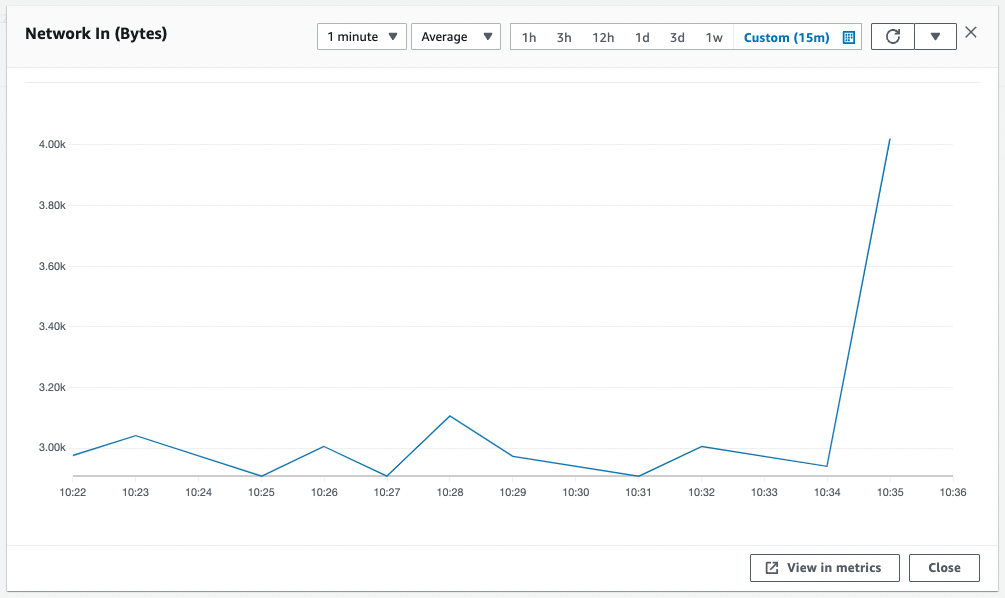
Looking at the history, we can see that scaling has started and a new instance has been created.
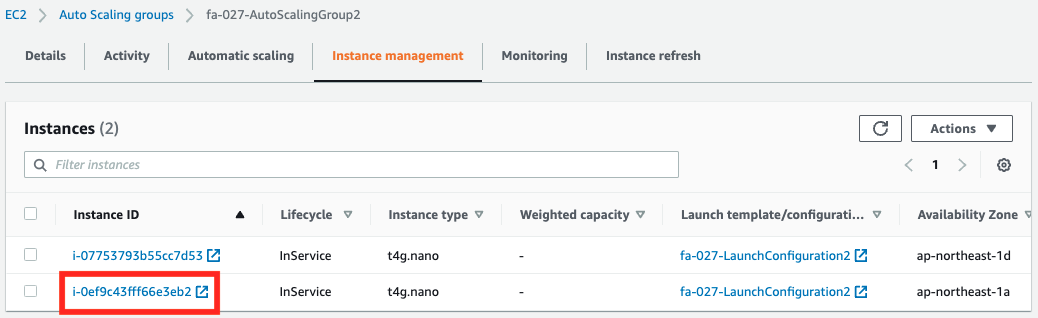
We will access the ALB again.

In addition to the previous instance, we received a response from the newly created instance. In this way, we were able to scale the number of EC2 instances according to the amount of data received.
ASGAverageNetworkOut
Next, we will access /network-out/ to check the behavior of ALB target group 3.

The metric type for this group is ASGAverageNetworkOut, which means that scaling occurs based on the number of bytes sent. After reloading repeatedly for a while, the number of bytes sent will exceed the threshold (10000Byte).
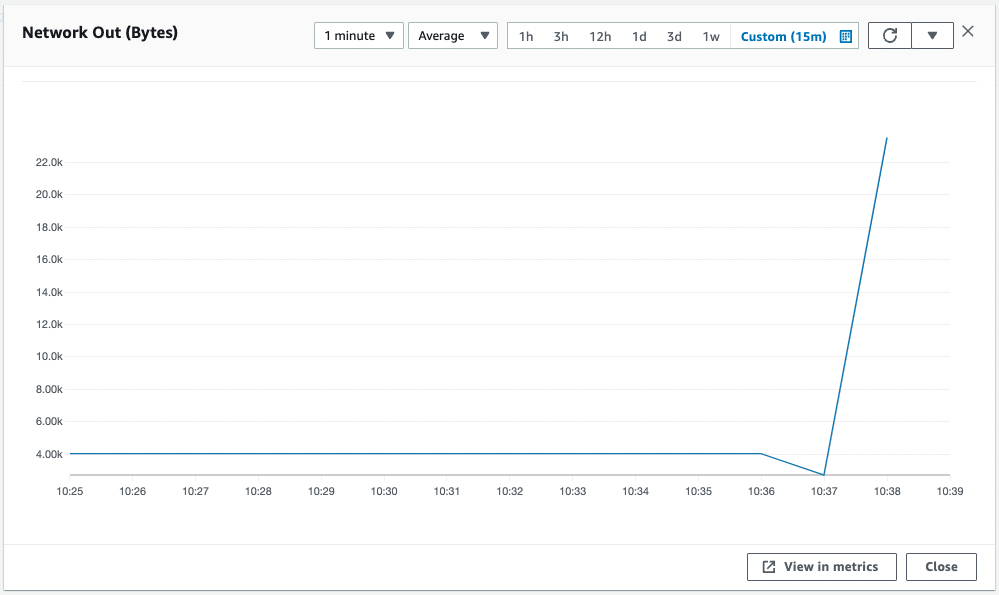
Scaling has started and a new instance has been created and can be accessed via ALB.
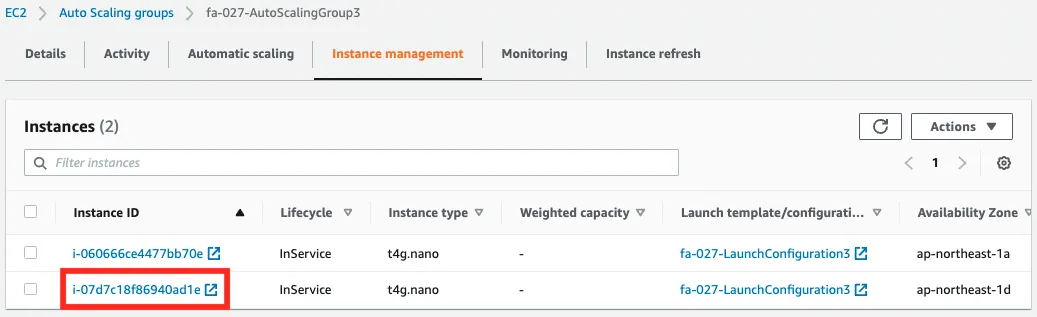

In this way, we were able to scale the number of EC2 instances according to the amount of data sent.
ALBRequestCountPerTarget
Next, we will access /alb/ to check the behavior of ALB target group 4.

The metric type for this group is ALBRequestCountPerTarget, which means that scaling will start based on the number of completed requests per instance in the ALB target group. After a while of repeated reloads, the number of requests will exceed the threshold (10).
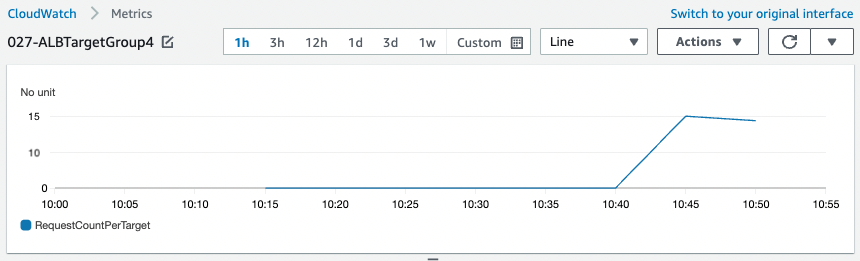
Scaling has started and a new instance has been created and can be accessed via ALB.
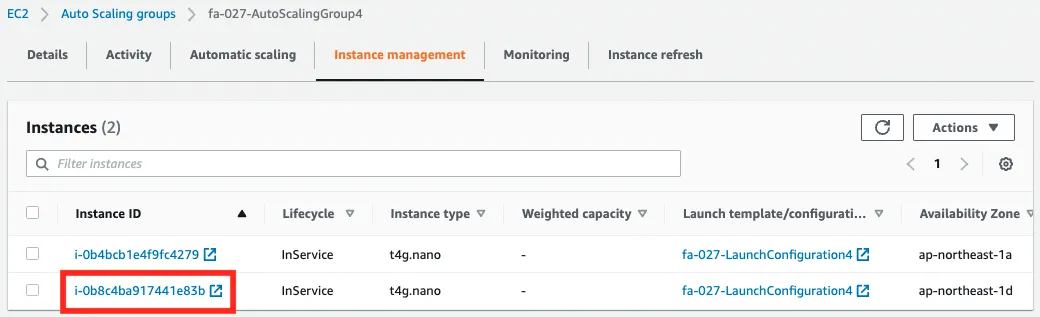

In this way, we were able to scale the number of EC2 instances according to the number of requests processed in the ALB target group.
Summary
We have actually created a scaling configuration using the four predefined metrics, and checked its behavior.