Automate document uploads for OpenSearch indexing with CloudFormation custom resources
A CloudFormation custom resource is a stack operation (create, update, delete) that allows you to perform any action at the time of stack operation (create, update, delete).
In this case, we will use a custom resource to automatically upload a JSON file located in an S3 bucket to create an index when creating an OpenSearch domain.
Environment
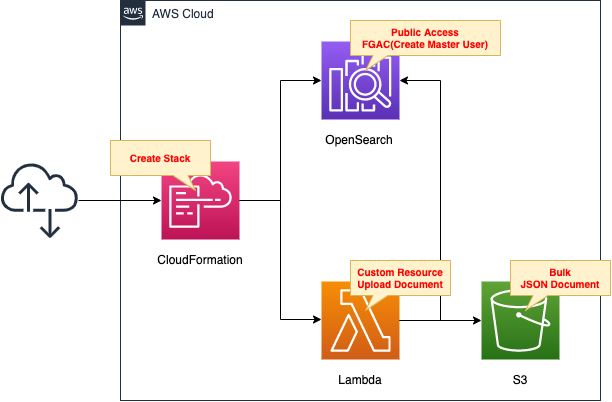
Create a CloudFormation stack and define two resources inside it.
The first is OpenSearch.
This time, we will create a master user and authenticate with the user information.
The second is a Lambda function.
The runtime for the function is Python 3.8.
We will associate this function with a custom resource and set it to run when the stack is created.
The function’s job is to retrieve a JSON file stored in an S3 bucket and upload it to OpenSearch.
The AWS official website details how to upload a JSON file using the curl command.
https://docs.aws.amazon.com/opensearch-service/latest/developerguide/gsgupload-data.html
In this case, we will use the Python module requests to implement file upload.
CloudFormation template files
The above configuration is built using CloudFormation.
The CloudFormation templates are located at the following URL
https://github.com/awstut-an-r/awstut-fa/tree/main/057
Explanation of key points of template files
This article will focus on how to upload files to OpenSearch using custom resources.
For basic information on OpenSearch creation, please refer to the following page

For more information on custom resources, please refer to the following page

Lambda functions for custom resources
Resources:
Function:
Type: AWS::Lambda::Function
Properties:
Environment:
Variables:
BULK_ENDPOINT: !Sub "https://${DomainEndpoint}/_bulk"
BULK_S3_BUCKET: !Ref BulkS3Bucket
BULK_S3_KEY: !Ref BulkS3Key
MASTER_USERNAME: !Ref MasterUserName
MASTER_PASSWORD: !Ref MasterUserPassword
Code:
S3Bucket: !Ref CodeS3Bucket
S3Key: !Ref CodeS3Key
FunctionName: !Sub "${Prefix}-function"
Handler: !Ref Handler
Layers:
- !Ref LambdaLayer
Runtime: !Ref Runtime
Role: !GetAtt FunctionRole.Arn
Timeout: !Ref Timeout
Code language: YAML (yaml)No special configuration is required.
The only point to mention is the setting of environment variables (Environment property).
By setting environment variables, you can pass variables to functions from CloudFormation templates.
In this case, we will define five variables.
BULK_ENDPOINT is the endpoint for uploading documents in the OpenSearch domain.
By adding “/_bulk” to the domain endpoint URL, this URL becomes the upload endpoint.
BULK_S3_BUCKET and BULK_S3_KEY are variables related to the document to be uploaded.
The former is the name of the S3 bucket where the document is located, and the latter is the name (key) of the document.
MASTER_USERNAME and MASTER_PASSWORD are variables related to the OpenSearch master user.
The OpenSearch domain to be created this time will be authenticated by a master user, so these are the user information.
Lambda function code
import boto3
import cfnresponse
import json
import os
import requests
from requests.auth import HTTPBasicAuth
BULK_ENDPOINT = os.environ['BULK_ENDPOINT']
BULK_S3_BUCKET = os.environ['BULK_S3_BUCKET']
BULK_S3_KEY = os.environ['BULK_S3_KEY']
MASTER_USERNAME = os.environ['MASTER_USERNAME']
MASTER_PASSWORD = os.environ['MASTER_PASSWORD']
CREATE = 'Create'
response_data = {}
s3_client = boto3.client('s3')
def lambda_handler(event, context):
try:
if event['RequestType'] == CREATE:
s3_response = s3_client.get_object(
Bucket=BULK_S3_BUCKET,
Key=BULK_S3_KEY)
# binary
bulk = s3_response['Body'].read()
print(bulk)
requests_response = requests.post(
BULK_ENDPOINT,
data=bulk,
auth=HTTPBasicAuth(MASTER_USERNAME, MASTER_PASSWORD),
headers={'Content-Type': 'application/json'}
)
print(requests_response.text)
cfnresponse.send(event, context, cfnresponse.SUCCESS, response_data)
except Exception as e:
print(e)
cfnresponse.send(event, context, cfnresponse.FAILED, response_data)
Code language: Python (python)There are five points.
The first is the cfnresponse module.
This module can be used when a CloudFormation custom resource communicates with a Lambda function.
One point to note is that this module is not included in the default runtime environment if you load packages from S3 buckets when creating a Lambda function.
The details are detailed in the following page, but if you use the ZipFile property to include the code inline in your CloudFormation template, this package is included in the runtime environment and can be imported without any preparation on the part of the user.
Note, however, that if you are creating a Lambda function by referencing a ZIP file located in an S3 bucket, you will need to include this module in the ZIP file or take some other action on your part.
The second point is the acquisition of environment variables.
As we have just confirmed, we have defined environment variables in the CloudFormation template.
In Python, environment variables can be accessed with os.environ.
The third point is the operation content of the CloudFormation stack.
The operations of the stack include “Create”, “Update”, and “Delete”, which can be obtained from event[‘RequestType’].
In this case, we will refer to this value and implement uploading documents to the OpenSearch domain when the stack is created.
The fourth point is how to retrieve documents from the S3 bucket.
After creating a client object for S3 in boto3.client, the document is retrieved using the get_object method.
The fifth method is to upload documents.
As mentioned at the beginning of this section, the AWS official documentation shows how to upload using the curl command, but this time we will use the requests module.
Uploading takes the form of POST a file to the upload endpoint.
There are three points to keep in mind when POST.
First, the file data to be uploaded must be in binary format. Fortunately, when the document is retrieved from the S3 bucket using the get_object method described above, the data will be in binary format, so this should be specified as is.
The second is BASIC authentication. As mentioned earlier, this time authentication is performed using master user information, which is BASIC authentication. Therefore, specify the master user’s user name and password in HTTPBasicAuth.
The third is the header setting: specify “application/json” in the Content-Type header.
IAM role for Lambda function
Resources:
FunctionRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service:
- lambda.amazonaws.com
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Policies:
- PolicyName: !Sub "${Prefix}-S3GetObjectPolicy"
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- s3:GetObject
Resource:
- !Sub "arn:aws:s3:::${BulkS3Bucket}/*"
Code language: YAML (yaml)No special configuration is required.
Documents are retrieved from the S3 bucket, so set up the necessary permissions.
Architecting
Use CloudFormation to build this environment and check the actual behavior.
Prepare documents to be uploaded to the OpenSearch domain
We will use the sample data presented in the official AWS website as is.
{ "index" : { "_index": "movies", "_id" : "2" } }
{"director": "Frankenheimer, John", "genre": ["Drama", "Mystery", "Thriller", "Crime"], "year": 1962, "actor": ["Lansbury, Angela", "Sinatra, Frank", "Leigh, Janet", "Harvey, Laurence", "Silva, Henry", "Frees, Paul", "Gregory, James", "Bissell, Whit", "McGiver, John", "Parrish, Leslie", "Edwards, James", "Flowers, Bess", "Dhiegh, Khigh", "Payne, Julie", "Kleeb, Helen", "Gray, Joe", "Nalder, Reggie", "Stevens, Bert", "Masters, Michael", "Lowell, Tom"], "title": "The Manchurian Candidate"}
{ "index" : { "_index": "movies", "_id" : "3" } }
{"director": "Baird, Stuart", "genre": ["Action", "Crime", "Thriller"], "year": 1998, "actor": ["Downey Jr., Robert", "Jones, Tommy Lee", "Snipes, Wesley", "Pantoliano, Joe", "Jacob, Ir\u00e8ne", "Nelligan, Kate", "Roebuck, Daniel", "Malahide, Patrick", "Richardson, LaTanya", "Wood, Tom", "Kosik, Thomas", "Stellate, Nick", "Minkoff, Robert", "Brown, Spitfire", "Foster, Reese", "Spielbauer, Bruce", "Mukherji, Kevin", "Cray, Ed", "Fordham, David", "Jett, Charlie"], "title": "U.S. Marshals"}
{ "index" : { "_index": "movies", "_id" : "4" } }
{"director": "Ray, Nicholas", "genre": ["Drama", "Romance"], "year": 1955, "actor": ["Hopper, Dennis", "Wood, Natalie", "Dean, James", "Mineo, Sal", "Backus, Jim", "Platt, Edward", "Ray, Nicholas", "Hopper, William", "Allen, Corey", "Birch, Paul", "Hudson, Rochelle", "Doran, Ann", "Hicks, Chuck", "Leigh, Nelson", "Williams, Robert", "Wessel, Dick", "Bryar, Paul", "Sessions, Almira", "McMahon, David", "Peters Jr., House"], "title": "Rebel Without a Cause"}
Code language: plaintext (plaintext)Save this data as a file named bulk_movies.json and store it in the given S3 bucket.
In this case, the data will be placed in the same bucket as the CloudFormation template file described below.
Prepare deployment package for Lambda function
There are three ways to create a Lambda function.
In this case, we will choose the method of uploading the deployment package to the S3 bucket.
For more information, please refer to the following page

Prepare deployment package for Lambda layer
Prepare the aforementioned requests module as a Lambda layer.
For more information on the Lambda layer, please refer to the following page

The command to create a package for the Lambda layer is as follows
$ sudo pip3 install requests -t python
$ zip -r layer.zip python
Code language: Bash (bash)We will also include the cfnresponse module mentioned earlier in the Lambda layer.
Create CloudFormation stacks and check resources in stacks
Create a CloudFormation stack using AWS CLI.
This configuration consists of four separate template files, which are placed in an arbitrary bucket.
The following is an example of creating a stack by referencing a template file placed in an arbitrary S3 bucket.
The stack name is “fa-057”, the bucket name is “awstut-bucket”, and the folder name where the files are placed is “fa-057”.
$ aws cloudformation create-stack \
--stack-name fa-057 \
--template-url https://awstut-bucket.s3.ap-northeast-1.amazonaws.com/fa-057/fa-057.yaml \
--capabilities CAPABILITY_IAM
Code language: Bash (bash)For more information on CloudFormation’s nested stacks, please refer to the following page

After reviewing the resources in each stack, the following is the information on the main resources created in this case
- OpenSearch domain name: fa-057
- OpenSearch domain endpoint URL: https://search-fa-057-yzh3wx3anuc2iwplmwaime3ej4.ap-northeast-1.es.amazonaws.com/
- Master user name: test
- Master user password: P@ssw0rd
Check the stack creation status from the AWS Management Console.
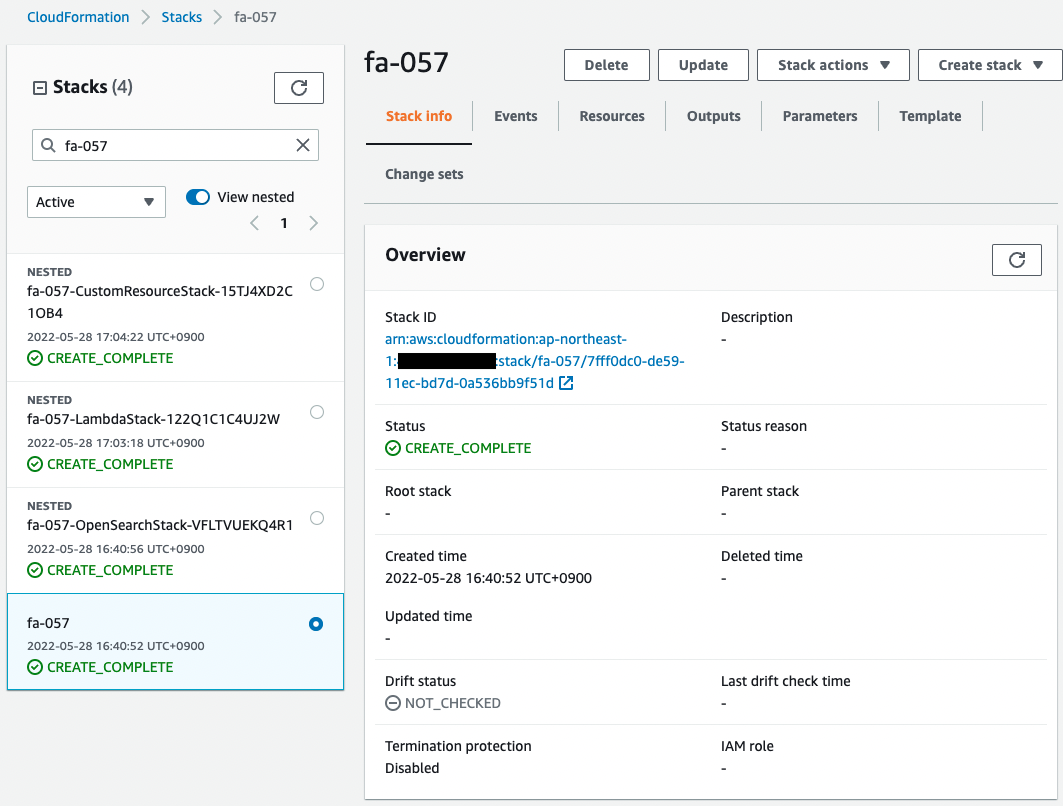
You can see that the stack created by the command and three stacks nested in this stack have been created.
Of the nested stacks, check the resources created from the stack for OpenSearch.
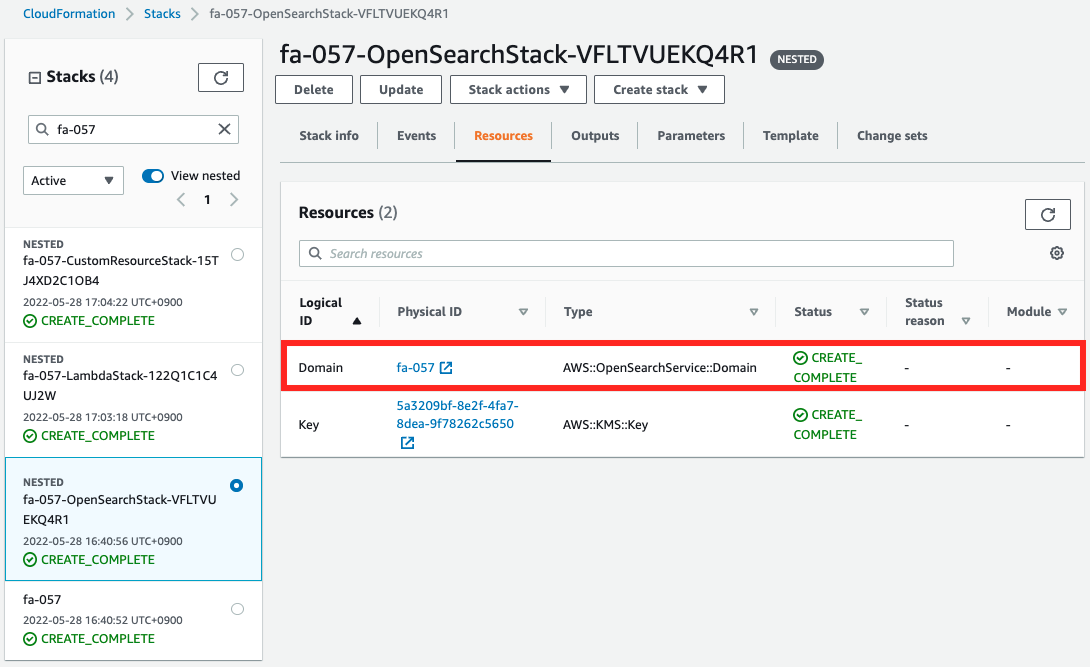
Indeed, an OpenSearch domain has been created.
Next, we check the custom resources and Lambda functions.
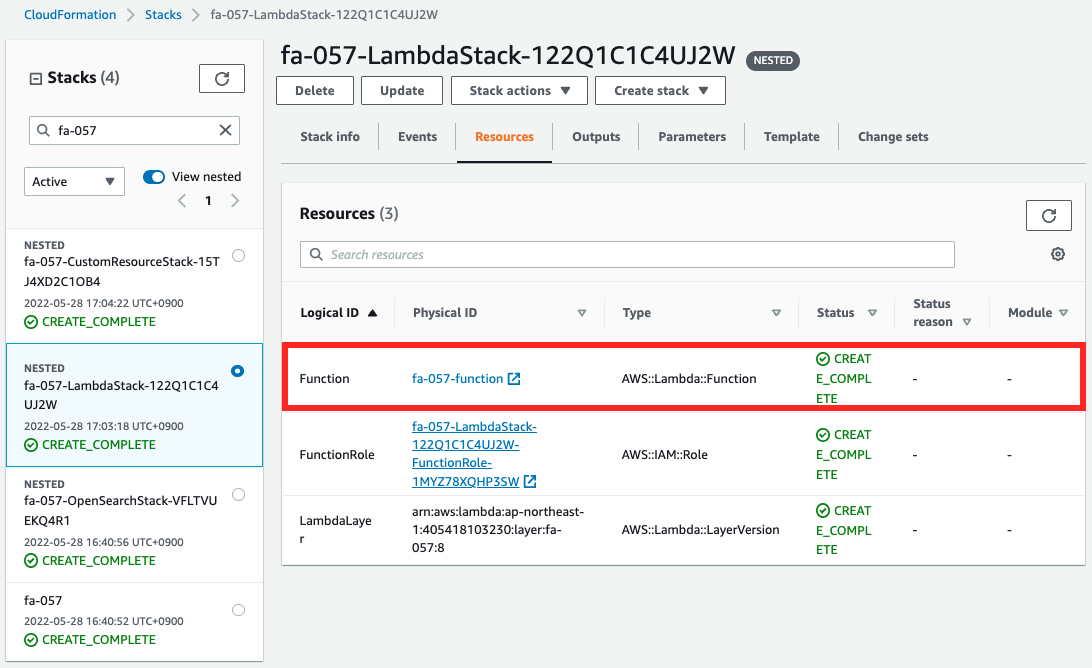
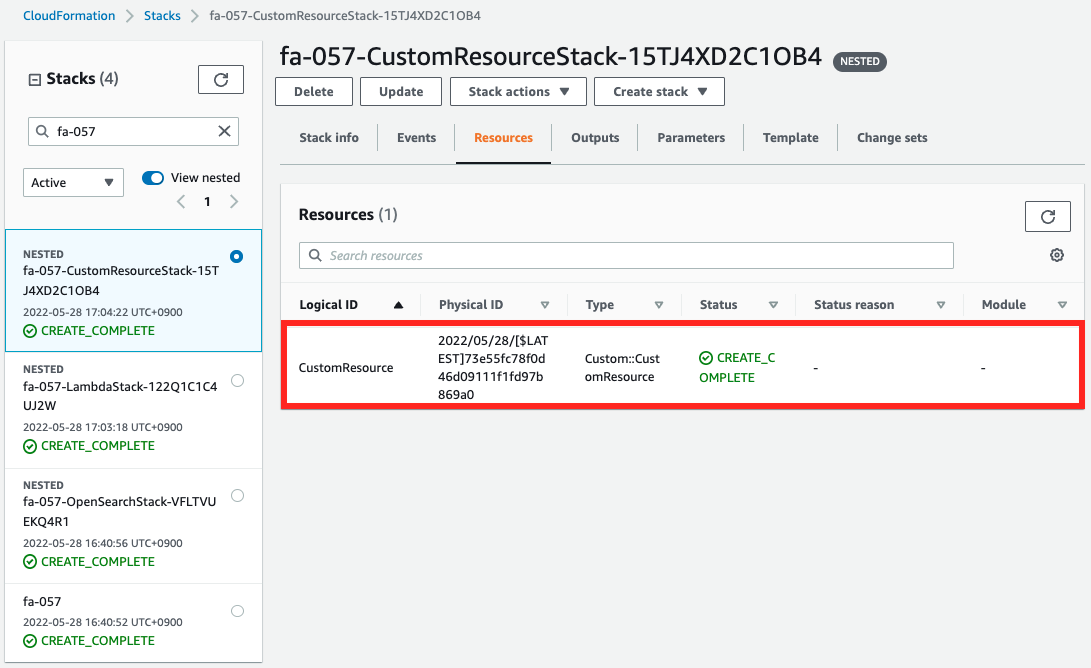
Both are created.
If they are working properly, documents should be uploaded toward the OpenSearch domain when the stack is created.
Checking Action
Now that we are ready, let’s run a search against the OpenSearch domain.
$ curl -XGET -u 'test:P@ssw0rd' 'https://search-fa-057-yzh3wx3anuc2iwplmwaime3ej4.ap-northeast-1.es.amazonaws.com/movies/_search?q=Bryar&pretty=true'
{
"took" : 162,
"timed_out" : false,
"_shards" : {
"total" : 5,
"successful" : 5,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 1,
"relation" : "eq"
},
"max_score" : 0.29058143,
"hits" : [
{
"_index" : "movies",
"_type" : "_doc",
"_id" : "4",
"_score" : 0.29058143,
"_source" : {
"director" : "Ray, Nicholas",
"genre" : [
"Drama",
"Romance"
],
"year" : 1955,
"actor" : [
"Hopper, Dennis",
"Wood, Natalie",
"Dean, James",
"Mineo, Sal",
"Backus, Jim",
"Platt, Edward",
"Ray, Nicholas",
"Hopper, William",
"Allen, Corey",
"Birch, Paul",
"Hudson, Rochelle",
"Doran, Ann",
"Hicks, Chuck",
"Leigh, Nelson",
"Williams, Robert",
"Wessel, Dick",
"Bryar, Paul",
"Sessions, Almira",
"McMahon, David",
"Peters Jr., House"
],
"title" : "Rebel Without a Cause"
}
}
]
}
}
Code language: Bash (bash)The search was successfully executed.
The search for the word “Bryar” yielded the string “Rebel Without a Cause” with a _score of 0.29058143.
This means that the Lambda function was executed by the custom resource, the JSON file was uploaded, and the index was created in the OpenSearch domain.
In case you are interested, check the CloudWatch Logs for the Lambda function.
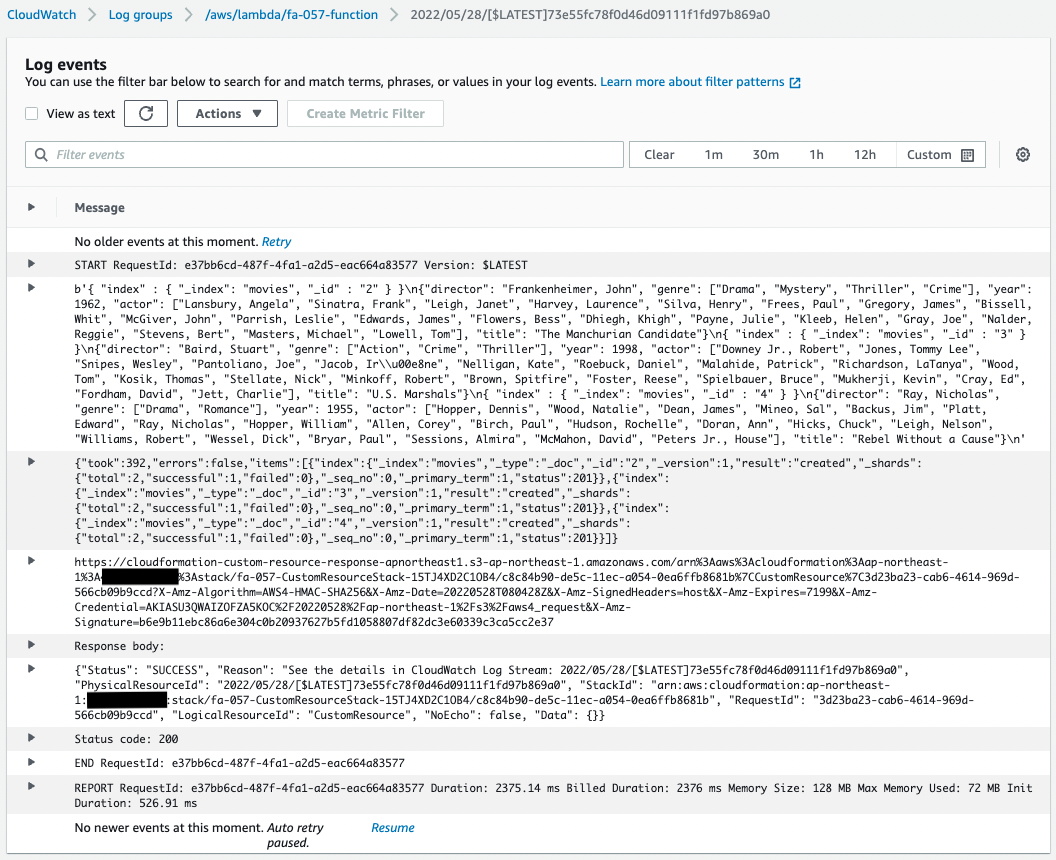
You can see that the function was executed in conjunction with a custom resource.
Summary
We have confirmed how to use a custom resource to automatically upload and index a JSON file located in an S3 bucket when an OpenSearch domain is created.