Setting up OpenSearch as DataSource for AppSync
AppSync allows you to select a data source from the following services
- Lambda
- DynamoDB
- OpenSearch
- None
- HTTP endpoint
- RDS
This time, we will check the configuration with Lambda as the data source.
For a basic explanation of AppSync and the configuration with DynamoDB as the data source, please refer to the following page.

Environment

Create OpenSearch to act as a data source.
Store AWS official movie data in the OpenSearch domain.
Define a schema resolver to operate this OpenSearch domain in AppSync.
Define the following query and mutation based on the sample presented in the AWS official
https://docs.aws.amazon.com/appsync/latest/devguide/tutorial-elasticsearch-resolvers.html
- listMovies: retrieve all stored movies data.
- getMovie: retrieve movie data by specifying ID.
- getMovieByActor: Obtains movie data by specifying the actor name.
- addMovie: Adds movie data.
Create two Lambda functions.
The runtime environment for the functions is Python 3.8.
The first function will be associated with a custom resource and set to run when the stack is created.
The function’s function is to upload a JSON file to the OpenSearch domain.
The aforementioned data is stored in an S3 bucket in the form of a JSON file, which is then uploaded to the domain.
The second function is set up as a client to run the GraphQL API.
Enable the Function URL so that the URL query parameter can specify the operation to be performed.
CloudFormation template files
Build the above configuration with CloudFormation.
The CloudFormation templates are located at the following URL
https://github.com/awstut-an-r/awstut-fa/tree/main/056
Explanation of key points of the template file
DataSource
Resources:
DataSource:
Type: AWS::AppSync::DataSource
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
Name: DataSource
OpenSearchServiceConfig:
AwsRegion: !Ref AWS::Region
Endpoint: !Sub "https://${DomainEndpoint}"
ServiceRoleArn: !Ref DataSourceRoleArn
Type: AMAZON_OPENSEARCH_SERVICE
Code language: YAML (yaml)The key point is the Type property.
When OpenSearch is used as the data source, specify “AMAZON_OPENSEARCH_SERVICE.
Also, set the details in the OpenSearchServiceConfig property.
Set the domain endpoints, etc.
IAM role for DataSource
Resources:
DataSourceRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service: appsync.amazonaws.com
Policies:
- PolicyName: !Sub "${Prefix}-DataSourcePolicy"
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- es:ESHttpDelete
- es:ESHttpHead
- es:ESHttpGet
- es:ESHttpPost
- es:ESHttpPut
Resource:
- !Sub "arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${DomainName}/*"
Code language: YAML (yaml)To specify OpenSearch as the data source, authorize AppSync to access OpenSearch.
Schema
Resources:
GraphQLSchema:
Type: AWS::AppSync::GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
Definition: |
schema {
query: Query
mutation: Mutation
}
type Query {
listMovies: [Movie]
getMovie(_id: ID!): Movie
getMovieByActor(actor: String!): [Movie]
}
type Mutation {
addMovie(director: String, genre: [String], year: Int, actor: [String], title: String): Movie
}
type Movie {
_id: ID!
director: String
genre: [String]
year: Int
actor: [String]
title: String
}
Code language: YAML (yaml)Define the schemas with reference to the official AWS page discussed at the beginning of this section.
Resolver
Resolver for listMovies query
Resolver for retrieving all data stored in the OpenSearch domain.
Resources:
ListMoviesResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: listMovies
Kind: UNIT
RequestMappingTemplate: !Sub |
{
"version": "2017-02-28",
"operation": "GET",
"path": "/${IndexName}/_doc/_search",
"params": {
"headers": {},
"queryString": {
"pretty": "true"
},
"body": {}
}
}
ResponseMappingTemplate: |
[
#foreach($hit in $context.result.hits.hits)
## print ',' of list.
#if( $velocityCount > 1 )
,
#end
#set ($source = $hit.get("_source"))
## append _id to $hit.
$util.quiet($source.put("_id", $hit.get("_id")))
$util.toJson($source)
#end
]
TypeName: Query
Code language: YAML (yaml)The key point is the configuration of the resolver’s request mapping and response mapping.
The following page details the mapping settings when AppSync is used as the data source.
First, check the request mapping (RequestMappingTemplate property).
The operation field specifies the operation to be performed on the OpenSearch domain. Since this resolver is for queries to retrieve data, “GET” is specified.
The path field specifies the endpoint that performs the operation for the OpenSearch domain. To perform a search, specify the following PATH
/[index name]/_doc/_search
This time, use CloudFormation’s built-in function Fn::Sub to embed the index name.
You can set search criteria in the body field. Since this mapping is for a query that retrieves all data, we do not set anything.
Next, check the response mapping (ResponseMappingTemplate property).
The first line of this property should be “[” and the last line should be “]”. This will return a list object as the return value of the response mapping.
You can access the search results with $context.result.hits. This object is of type list and can be looped through using #foreach.
You can define variables with #set. The search results stored in $hit._source are stored in a variable called source.
Use #put method to add data named _id to source. In doing so, use $util.quiet. This is done so that the return value will not be affected by the action of the put method.
In $util.toJson, the contents of the variable source are converted to JSON and output. This becomes the return value.
As mentioned above, the return value is a list object. Therefore, after the second round of loop processing, a delimiter character “,” is required between the previous value and the return value. Therefore, use #if to check $velocityCount, that is, the value of the loop count, and set it so that “,” is output after the second round.
Resolver for getMovie query
Resolver to retrieve specific movie data by specifying ID.
Resources:
GetMovieResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: getMovie
Kind: UNIT
RequestMappingTemplate: !Sub |
#set ($_id = $context.arguments.get("_id"))
{
"version": "2017-02-28",
"operation": "GET",
"path": $util.toJson("/${IndexName}/_doc/$_id"),
"params": {
"headers": {},
"queryString": {
"pretty": "true"
},
"body": {}
}
}
ResponseMappingTemplate: |
#set ($source = $context.result.get("_source"))
## append _id.
$util.quiet($source.put("_id", $context.result.get("_id")))
$util.toJson($source)
TypeName: Query
Code language: YAML (yaml)The key points here are also request mapping and response mapping.
First, check the request mapping.
GraphQL arguments are stored in $context.arguments. This time, the argument _id is stored in the variable of the same name.
path field, but if you want to search by ID, specify the following URL in this field.
/[index name]/_doc/[id].
The index name is embedded using the built-in function Fn::Sub.
The ID is the value of the GraphQL argument described above.
Next, check the response mapping.
When a search is performed by specifying an ID, the search result is stored in $context.result._source.
The rest of the flow is the same as the previous resolver, adding the ID data, converting it to JSON, outputting it, and creating the return value.
Resolver for getMovieByActor query
Resolver for retrieving movie data by actor name.
Resources:
GetMovieByActorResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: getMovieByActor
Kind: UNIT
RequestMappingTemplate: !Sub |
#set ($actor = $context.arguments.get("actor"))
{
"version": "2017-02-28",
"operation": "GET",
"path": "/${IndexName}/_doc/_search",
"params": {
"headers": {},
"queryString": {
"pretty": "true"
},
"body": {
"query": {
"match": {
"actor": $util.toJson($actor)
}
}
}
}
}
ResponseMappingTemplate: |
[
#foreach($hit in $context.result.hits.hits)
## print ',' of list.
#if( $velocityCount > 1 )
,
#end
#set ($source = $hit.get("_source"))
## append _id to $hit.
$util.quiet($source.put("_id", $hit.get("_id")))
$util.toJson($source)
#end
]
TypeName: Query
Code language: YAML (yaml)The key point is the request mapping.
Set the search condition in the query in the body field. Since the search is performed by performer name, set the performer name in the match query.
Response mapping is the same as the first resolver.
Loop through the search results and create a return value.
Resolver for addMovie mutation
Resolver for adding movie data.
Resources:
AddMovieResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: addMovie
Kind: UNIT
RequestMappingTemplate: !Sub |
#set ($_id = $util.autoId())
#set ($director = $context.arguments.director)
#set ($genre = $context.arguments.genre)
#set ($year = $context.arguments.year)
#set ($actor = $context.arguments.actor)
#set ($title = $context.arguments.title)
{
"version": "2017-02-28",
"operation": "PUT",
"path": $util.toJson("/${IndexName}/_doc/$_id"),
"params": {
"headers": {},
"queryString": {
"pretty": "true"
},
"body": {
"director": $util.toJson($director),
"genre": $util.toJson($genre),
"year": $util.toJson($year),
"actor": $util.toJson($actor),
"title": $util.toJson($title)
}
}
}
ResponseMappingTemplate: |
#set ($source = $context.result.get("_source"))
## append _id to $hit.
$util.quiet($source.put("_id", $context.result.get("_id")))
$util.toJson($source)
TypeName: Mutation
Code language: YAML (yaml)The request mapping is the key.
Prepare the six values that make up the movie data; five use GraphQL arguments; for the ID, use the ID automatically generated by $util.autoId().
For the operation field, specify “PUT”. This is for adding data.
The path field is the same as for ID-based search.
Specify 5 data in the body field except ID.
The request mapping is the same as for the second resolver.
Add the ID data and create the return value.
(Reference) OpenSearch
For basic information on OpenSearch, please refer to the following page

This page covers the key points in using OpenSearch as a data source for AppSync.
Resources:
Domain:
Type: AWS::OpenSearchService::Domain
Properties:
AccessPolicies:
Version: 2012-10-17
Statement:
- Effect: Allow
Principal:
AWS:
- !Ref DataSourceRoleArn
- !Ref FunctionRole2Arn
Action:
- es:ESHttpDelete
- es:ESHttpHead
- es:ESHttpGet
- es:ESHttpPost
- es:ESHttpPut
Resource: !Sub "arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${DomainName}/*"
#AdvancedSecurityOptions:
# Enabled: true
# InternalUserDatabaseEnabled: true
# MasterUserOptions:
# MasterUserName: !Ref MasterUserName
# MasterUserPassword: !Ref MasterUserPassword
ClusterConfig:
DedicatedMasterEnabled: false
InstanceCount: !Ref InstanceCount
InstanceType: !Ref InstanceType
WarmEnabled: false
ZoneAwarenessEnabled: false
CognitoOptions:
Enabled: false
DomainEndpointOptions:
CustomEndpointEnabled: false
EnforceHTTPS: true
TLSSecurityPolicy: Policy-Min-TLS-1-0-2019-07
DomainName: !Ref DomainName
EBSOptions:
EBSEnabled: true
VolumeSize: !Ref VolumeSize
VolumeType: gp2
EncryptionAtRestOptions:
Enabled: true
KmsKeyId: !Ref Key
EngineVersion: !Ref EngineVersion
NodeToNodeEncryptionOptions:
Enabled: true
Code language: YAML (yaml)There are two points to note related to this property.
The first is the principal setting.
When granting access permission using IAM authentication information, as in this case, a description that specifies all resources using wildcards is not allowed.
As mentioned earlier, specific resources such as IAM roles must be specified.
The second point concerns authentication by a master user using fine-grained access control (FGAC).
In the page introduced at the beginning of this section, we introduced a configuration with master user authentication enabled.
However, please note that when using IAM credentials to grant access permissions as in this case, authentication by master user is not possible, as quoted below.
If a resource-based access policy contains IAM users or roles, clients must send signed requests using AWS Signature Version 4. As such, access policies can conflict with fine-grained access control, especially if you use the internal user database and HTTP basic authentication. You can’t sign a request with a user name and password and IAM credentials.
Fine-grained access control in Amazon OpenSearch Service
(Reference) GraphQL client Lambda function
import json
import os
import time
from gql import Client, gql
from gql.transport.aiohttp import AIOHTTPTransport
api_key = os.environ['API_KEY']
graphql_url = os.environ['GRAPHQL_URL']
transport = AIOHTTPTransport(
url=graphql_url,
headers={
'x-api-key': api_key
})
client = Client(transport=transport, fetch_schema_from_transport=True)
LIST = 'List'
GET = 'Get'
ACTOR = 'Actor'
ADD = 'Add'
def lambda_handler(event, context):
operation = ''
document = None
result = None
if not 'queryStringParameters' in event or (
not 'operation' in event['queryStringParameters']):
operation = LIST
else:
operation = event['queryStringParameters']['operation']
if operation == LIST:
document = gql(
"""
query ListMovies {
listMovies {
_id
title
}
}
"""
)
result = client.execute(document)
elif operation == GET:
document = gql(
"""
query GetMovie($_id: ID!) {
getMovie(_id: $_id) {
_id
director
genre
year
actor
title
}
}
"""
)
_id = event['queryStringParameters']['_id']
params = {
'_id': _id
}
result = client.execute(document, variable_values=params)
elif operation == ACTOR:
document = gql(
"""
query GetMovieByActor($actor: String!) {
getMovieByActor(actor: $actor) {
_id
actor
title
}
}
"""
)
actor = event['queryStringParameters']['actor']
params = {
'actor': actor
}
result = client.execute(document, variable_values=params)
elif operation == ADD:
document = gql(
"""
mutation AddMovie($director: String, $genre: [String], $year: Int, $actor: [String], $title: String) {
addMovie(director: $director, genre: $genre, year: $year, actor: $actor, title: $title) {
_id
director
genre
year
actor
title
}
}
"""
)
director = event['queryStringParameters']['director']
genre = event['queryStringParameters']['genre'].split(',')
year = int(event['queryStringParameters']['year'])
actor = event['queryStringParameters']['actor'].split(',')
title = event['queryStringParameters']['title']
params = {
'director': director,
'genre': genre,
'year': year,
'actor': actor,
'title': title
}
result = client.execute(document, variable_values=params)
return {
'statusCode': 200,
'body': json.dumps(result, indent=2)
}
Code language: Python (python)A Lambda function to execute a GraphQL query.
We will use GQL as the GraphQL client library for Python.
https://github.com/graphql-python/gql
We will use GQL to execute the query mutations defined in the schema.
In Python, you can retrieve URL query parameters with event[‘queryStringParameters’].
The URL query parameters are used to pass the necessary parameters.
The operation parameter specifies the GraphQL query to be executed.
(Reference) Lambda function for CloudFormation custom resources
For information on how to use a custom resource to automatically upload and index a JSON file located in an S3 bucket when creating an OpenSearch domain, please see the following page

This page will cover the differences from the above page.
First, check the IAM role for the function.
Resources:
FunctionRole2:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service:
- lambda.amazonaws.com
ManagedPolicyArns:
- arn:aws:iam::aws:policy/service-role/AWSLambdaBasicExecutionRole
Policies:
- PolicyName: !Sub "${Prefix}-CustomResourceFunctionPolicy"
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- s3:GetObject
Resource:
- !Sub "arn:aws:s3:::${BulkS3Bucket}/*"
- Effect: Allow
Action:
- es:ESHttpDelete
- es:ESHttpHead
- es:ESHttpGet
- es:ESHttpPost
- es:ESHttpPut
Resource:
- !Sub "arn:aws:es:${AWS::Region}:${AWS::AccountId}:domain/${DomainName}/*"
Code language: YAML (yaml)The content allows access to the S3 bucket where the JSON file is stored and access to OpenSearch.
The latter in particular is the same as the IAM role for AppSync.
Next, check the code of the Lambda function.
import boto3
import cfnresponse
import json
import os
import requests
from requests.auth import HTTPBasicAuth
from requests_aws4auth import AWS4Auth
BULK_ENDPOINT = os.environ['BULK_ENDPOINT']
BULK_S3_BUCKET = os.environ['BULK_S3_BUCKET']
BULK_S3_KEY = os.environ['BULK_S3_KEY']
REGION = os.environ['REGION']
CREATE = 'Create'
response_data = {}
s3_client = boto3.client('s3')
credentials = boto3.Session().get_credentials()
awsauth = AWS4Auth(
region=REGION,
service='es',
refreshable_credentials=credentials
)
def lambda_handler(event, context):
try:
if event['RequestType'] == CREATE:
s3_response = s3_client.get_object(
Bucket=BULK_S3_BUCKET,
Key=BULK_S3_KEY)
# binary
bulk = s3_response['Body'].read()
print(bulk)
requests_response = requests.post(
BULK_ENDPOINT,
data=bulk,
auth=awsauth,
headers={'Content-Type': 'application/json'}
)
print(requests_response.text)
cfnresponse.send(event, context, cfnresponse.SUCCESS, response_data)
except Exception as e:
print(e)
cfnresponse.send(event, context, cfnresponse.FAILED, response_data)
Code language: Python (python)As we saw in the OpenSearch section, access to the domain is done using IAM credentials.
In this case, we will use requests to generate an HTTP request and implement the process of uploading a JSON file to the domain.
This means that this HTTP request must be a signed request using AWS signature version 4.
Therefore, use requests_aws4auth.
For details, please refer to the following page, which uses the authentication information of the aforementioned IAM role to sign and respond to HTTP requests.
https://pypi.org/project/requests-aws4auth/
Architecting
Using CloudFormation, we will build this environment and check the actual behavior.
Preliminary Preparation
Refer to the following page for three preparations.
- Prepare documents to be uploaded to the OpenSearch domain
- Prepare a deployment package for the Lambda function
- Prepare a deployment package for the Lambda layer
The command to create a package for the Lambda layer is as follows
sudo pip3 install requests -t python
sudo pip3 install requests-aws4auth -t python
sudo pip3 install --pre gql[all] -t python
[cfnresponse.py]
zip -r layer.zip python
Code language: Bash (bash)In addition, the cfnresponse module is also included in the Lambda layer.
For more information on cfnresponse, please refer to the following official page
Create CloudFormation stacks and check resources in stacks
Create a CloudFormation stack using AWS CLI.
This configuration consists of multiple template files, which are divided into multiple files, and place them in an arbitrary bucket.
The following is an example of creating a stack by referencing a template file placed in an arbitrary S3 bucket.
The stack name is “fa-056”, the bucket name is “awstut-bucket”, and the folder name where the files are placed is “fa-056”.
$ aws cloudformation create-stack \
--stack-name fa-056 \
--template-url https://awstut-bucket.s3.ap-northeast-1.amazonaws.com/fa-056/fa-056.yaml \
--capabilities CAPABILITY_IAM
Code language: Bash (bash)
After checking the resources for each stack, the following is the information for the main resources created in this case.
- AppSync API: fa-056-GraphQLApi
- OpenSearch domain name: fa-056
- OpenSearch domain endpoint URL: https://search-fa-056-3grntiuisivzu6h6oy7nowjgze.ap-northeast-1.es.amazonaws.com
- Function URL for GraphQL client Lambda function: https://42rvtqzk4lna3b5xaruvsoiv240wnuwy.lambda-url.ap-northeast-1.on.aws/
Check AppSync from the AWS Management Console.
First is the data source.
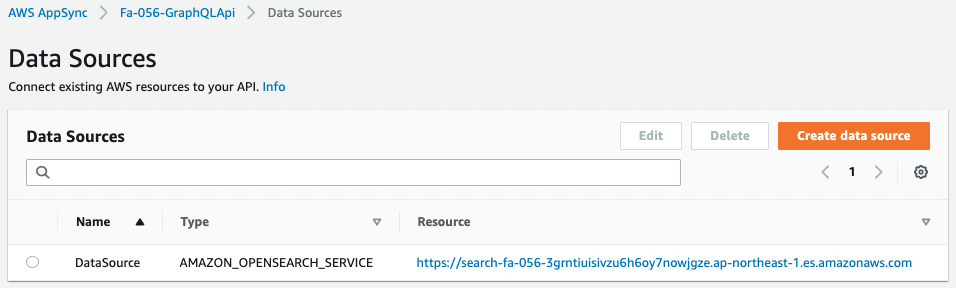
Looking at the data source, the Type is “AMAZON_OPENSEARCH_SERVICE”.
Next, check the Schema Resolver.
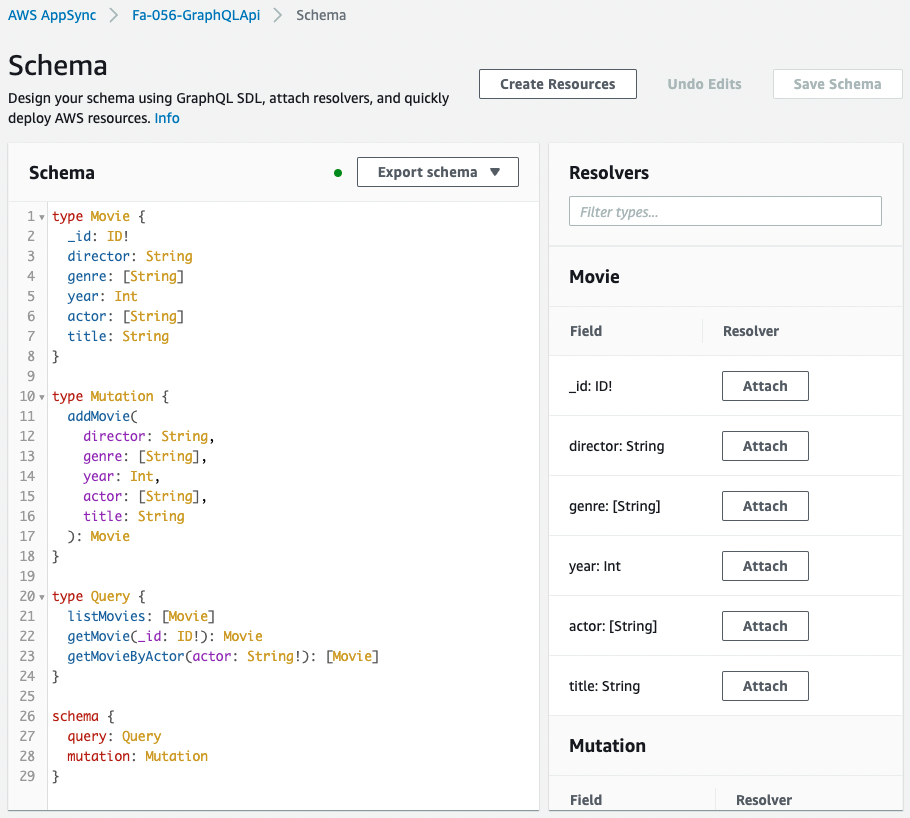
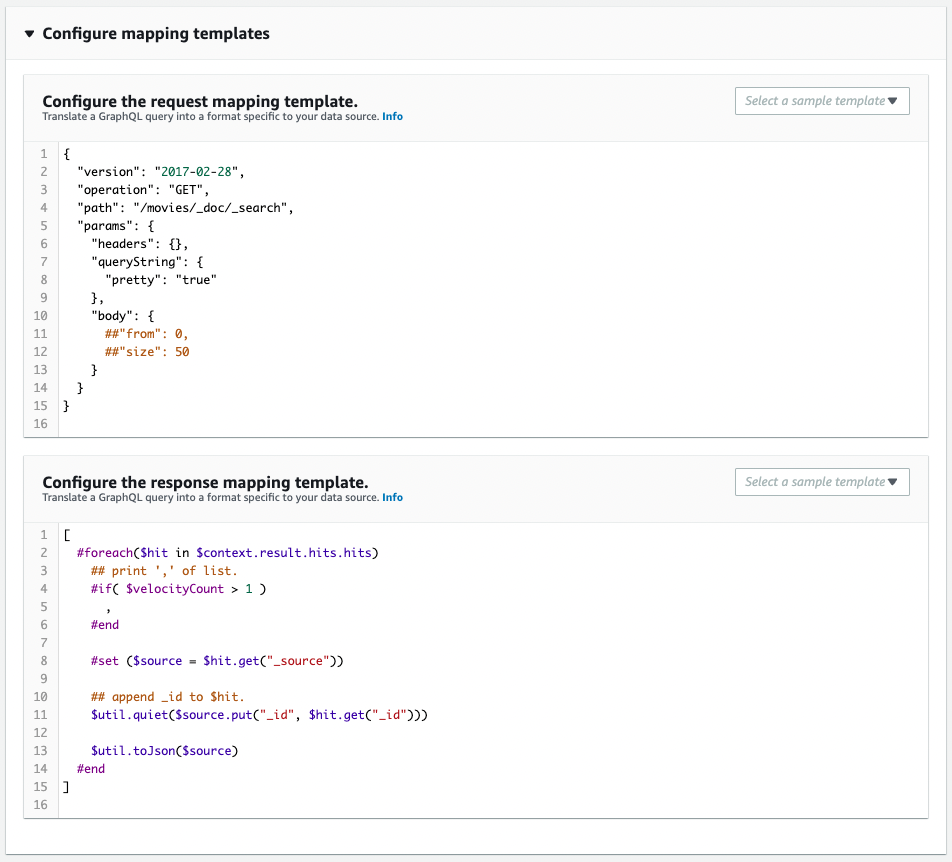
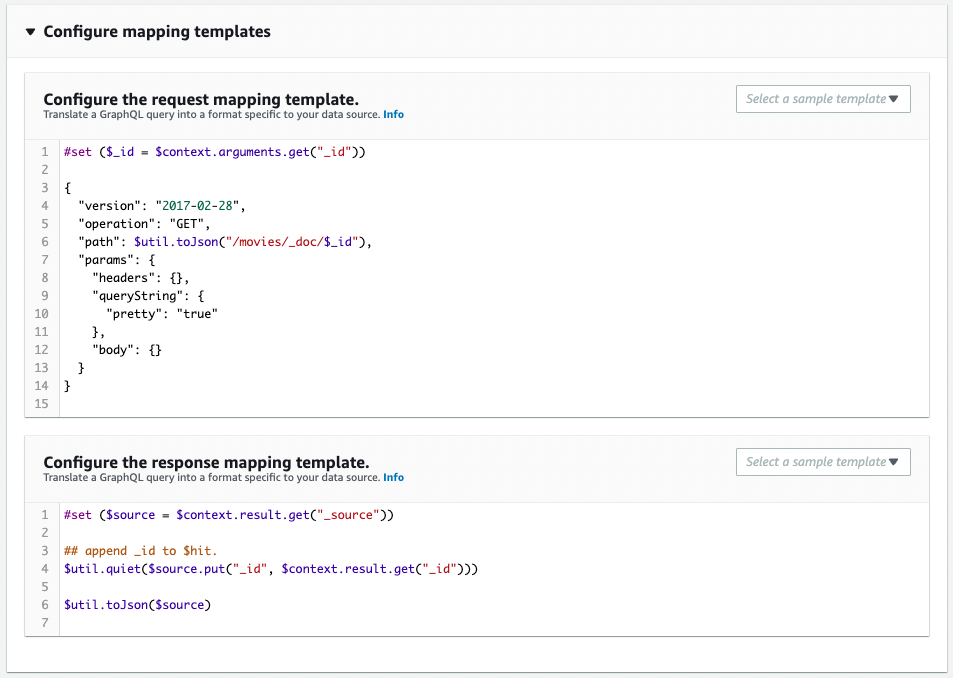
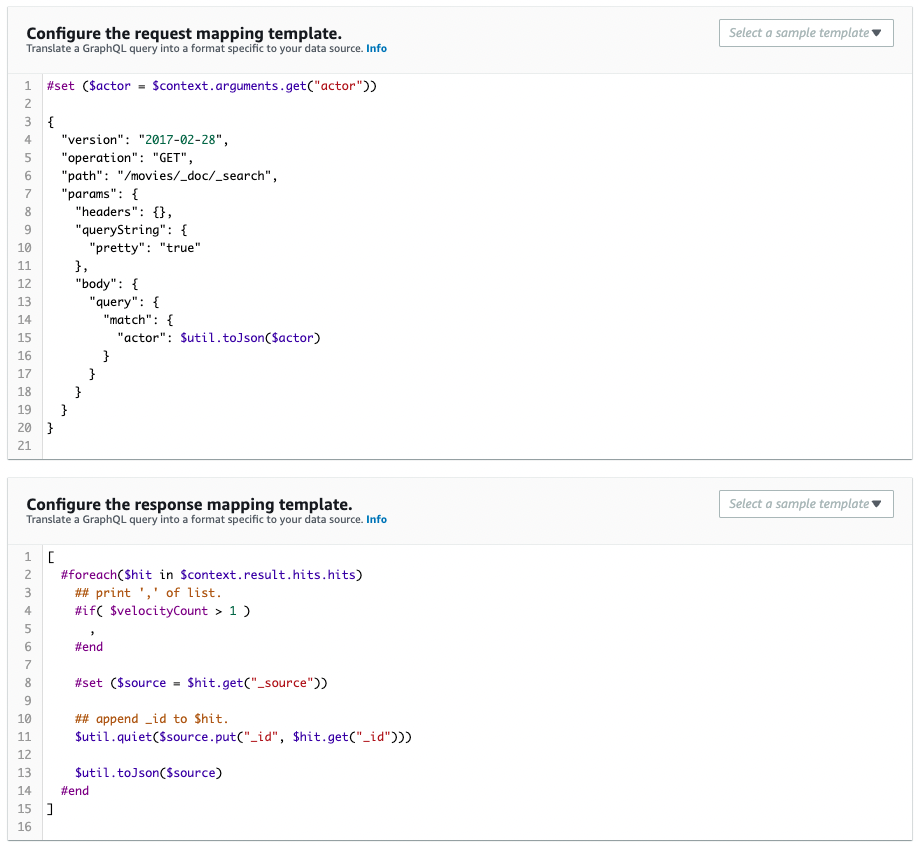
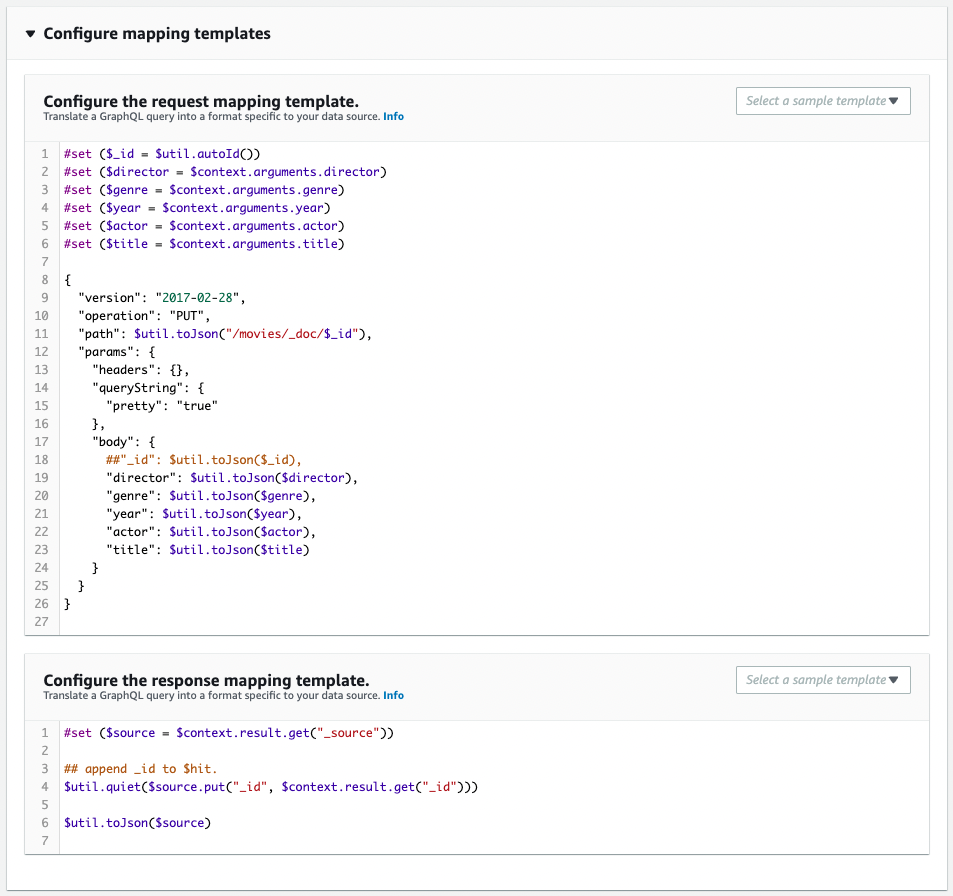
It is created as defined in the CloudFormation template file.
Next, check OpenSearch.
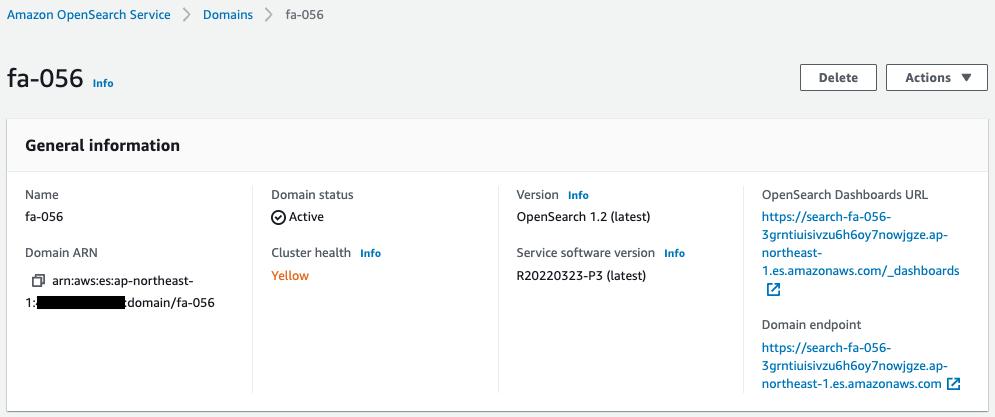
This has also been successfully created.
Checking Action
Now that everything is ready, access the Function URL of the GraphQL client Lambda function.
listMovies
First, retrieve all stored data.
Specify “List” as the operation value in the URL query.
This will execute the following GraphQL query
query ListMovies {
listMovies {
_id
title
}
}
Code language: plaintext (plaintext)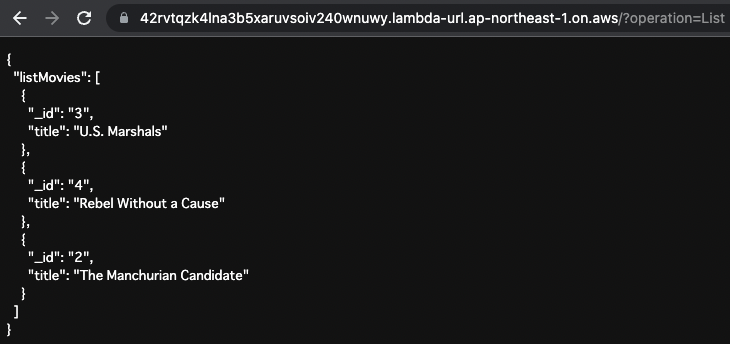
The _id and title of all stored data are returned.
getMovie
Next, we retrieve the data by specifying the ID.
Specify “Get” for the operation value in the URL query and “3” for the _id.
This will result in the following GraphQL query
query GetMovie($_id: ID!) {
getMovie(_id: $_id) {
_id
director
genre
year
actor
title
}
}
Code language: plaintext (plaintext)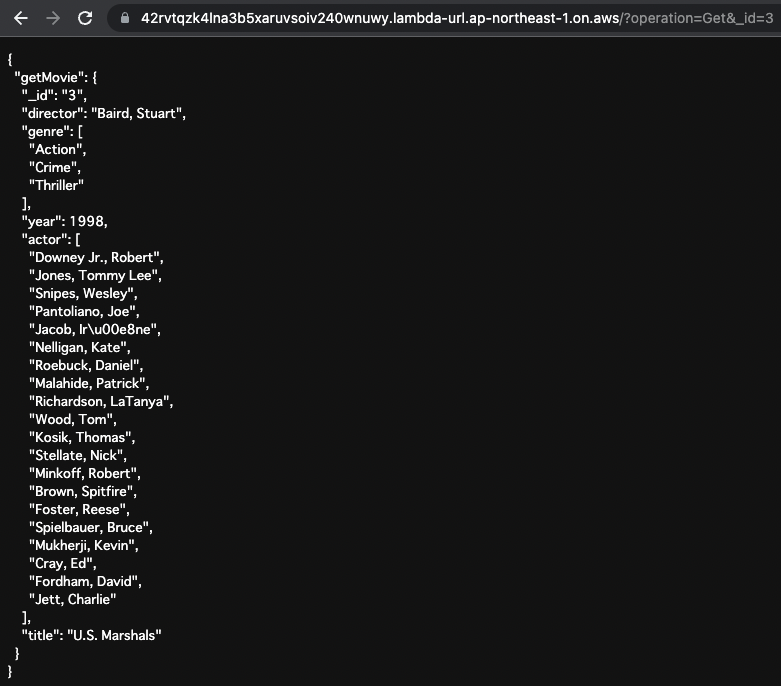
Movie data with ID “3” is returned.
getMovieByActor
Next, the data is obtained by specifying the name of the actor.
Specify “Actor” as the value of operation in the URL query and “Jr.” as the actor.
This will execute the following GraphQL query
query GetMovieByActor($actor: String!) {
getMovieByActor(actor: $actor) {
_id
actor
title
}
}
Code language: plaintext (plaintext)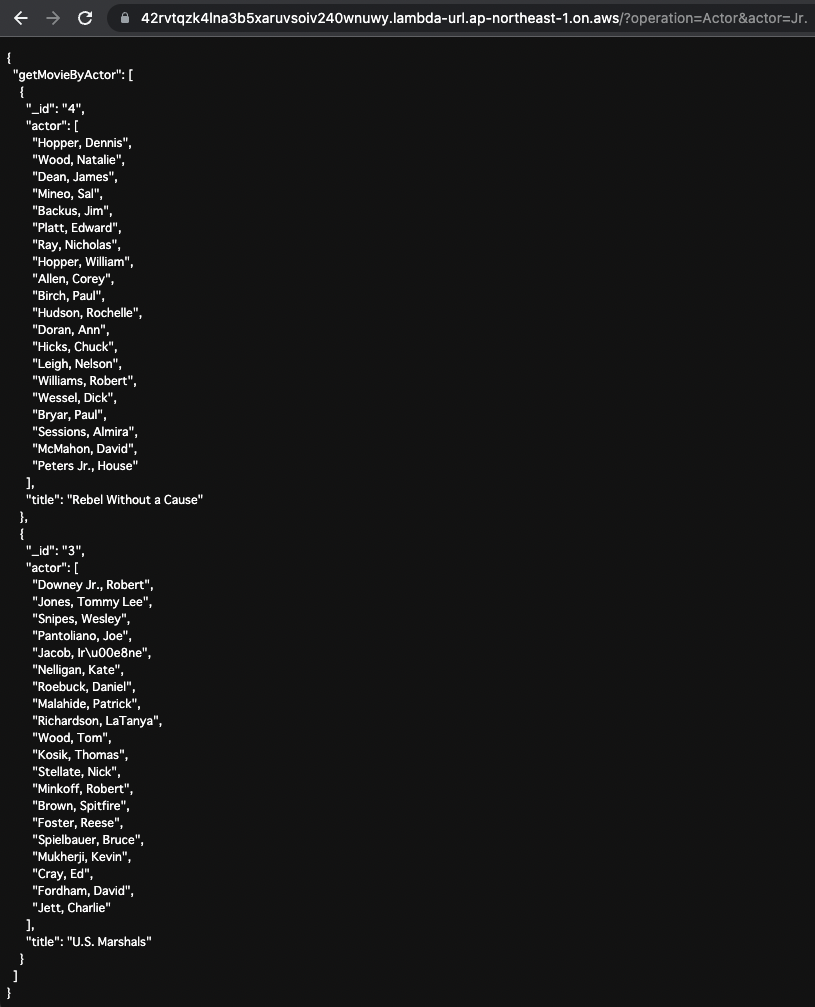
Movie data with “Jr.” in the actor’s name is returned.
AddMovie
Finally, save the new movie data.
Set the URL query as follows
- operation:Add
- director:hoge
- genre:aaa,bbb
- year:2022
- actor:XXX,YYYY,ZZZZ
- title:foo
This will execute the following GraphQL mutation
mutation AddMovie($director: String, $genre: [String], $year: Int, $actor: [String], $title: String) {
addMovie(director: $director, genre: $genre, year: $year, actor: $actor, title: $title) {
_id
director
genre
year
actor
title
}
}
Code language: plaintext (plaintext)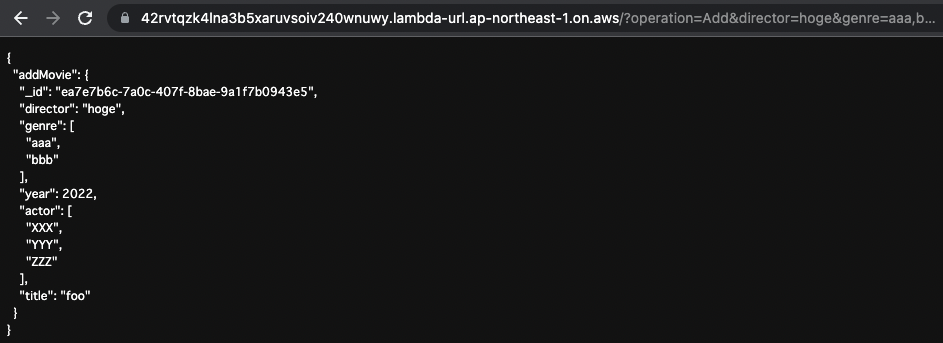
The video data was saved as specified.
For the _id, an automatically generated value is used.
Specify the ID again and check the saved data.
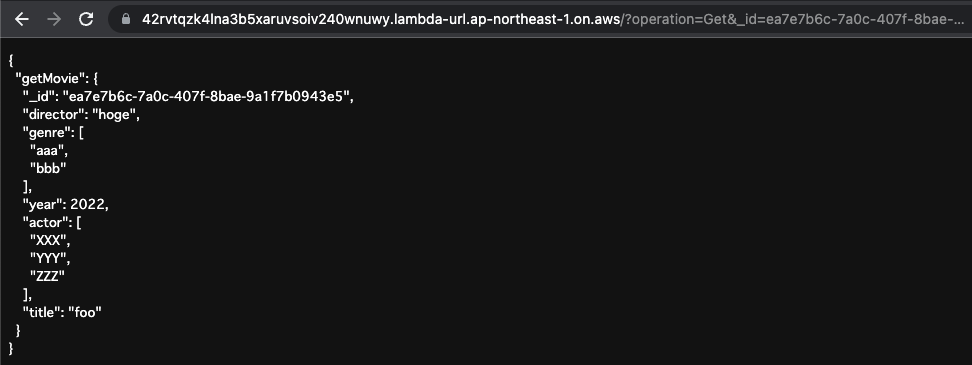
The data was returned normally.
Summary
We have introduced a configuration for setting OpenSearch as the AppSync data source.