Building AppSync without Data Source
AppSync allows you to choose a data source from the following services
- Lambda
- DynamoDB
- OpenSearch
- None
- HTTP endpoint
- RDS
This time, we will check how to build a none data source.
For a basic explanation of AppSync and the configuration with DynamoDB as the data source, please refer to the following page.

Please refer to the following page for the configuration using Lambda as a data source.

Environment
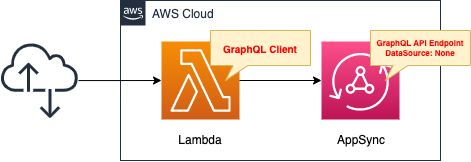
Define a schema in AppSync and configure it so that the following two operations can be performed.
- The data to be handled has two fields (key and datetime).
- Query to retrieve all stored data.
- Mutation to add data.
As mentioned earlier, in this configuration, no data source will be created in AppSync.
So to achieve the above actions in a pseudo way, we define temporary data in the resolver.
Create a Lambda function as a client to execute the GraphQL API with AppSync.
Enable the Function URL so that the URL query parameter can specify the operation to be performed.
The runtime environment for the function is Python 3.8.
CloudFormation template files
The above configuration is built using CloudFormation.
The CloudFormation template is located at the following URL
https://github.com/awstut-an-r/awstut-fa/tree/main/054
Explanation of key points of template files
Data Source
Resources:
DataSource:
Type: AWS::AppSync::DataSource
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
Name: DataSource
Type: NONE
Code language: YAML (yaml)The key point is the Type property.
If you do not have a data source, specify “NONE”.
Schema
Resources:
GraphQLSchema:
Type: AWS::AppSync::GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
Definition: |
schema {
query: Query
mutation: Mutation
}
type Query {
listSampleDatas: [SampleData]
}
type Mutation {
addSampleData(key: String!): SampleData
}
type SampleData {
key: String!
datetime: String
}
Code language: YAML (yaml)No data source is created, but no special action is required at the schema level.
Define the schema as usual.
As mentioned above, this time we will implement the operations described above, so we define the schema accordingly.
Resolvers
First, check the resolver for the mutation to which the data will be added.
Resources:
addSampleDataResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: addSampleData
Kind: UNIT
RequestMappingTemplate: |
{
"version": "2018-05-29",
"payload": {
"key": $util.toJson($context.arguments.key)
}
}
ResponseMappingTemplate: |
{
"key": $util.toJson($context.result.key),
"datetime": $util.toJson($util.time.nowFormatted("yyyy-MM-dd HH:mm:ssZ"))
}
TypeName: Mutation
Code language: YAML (yaml)The key point is to set the request and response mappings for the resolver.
The following page provides detailed information on how to configure mapping settings when there is no data source.
https://docs.aws.amazon.com/appsync/latest/devguide/resolver-mapping-template-reference-none.html
In AppSync without a data source, the mapping configuration is unique.
Instead of calling a remote data source, the local resolver will just forward the result of the request mapping template to the response mapping template.
Tutorial: Local Resolvers
This means that since there is no data source, the values generated by the request mapping are passed directly to the response mapping.
First check the request mapping (RequestMappingTemplate property).
Using $payload, you can pass values from the request mapping to the response mapping.
You can also use $context.arguments to get the arguments of the mutation.
In summary, the behavior is to pass the string passed in executing the mutation to the response mapping as the value of the key.
Next, check the response mapping (ResponseMappingTemplate property).
You can get the value passed from the response mapping in $context.result.
You can retrieve the current date and time with $util.time.nowFormatted.
In summary, the behavior is to set the argument passed from the response mapping as the key value, set the current date and time as the datetime value, and return the result as a muted result.
Next, we check the resolver for the query to retrieve all data.
Resources:
ListSampleDatasResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: listSampleDatas
Kind: UNIT
RequestMappingTemplate: |
{
"version": "2018-05-29",
}
ResponseMappingTemplate: |
[
{
"key": "hoge",
"datetime": "2022-05-15 12:34:56.7890"
},
{
"key": "foo",
"datetime": "2022-05-16 12:34:56.7890"
},
{
"key": "bar",
"datetime": "2022-05-17 12:34:56.7890"
}
]
TypeName: Query
Code language: YAML (yaml)First of all, request mapping, unlike the previous example, does not perform payload setting.
In other words, nothing is passed from the request mapping to the response mapping.
Next, the response mapping is set to return hard-coded values.
In other words, it will always return the same data as the search results.
(Reference) GraphQL client Lambda function
import json
import os
import time
from gql import Client, gql
from gql.transport.aiohttp import AIOHTTPTransport
api_key = os.environ['API_KEY']
graphql_url = os.environ['GRAPHQL_URL']
transport = AIOHTTPTransport(
url=graphql_url,
headers={
'x-api-key': api_key
})
client = Client(transport=transport, fetch_schema_from_transport=True)
ADD = 'Put'
LIST = 'List'
def lambda_handler(event, context):
operation = ''
document = None
result = None
if not 'queryStringParameters' in event or (
not 'operation' in event['queryStringParameters']):
operation = LIST
else:
operation = event['queryStringParameters']['operation']
if operation == ADD:
key = event['queryStringParameters']['key']
document = gql(
"""
mutation AddSampleData($key: String!) {
addSampleData(key: $key) {
key
datetime
}
}
"""
)
params = {
'key': key
}
result = client.execute(document, variable_values=params)
elif operation == LIST:
document = gql(
"""
query ListSampleDatas {
listSampleDatas {
key
datetime
}
}
"""
)
result = client.execute(document)
return {
'statusCode': 200,
'body': json.dumps(result, indent=2)
}
Code language: Python (python)A Lambda function to execute a GraphQL query.
We will use GQL as the GraphQL client library for Python.
https://github.com/graphql-python/gql
We will use GQL to execute the query mutations defined in the schema.
In Python, you can retrieve URL query parameters with event[‘queryStringParameters’].
The URL query parameters are passed as required by the URL query parameters.
- operation: Operation to be performed.
- key: Necessary if the operation is ADD. key: Key name of the data to be added.
Architecting
Use CloudFormation to build this environment and check the actual behavior.
Prepare deployment package for Lambda function
There are three ways to create a Lambda function.
In this case, we will choose the method of uploading a deployment package to an S3 bucket.
For more information, please refer to the following page

Prepare deployment package for Lambda layer
Prepare the aforementioned GQL as a Lambda layer.
For more information on the Lambda layer, please refer to the following page

The command to create a package for the Lambda layer is as follows
$ sudo pip3 install --pre gql[all] -t python
$ zip -r layer.zip python
Code language: Bash (bash)Create CloudFormation stacks and check resources in stacks
Create a CloudFormation stack.
For information on how to create stacks and check each stack, please refer to the following page

After checking the resources in each stack, information on the main resources created this time is as follows
- AppSync API: fa-054-GraphQLApi
- Function URL for the GraphQL client Lambda function: https://dkaky6lcgzcthyow5su5q3gsyi0tmyqt.lambda-url.ap-northeast-1.on.aws/
From the AWS Management Console, check AppSync.
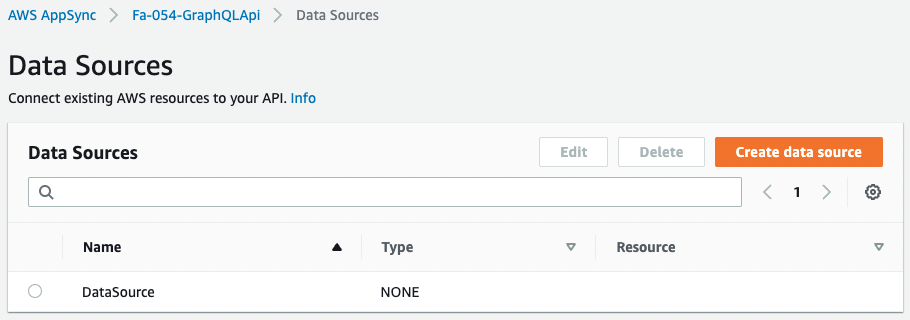
The data source shows that the Type is “NONE”.
This means that the data source entity does not exist in the AppSync API created this time.
Check the schema resolver settings.
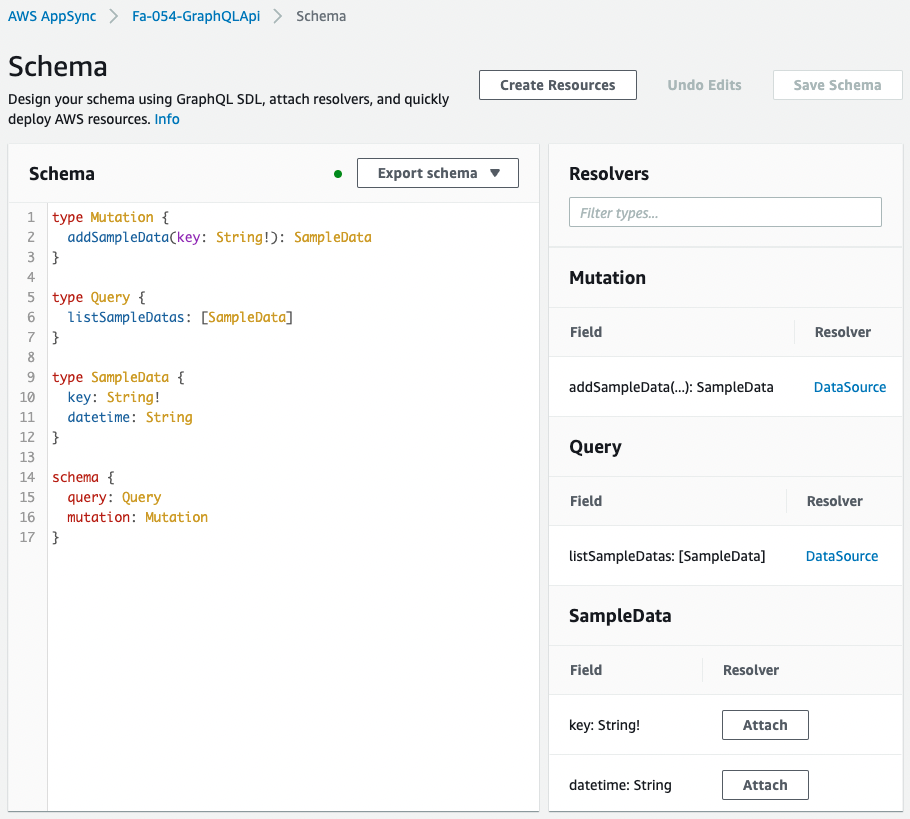
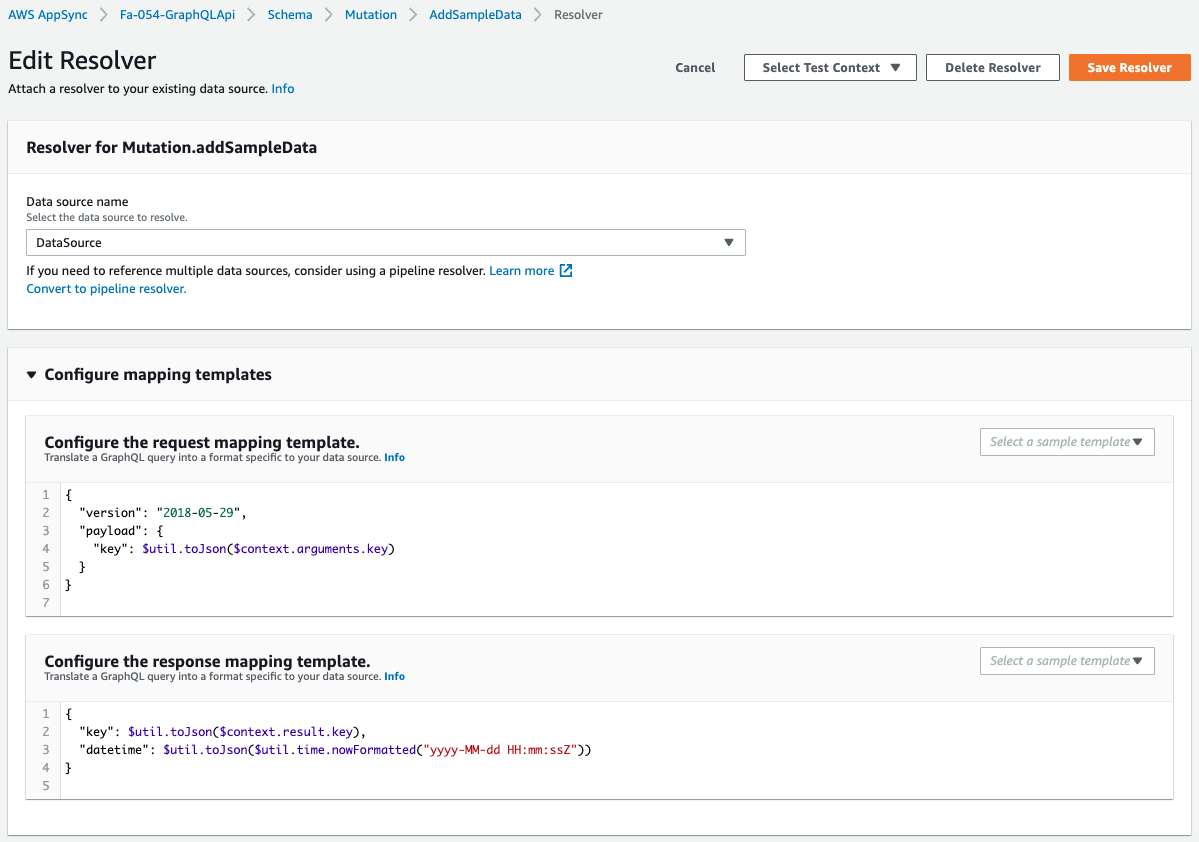
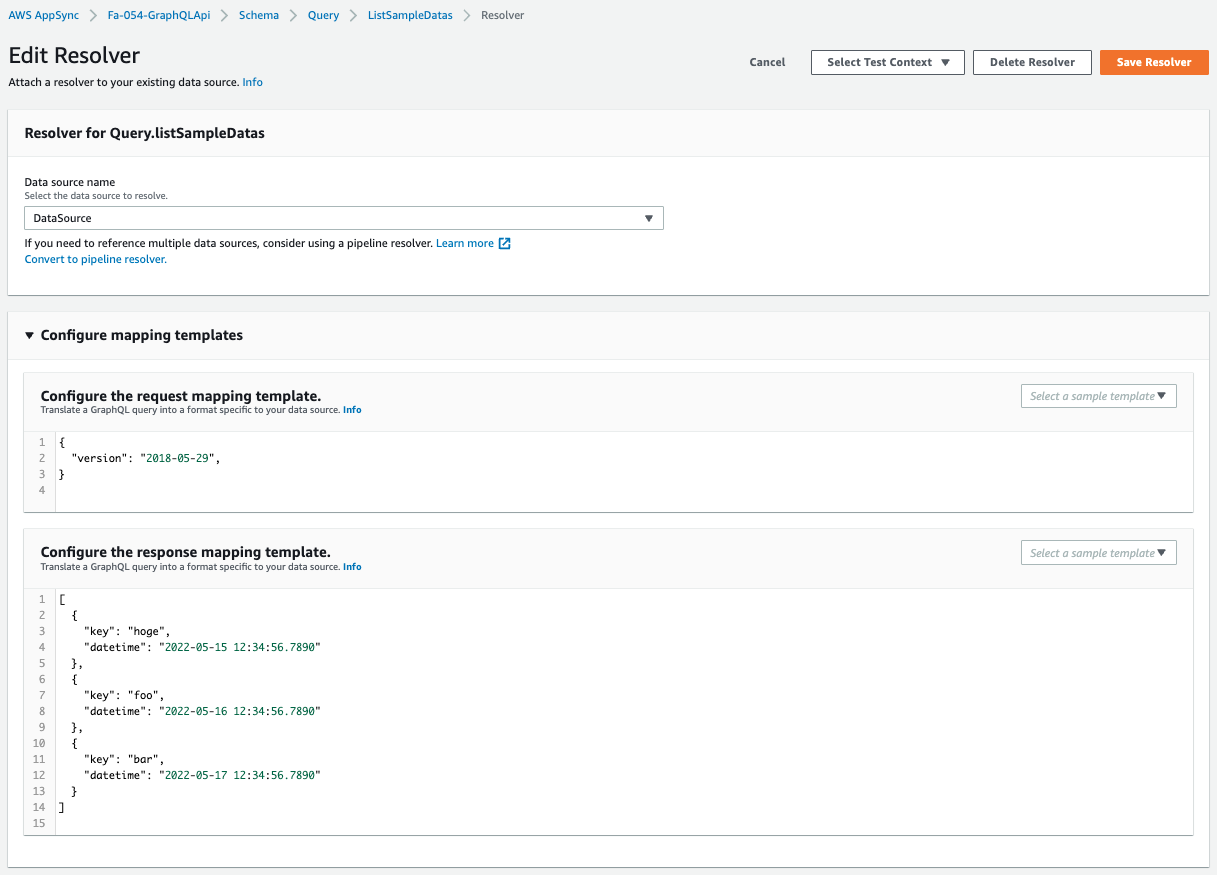
The settings are as defined in the CloudFormation template.
Checking Action
Now that everything is ready, access the Function URL of the GraphQL client Lambda function.
The first operation is to add data.
Specify “Add” as the operation value and “spam” as the key value in the URL query.
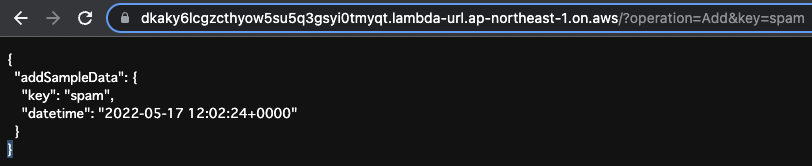
The addSampleData mutation is now executed.
The key value is set to “spam,” which was set as a parameter of the query earlier, and the datetime value is set to the current date and time.
As you can see, even without a data source, we were able to obtain the same results as when we registered the data.
Next is an operation that simulates a list of data.
Specify “List” as the value of operation in the URL query.
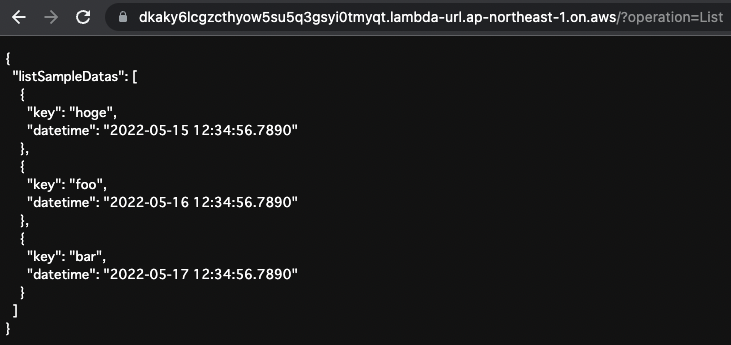
The listSampleDatas query is executed.
The data hard-coded in the response mapping corresponding to this query was returned as is.
Thus, even without a data source, the same results were obtained as when a pseudo data list was obtained.
Summary
We have introduced a configuration for setting up AppSync without a data source.