Real-time analysis of streaming data with Kinesis Data Analytics
In this introduction to Kinesis Data Analytics, we will actually build and verify the configuration introduced in the AWS official website.
Environment
The streaming data to be used for analysis will be generated by a Lambda function. The script to be executed by the function will be created based on the Python code introduced in the official website mentioned above.
The script will generate data that represents an image of a stock price, and the data generated by the Lambda function will be captured by Kinesis Data Stream. The data captured by Kinesis Data Stream is filtered in real-time by Kinesis Data Analytics. The data captured by Kinesis Data Stream is filtered in real-time by Kinesis Data Analytics, which is SQL-based.
As for the specific validation scenario, the stock price data generated by the Lambda function will be for the following five tickers
- AAPL
- AMZN
- MSFT
- INTC
- TBV
Choose one of these numbers and randomly generate a number that represents the stock price.
In this case, we will generate the above data for 100 numbers and use Kinesis Data Analytics to extract only the “AAPL” data from them.
CloudFormation Template Files
We will build the above configuration using CloudFormation. The CloudFormation template file is available at the following URL.
https://github.com/awstut-an-r/awstut-saa/tree/main/04/001
Explanation of key points of template files
We will cover the key points of each template file to configure this architecture.
Generating data for Kinesis validation with Lambda function
Create a Lambda-related resource in saa-04-001-lambda.yaml.
Resources:
DataSourceLambda:
Type: AWS::Lambda::Function
Properties:
Environment:
Variables:
KINESIS_STREAM_NAME: !Ref KinesisDataStreamName
Runtime: python3.8
Role: !GetAtt DataSourceLambdaRole.Arn
Timeout: !Ref Timeout
Handler: index.lambda_handler
Code:
ZipFile: |
...
Code language: YAML (yaml)In the Environment property, you can set the environment variable to be passed to the function. In the Code property, you can set the script to be executed in the function. For more information on the Lmabda function, please refer to the following page.

Define the function to generate the stock price data inline. In this case, we will prepare stock price data for 100 stocks, and this function will generate the data for one of them.
def get_data():
return {
'EVENT_TIME': datetime.datetime.now().isoformat(),
'TICKER': random.choice(['AAPL', 'AMZN', 'MSFT', 'INTC', 'TBV']),
'PRICE': round(random.random() * 100, 2)}
Code language: Python (python)The data consists of the following three pieces of information
- EVENT_TIME: The current date and time.
- TICKER: Ticker of the issue. Pick one of five stocks at random.
- PRICE: Stock price. Generated randomly.
Call the above function to deliver the data to Kinesis Data Stream sequentially.
STREAM_NAME = os.environ['KINESIS_STREAM_NAME']
LIMIT = 100
def generate(stream_name, kinesis_client, limit):
for i in range(limit):
data = get_data()
print(data)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data).encode('utf-8'),
PartitionKey="partitionkey")
def lambda_handler(event, context):
generate(STREAM_NAME, boto3.client('kinesis'), LIMIT)
Code language: Python (python)Call the put_record method to deliver it to Kinesis Data Stream. As arguments, pass the destination stream name, JSONized stock price data, and partition key. The stream name is obtained by referring to an environment variable.
The key point is the partition key. The partition key is a parameter used to determine the shard to be delivered.
A partition key is used to group data by shard within a stream. Kinesis Data Streams segregates the data records belonging to a stream into multiple shards. It uses the partition key that is associated with each data record to determine which shard a given data record belongs to.
Amazon Kinesis Data Streams Terminology and Concepts
When you create multiple shards in Kinesis Data Stream, you need to set the partition key to avoid bias in the shard to be distributed. Since this is a hands-on session, we will specify the string “partitionkey” in a unified manner to set the number of shards to 1, as described below.
In order to deliver data to Kinesis Data Streams, grant kinesis:PutRecord permission
Define the IAM role for the Lambda function.
Resources:
DataSourceLambdaRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service:
- lambda.amazonaws.com
Policies:
- PolicyName: PutRecordIntoKinesisDataStream
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- kinesis:PutRecord
Resource:
- !Ref KinesisDataStreamArn
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Code language: YAML (yaml)The key point is the action to be allowed by the inline policy in the IAM role. kinesis:PutRecord is the permission required to deliver data to Kinesis Data Streams. Specify the same action in the Action property. As the destination, specify the ARN of the Kinesis Data Streams stream in the Resource property.
Throughput of Kinesis Data Streams is determined by number of shards
Define the Kinesis-related resources in saa-04-001-kinesis.yaml. First, we will define Kinesis Data Stream that will capture the data generated by the Lambda function described below.
Resources:
KinesisDataStream:
Type: AWS::Kinesis::Stream
Properties:
Name: KinesisDataStream
ShardCount: 1
Code language: YAML (yaml)An important parameter in Kinesis Data Stream is the shard. Shards are set by the ShardCount property. The shard determines the throughput of Kinesis Data Stream.
A shard is a uniquely identified sequence of data records in a stream. A stream is composed of one or more shards, each of which provides a fixed unit of capacity. Each shard can support up to 5 transactions per second for reads, up to a maximum total data read rate of 2 MB per second and up to 1,000 records per second for writes, up to a maximum total data write rate of 1 MB per second (including partition keys). The data capacity of your stream is a function of the number of shards that you specify for the stream. The total capacity of the stream is the sum of the capacities of its shards.
Amazon Kinesis Data Streams Terminology and Concepts
In other words, by increasing the number of shards, you can increase the overall throughput of Kinesis Data Streams. In this case, we will set the minimum number of shards to “1” as mentioned earlier for verification.
Kinesis Data Analytics Terms
Before we check the specific contents of the template file, let’s review the terminology related to Kinesis Data Analytics.
The streaming data to be processed by Kinesis Data Analytics is called the streaming source. When you launch Kinesis Data Analytics, an in-application stream will be generated.
When you start the application, Kinesis Data Analytics creates the specified in-application stream. In your application code, you access the in-application stream using this name.
Configuring Application Input
This means that the data to be processed by Kinesis Data Analytics is not the streaming data itself, such as Kinesis Data Streams, but the in-application stream generated by Kinesis Data Analytics.
There is a limit to the speed at which a single in-application stream can be processed.
The most throughput we recommend for a single in-application stream is between 2 and 20 MB/second, depending on the complexity of the application’s query.
Limits
If more performance is required, multiple in-application stream can be created.
You can optionally map a streaming source to multiple in-application streams… In this case, Amazon Kinesis Data Analytics creates the specified number of in-application streams with names as follows: prefix_001, prefix_002, and prefix_003. By default, Kinesis Data Analytics maps the streaming source to one in-application stream named prefix_001.
Configuring Application Input
As described above, in-application stream will be created automatically, but you can also create them manually in addition to the ones created by default.
You can also create more in-application streams as needed to store intermediate query results.
In-Application Streams and Pumps
In order to use a manually created in-application stream, you need to pump data from the default in-application stream.
A pump is a continuous insert query running that inserts data from one in-application stream to another in-application stream.
In-Application Streams and Pumps
Kinesis Data Analytics can filter streaming data with SQL
Now that we know the terminology, let’s check out the actual definition of Kinesis Data Analytics.
Resources:
KinesisDataAnalytics:
Type: AWS::KinesisAnalytics::Application
Properties:
ApplicationName: !Sub "${Prefix}-application"
ApplicationDescription: sample application.
ApplicationCode:
!Sub |
CREATE OR REPLACE STREAM "DESTINATION_SQL_STREAM" (event_time VARCHAR(20), ticker VARCHAR(5), price REAL);
CREATE OR REPLACE PUMP "STREAM_PUMP" AS INSERT INTO "DESTINATION_SQL_STREAM"
SELECT STREAM event_time, ticker, price
FROM "${NamePrefix}_001"
WHERE ticker = 'AAPL';
Inputs:
- NamePrefix: !Ref NamePrefix
InputSchema:
RecordColumns:
- Name: EVENT_TIME
SqlType: VARCHAR(20)
Mapping: $.EVENT_TIME
- Name: TICKER
SqlType: VARCHAR(5)
Mapping: $.TICKER
- Name: PRICE
SqlType: REAL
Mapping: $.PRICE
RecordFormat:
RecordFormatType: JSON
MappingParameters:
JSONMappingParameters:
RecordRowPath: $
KinesisStreamsInput:
ResourceARN: !GetAtt KinesisDataStream.Arn
RoleARN: !GetAtt KinesisAnalyticsRole.Arn
Code language: YAML (yaml)Configure the settings related to the streaming source in the Inputs property.
In the NamePrefix property, specify the prefix of the stream in the application that will be automatically created. As mentioned earlier, the stream name will be given a numeric suffix, so the stream name to be created this time will be “SAMPLE_APP_001”.
Specify the streaming source in the KinesisStreamsInput property, the ARN of the predefined Kinesis Data Streams stream in the ResourceARN property, and the permissions required to access the stream in the RoleARN property. In the RoleARN property, specify the ARN of the IAM role that summarizes the permissions required to access the stream.
The RecordFormat property specifies the format of the data to be received from the streaming source. In the MappingParameters property, define a variable that represents a single data for the parameter mapping described below. In this case, we will use “$” to indicate one data.
In the RecordColumns property, define the mapping between the elements in the data received from the streaming source and the columns inside the stream in the application. Since we have three pieces of information (date, time, ticker, stock price) in one data set, we will assign them with three properties: Name property is the column to be created in the intra-application stream, SqlType property is the type of the column. The SqlType property is the type of the column, as detailed in Data Types, but in this case we will use VARCHAR for strings and REAL for numbers. In the Mapping property, specify the source data that the column refers to, using the mapping variable “$” mentioned earlier.
Define the SQL to be executed in the ApplicationCode property.
Create a new in-application stream “DESTINATION_SQL_STREAM” with the “CREATE OR REPLACE STREAM” statement in the first line. Define three columns as well as the default in-application stream “SAMPLE_APP_001”.
In the second line, “CREATE OR REPLACE PUMP” statement, create a pump. We will create a pump named “STREAM_PUMP”. The pump will be used to link data between streams in the application. In this case, we will specify to link to the “DESTINATION_SQL_STREAM” that we just created.
Specify the column to be linked by the pump and the source of the linkage in lines 3~5. In this case, we will specify “SAMPLE_APP_001” as the source stream in the FROM clause, and specify three columns to be passed to “DESTINATION_SQL_STREAM”. In addition, in the WHERE clause, we will specify to extract the data whose ticker name is “AAPL”.
Architecting
We will use CloudFormation to build this environment and check the actual behavior.
Create CloudFormation stacks and check resources in stacks
We will create a CloudFormation stack.
For information on how to create a stack and check each stack, please refer to the following page

After checking the resources in each stack, here is the information on the main resources created this time
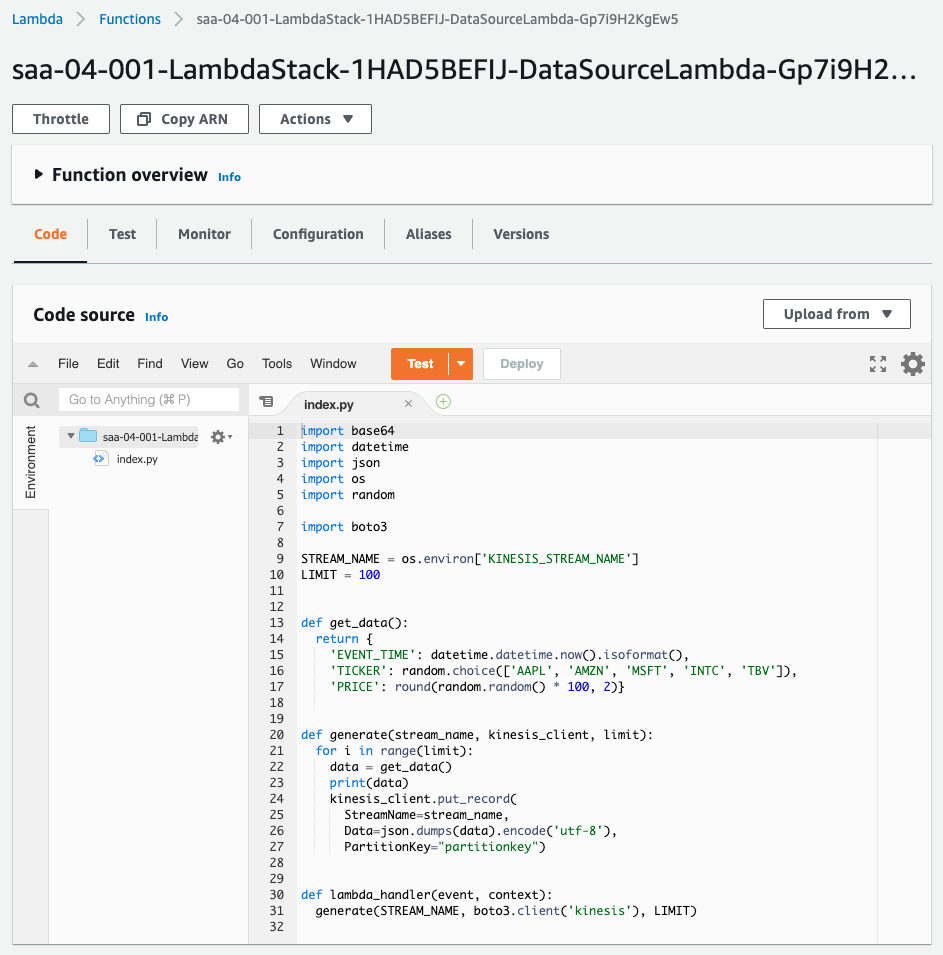
- Lambda function: saa-04-001-LambdaStack-1HAD5BEFIJ-DataSourceLambda-Gp7i9H2KgEw5
- Kinesis Data Stream: KinesisDataStream
- Kinesis Data Analytics: saa-04-001-application
We will also check the creation status of the resources from the AWS Management Console. First, check the creation status of the Lambda function.
Next, we will check the Kinesis Data Stream.
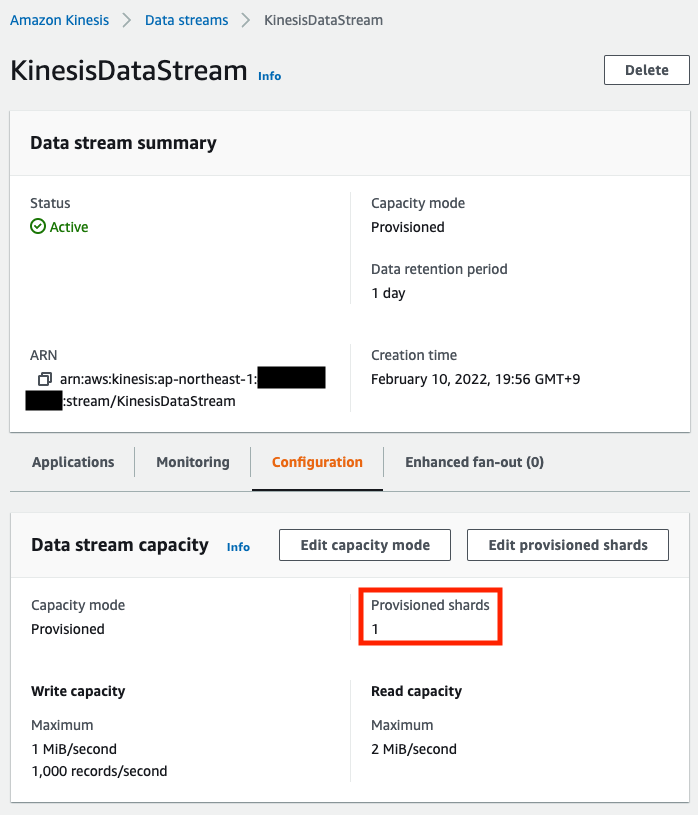
The stream has been created with the setting of one shard, so it has been created as specified in the template file. Finally, check the Kinesis Data Analytics.
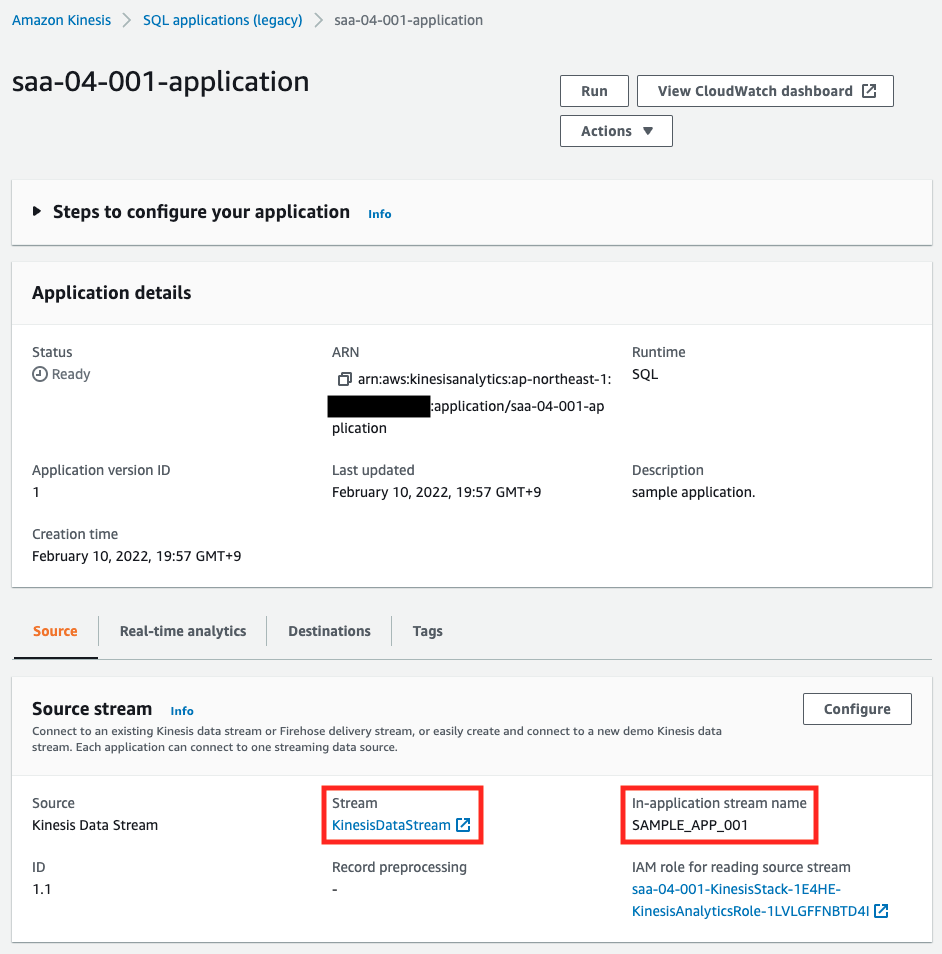
You can see that the source is the aforementioned stream and the stream name in the application is “SAMPLE_APP_001”. This is as specified.
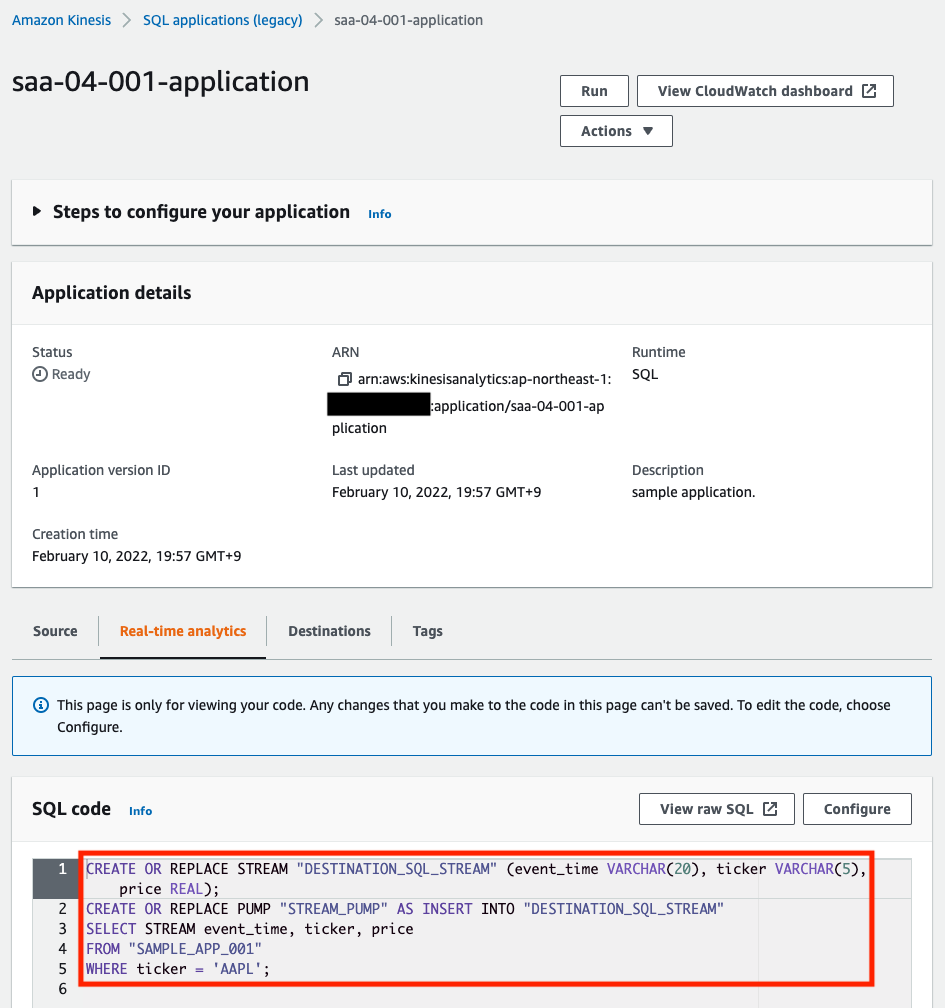
You can see that the SQL for filtering is also set as specified.
Running Kinesis Data Analytics App
To start the verification, we will launch the Kinesis Data Analytics application. We will also run it from the AWS Management Console.

Click on the “Run” button.
A confirmation popup will appear, click “Run”.
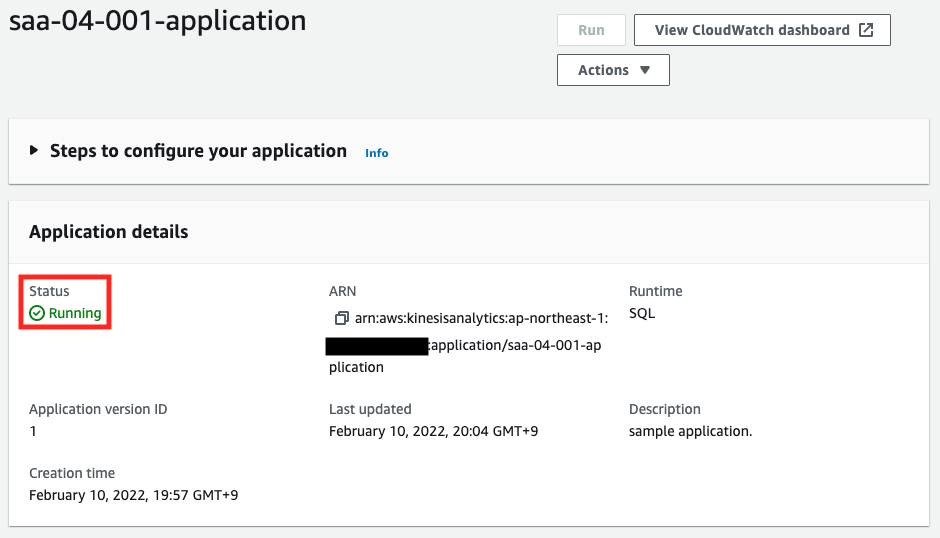
After waiting for a while, the status will change to “Running”. The Kinesis Data Analytics application is now running. Next, access the Real-time analytics page.
Click “Configure” under the “Real-time analytics” tab.
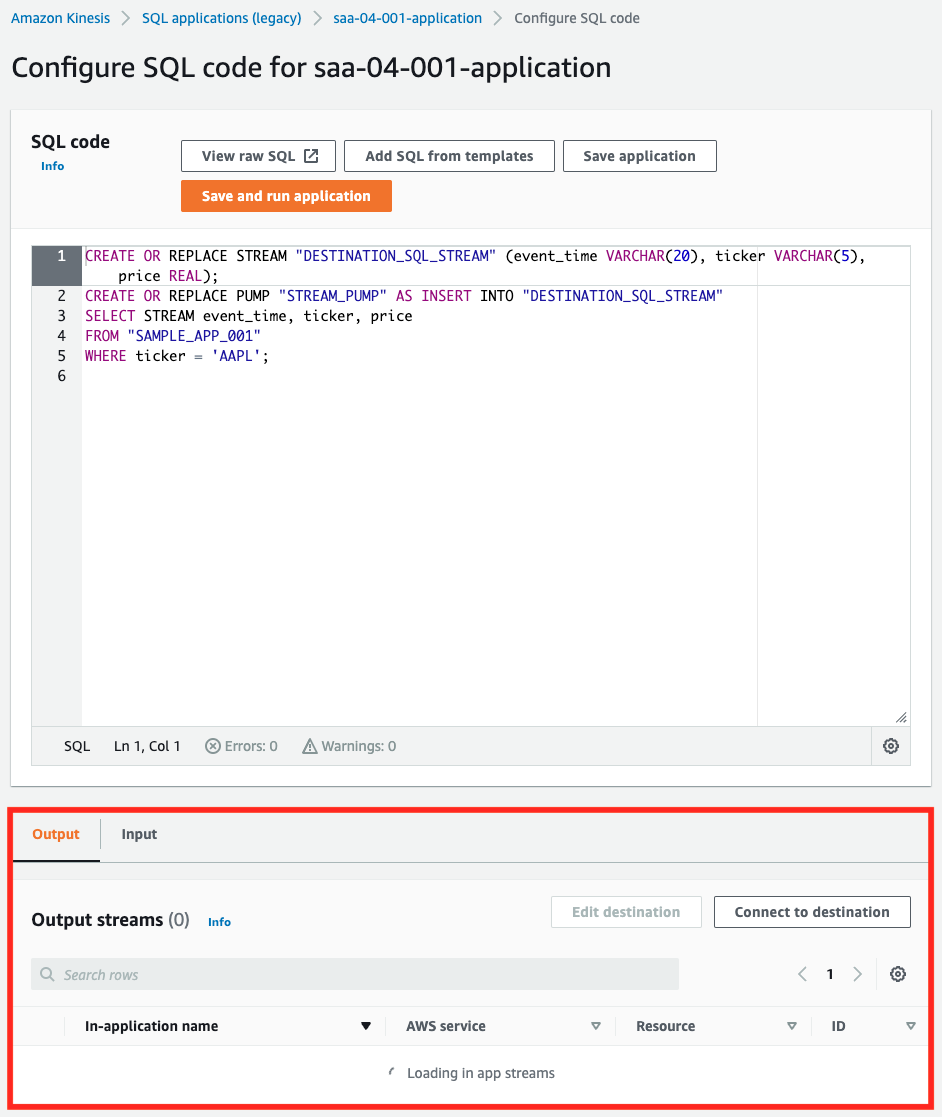
At the bottom of the page, you can see the data flowing in the stream and the results filtered by SQL.
Run Lambda to send the validation data to the Kinesis Data Stream
Now that everything is ready, let’s start the validation. Let’s run Lambda.
Press “Test” in the “Test” tab. The test event can be anything, but this time I selected the default “hello-world” and ran it. Immediately after the execution, check the real-time analysis page of Kinesis Data Analytics.
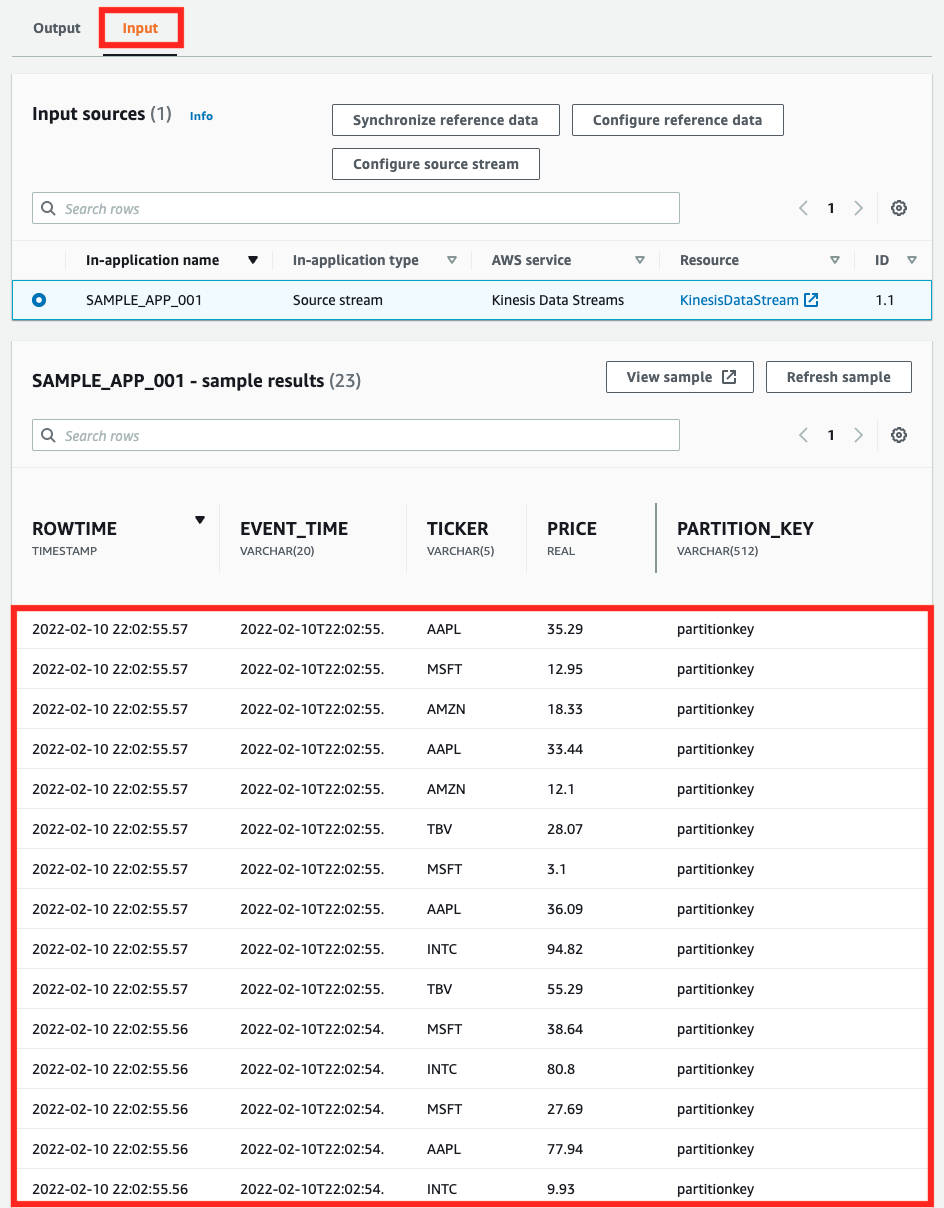
In the “Input” tab, we can see the test data sent from Lambda. Next, let’s check the “Output” tab. After selecting the “Output” tab, execute the Lambda function again.
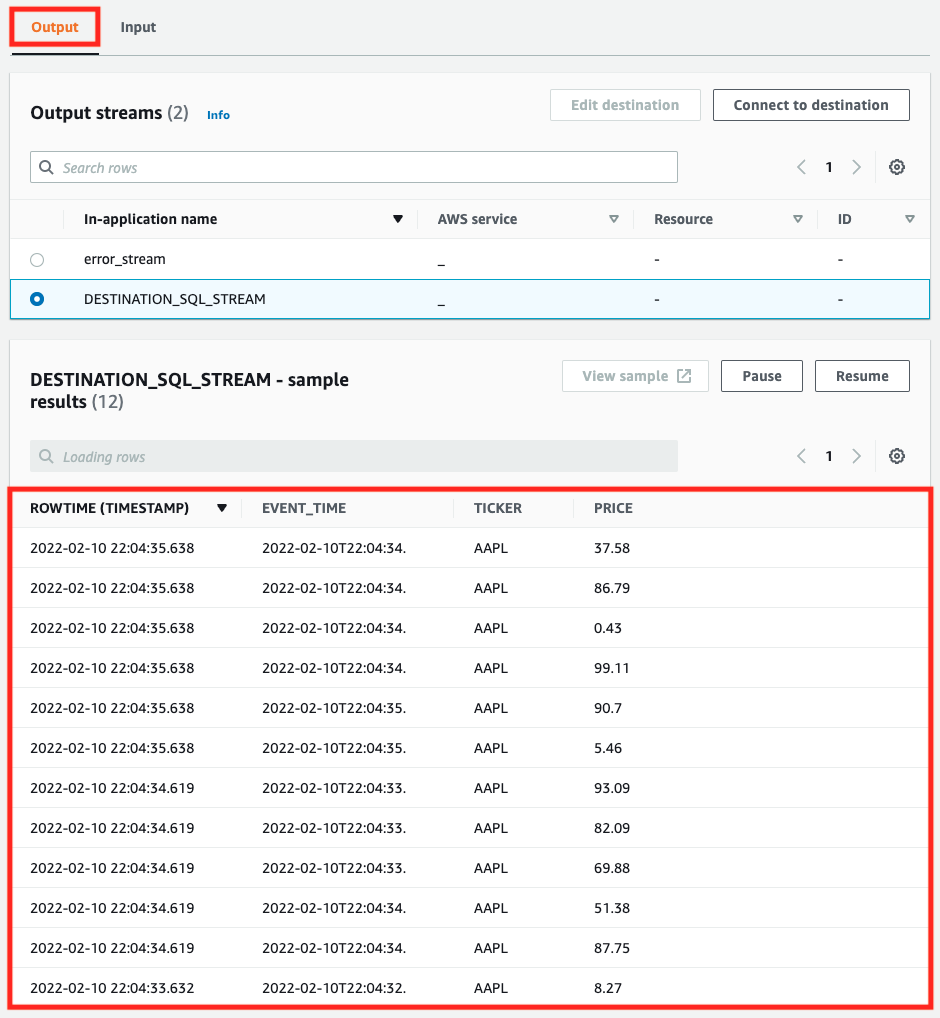
In this tab, we can see the results filtered by SQL. You can see that only the data with the ticker value “AAPL” has been extracted.
Summary
We have used two Kinesis services to handle streaming data.
We delivered the test streaming data generated by the Lambda function to the Kinesis Data Streams.
The delivered data was accepted by Kinesis Data Analytics, and we confirmed that it can be processed in real time with SQL base.