Configuring Lambda as Data Source for AppSync
AppSync allows you to select a data source from the following services
- Lambda
- DynamoDB
- OpenSearch
- None
- HTTP endpoint
- RDS
This time, we will check the configuration with Lambda as the data source.
For a basic explanation of AppSync and the configuration with DynamoDB as the data source, please refer to the following page.

Environment
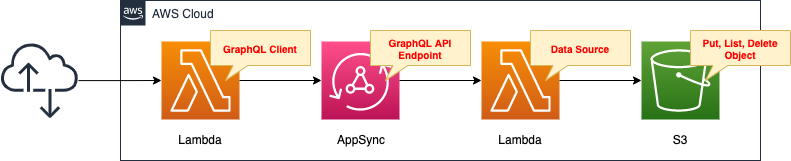
Define a Lambda function that operates as a data source.
Lambda functions are defined to manipulate objects in S3 buckets.
Specifically, there are three types of functions
- Put: Create a new object in the S3 bucket.
- List: Obtain a list of objects in the S3 bucket.
- Delete: Delete an object in the S3 bucket by specifying a key (object name).
AppSync defines a schema resolver to enable the above three operations.
Create another Lambda function as a client to execute the GraphQL API by AppSync.
Enable the Function URL so that the URL query parameter can specify the operation to be performed.
We will create two Lambda functions, both in Python 3.8.
CloudFormation template files
The above configuration is built using CloudFormation.
The CloudFormation template is located at the following URL
https://github.com/awstut-an-r/awstut-fa/tree/main/044
Explanation of key points of template files
AppSync with Lambda as data source
Data Source
Resources:
DataSource:
Type: AWS::AppSync::DataSource
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
LambdaConfig:
LambdaFunctionArn: !Ref FunctionArn
Name: DataSource
ServiceRoleArn: !GetAtt DataSourceRole.Arn
Type: AWS_LAMBDA
Code language: YAML (yaml)There are two key points.
The first is the Type property.
When Lambda is used as the data source, specify “AWS_LAMBDA”.
The second is the LambdaConfig property.
Set the ARN of the Lambda function to be set as the data source to the LambdaFunctionArn property.
Schema
Resources:
GraphQLSchema:
Type: AWS::AppSync::GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
Definition: |
schema {
query: Query
mutation: Mutation
}
type Query {
listS3Objects: [S3Object]
}
type Mutation {
putS3Object: S3Object
deleteS3Object(Key: String!): S3Object
}
type S3Object {
Key: String!
LastModified: String
Size: Int
ETag: String
}
Code language: YAML (yaml)No special configuration is required to use Lambda as the data source.
Define the schema as usual.
As mentioned above, we will implement three processes for S3 buckets, so define the schema accordingly.
Resolver
As confirmed in the schema, we will define a total of three query mutations.
As a representative example, we will cover the mutation to delete an object in the S3 bucket (deleteS3Object).
Resources:
DeleteS3ObjectResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: deleteS3Object
Kind: UNIT
RequestMappingTemplate: |
{
"version": "2018-05-29",
"operation": "Invoke",
"payload": {
"field": "Delete",
"arguments": $utils.toJson($context.arguments)
}
}
ResponseMappingTemplate: |
$context.result
TypeName: Mutation
Code language: YAML (yaml)The key points are the request mapping (RequestMappingTemplate property) and response mapping (ResponseMappingTemplate property).
For more information on these specifications, please refer to the following page.
https://docs.aws.amazon.com/appsync/latest/devguide/resolver-mapping-template-reference-lambda.html
Request Mapping
This is a setting related to the data to be passed when executing a data source Lambda function from AppSync.
Either of two values can be set for the operation.
The Lambda data source lets you define two operations: Invoke and BatchInvoke.
Resolver mapping template reference for Lambda
In this case, we will specify Invoke.
You can pass data to a Lambda function by defining a payload.
The payload field is a container that you can use to pass any well-formed JSON to the Lambda function.
Resolver mapping template reference for Lambda
In this case, we define two values to be passed to the Lambda function.
- field: a value indicating the operation to be performed by the data source Lambda function, either Put, List, or Delete.
- arguments: Arguments for the mutation execution. Arguments can be obtained in $context.arguments, which is converted to JSON using $utils.toJson and passed.
Response Mapping
This setting is for AppSync to receive the values returned from the data source Lambda function.
The result of the Lambda function execution can be obtained with $context.result.
The key point is that the results must be returned in JSON format.
In other words, the object must be converted to JSON either on the Lambda function side or on the response mapping side.
In this case, JSON is converted on the function side.
If you want to convert the object to JSON on the response mapping side, you can use $utils.toJson as described above.
IAM role for AppSync
Resources:
DataSourceRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service: appsync.amazonaws.com
Policies:
- PolicyName: !Sub "${Prefix}-DataSourcePolicy"
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- lambda:InvokeFunction
Resource:
- !Ref FunctionArn
Code language: YAML (yaml)Permission is granted for AppSync to execute a Lambda function that is set as a data source.
Data source Lambda function
import boto3
import json
import os
from datetime import date, datetime
bucket_name = os.environ['BUCKET_NAME']
s3_client = boto3.client('s3')
PUT = 'Put'
LIST = 'List'
DELETE = 'Delete'
def json_serial(obj):
# reference: https://www.yoheim.net/blog.php?q=20170703
if isinstance(obj, (datetime, date)):
return obj.isoformat()
raise TypeError ("Type %s not serializable" % type(obj))
def lambda_handler(event, context):
if event['field'] == PUT:
now = datetime.now()
now_str = now.strftime('%Y%m%d%H%M%S')
key = "{datetime}.txt".format(datetime=now_str)
put_response = s3_client.put_object(
Bucket=bucket_name,
Key=key,
Body=now_str.encode())
get_response = s3_client.get_object(
Bucket=bucket_name, Key=key)
object_ = {
'Key': key,
'LastModified': get_response['LastModified'],
'Size': get_response['ContentLength'],
'ETtag': get_response['ETag']
}
return json.dumps(object_, default=json_serial)
elif event['field'] == LIST:
list_response = s3_client.list_objects_v2(
Bucket=bucket_name)
objects = list_response['Contents']
return json.dumps(objects, default=json_serial)
elif event['field'] == DELETE:
key = event['arguments']['Key']
delete_response = s3_client.delete_object(
Bucket=bucket_name, Key=key)
object_ = {
'Key': key
}
return json.dumps(object_, default=json_serial)
Code language: Python (python)There are two points.
The first is how to receive the values set in the request mapping.
In Python, they are stored in the event object.
When receiving the value of a field, it becomes event[‘field’], and when receiving arguments, it becomes event[‘arguments’].
The second point is the value to be returned.
As mentioned above, the value returned by a function must be converted to JSON either on the function side or on the response mapping side.
For this reason, the values returned by the function are converted to JSON on the function side.
In addition, referring to the following site, we have prepared a function to enable serialization of datetime objects when converting to JSON with json.dumps.
https://www.yoheim.net/blog.php?q=20170703
With the above in mind, here is a summary of the code.
- Refer to the value of field to determine the query content requested in the GraphQL query.
In the case of *Delete, reference the name (key) of the object to be deleted from the argument. - Operate the S3 bucket according to the contents of the request.
- The result of the operation is converted to JSON and returned in the response mapping.
(Reference) GraphQL client Lambda function
import json
import os
import time
from gql import Client, gql
from gql.transport.aiohttp import AIOHTTPTransport
api_key = os.environ['API_KEY']
graphql_url = os.environ['GRAPHQL_URL']
transport = AIOHTTPTransport(
url=graphql_url,
headers={
'x-api-key': api_key
})
client = Client(transport=transport, fetch_schema_from_transport=True)
PUT = 'Put'
LIST = 'List'
DELETE = 'Delete'
def lambda_handler(event, context):
field = ''
document = None
result = None
if not 'queryStringParameters' in event or (
not 'field' in event['queryStringParameters']):
field = LIST
else:
field = event['queryStringParameters']['field']
if field == PUT:
document = gql(
"""
mutation PutS3ObjectMutation {
putS3Object {
Key
LastModified
Size
ETag
}
}
"""
)
result = client.execute(document)
elif field == LIST:
document = gql(
"""
query ListS3ObjectsQuery {
listS3Objects {
Key
}
}
"""
)
result = client.execute(document)
elif field == DELETE:
object_name = event['queryStringParameters']['object_name']
document = gql(
"""
mutation DeleteS3ObjectsMutation($object_name: String!) {
deleteS3Object(Key: $object_name) {
Key
}
}
"""
)
params = {
'object_name': object_name
}
result = client.execute(document, variable_values=params)
return {
'statusCode': 200,
'body': json.dumps(result, indent=2)
}
Code language: Python (python)Lambda function to execute a GraphQL query.
In this case, we will use GQL as the GraphQL client library for Python.
https://github.com/graphql-python/gql
In Python, URL query parameters can be retrieved by event[‘queryStringParameters’].
Pass the required parameters in the URL query parameters.
- field: The operation to perform.
- object_name: Required if the operation is Delete. The name of the object to delete (key).
Architecting
Use CloudFormation to build this environment and check the actual behavior.
Prepare deployment package for Lambda function
There are three ways to create a Lambda function.
In this case, we will choose the method of uploading a deployment package to an S3 bucket.
For more information, please refer to the following page

Prepare deployment package for Lambda layer
Prepare the aforementioned GQL as a Lambda layer.
For more information on the Lambda layer, please refer to the following page

The command to create a package for the Lambda layer is as follows
$ sudo pip3 install --pre gql[all] -t python
$ zip -r layer.zip python
Code language: Bash (bash)Create CloudFormation stacks and check resources in stacks
Create a CloudFormation stack.
For information on how to create stacks and check each stack, please refer to the following page

After checking the resources in each stack, information on the main resources created this time is as follows
- S3 bucket: fa-044
- AppSync API: fa-044-GraphQLApi
- Lambda function for data source: fa-044-function-01
- Function URL for GraphQL client Lambda function: https://khty5dwgudjyl6otndvxm3uora0hemhk.lambda-url.ap-northeast-1.on.aws
From the AWS Management Console, check AppSync.
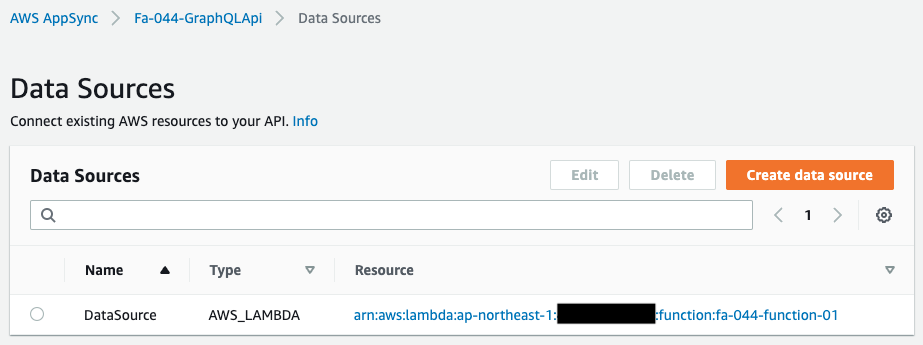
You can see that the Lambda function is registered as a data source.
Confirmation of Operation
Now that everything is ready, access the Function URL of the GraphQL client Lambda function.
The first operation is to add an object to the S3 bucket (Put).
Specify “Put” as the value of field in the URL query.

The putS3Object mutation is executed.
The result of the execution is displayed.
Execute it one more time for the next operation.
The next operation (List) is to obtain a list of objects stored in the S3 bucket.

The listS3Objects query has been executed.
As specified in the query, only the Key was returned.
By the way, the status of the S3 bucket is as shown in the following image.
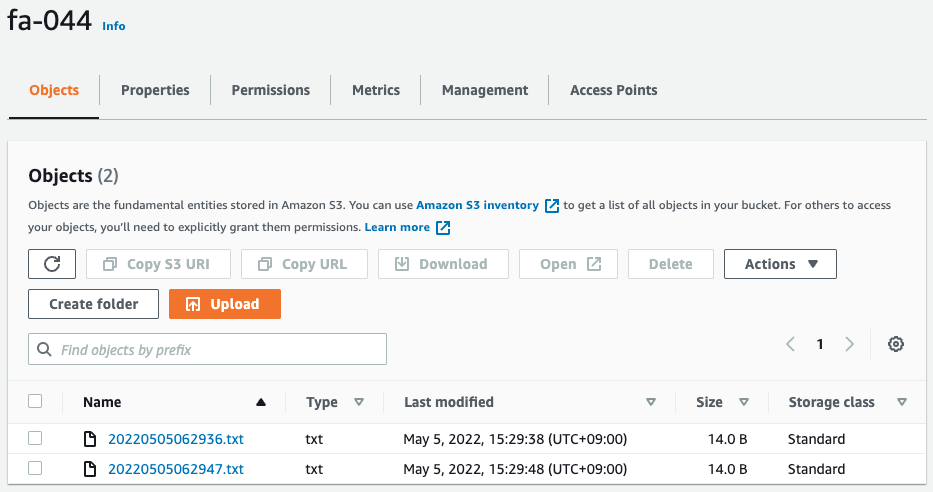
Indeed, two objects are stored.
The next operation is to delete an object in the S3 bucket (Delete).
Add the object name (key) of the object to be deleted to the parameter.

The deleteS3Object mutation has been executed.
It has been successfully executed and the key of the deleted object has been returned.
Check the list again.

There is now only one.
We can see that the object was indeed deleted in the previous operation.
Summary
We have introduced the configuration of setting a Lambda function to AppSync data source.