Store data received by Kinesis Data Streams in S3 buckets via Firehose
In the following pages, we have shown how data generated by Lambda functions can be received by Kinesis Data Streams and analyzed by Kinesis Data Analytics.

In this case, we will use Kinesis Data Firehose to store data in S3 buckets.
Environment
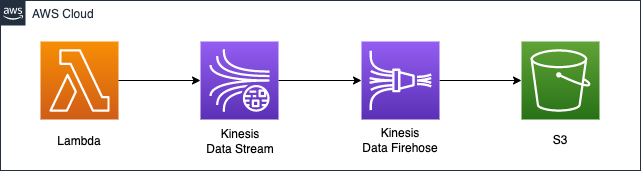
The stream data to be stored in the S3 bucket will be generated by a Lambda function.
The runtime environment for the function is Python 3.8.
Capture the data generated by the function with Kinesis Data Streams.
Create a Finesis Data Firehose delivery stream.
Specify Data Streams as the source of the data.
Specify S3 bucket as the destination for the data.
CloudFormation template files
The above configuration is built with CloudFormation.
The CloudFormation template file is located at the following URL
https://github.com/awstut-an-r/awstut-saa/tree/main/04/003
Explanation of key points of template files
Lambda関数
Resources:
DataSourceLambda:
Type: AWS::Lambda::Function
Properties:
Architectures:
- !Ref Architecture
Code:
ZipFile: |
import boto3
import datetime
import json
import os
import random
STREAM_NAME = os.environ['KINESIS_STREAM_NAME']
LIMIT = 10
def get_data():
return {
'EVENT_TIME': datetime.datetime.now().isoformat(),
'TICKER': random.choice(['AAPL', 'AMZN', 'MSFT', 'INTC', 'TBV']),
'PRICE': round(random.random() * 100, 2)}
def generate(stream_name, kinesis_client, limit):
for i in range(limit):
data = get_data()
print(data)
kinesis_client.put_record(
StreamName=stream_name,
Data=json.dumps(data).encode('utf-8'),
PartitionKey="partitionkey")
def lambda_handler(event, context):
generate(STREAM_NAME, boto3.client('kinesis'), LIMIT)
Environment:
Variables:
KINESIS_STREAM_NAME: !Ref KinesisDataStreamName
Handler: !Ref Handler
Role: !GetAtt DataSourceLambdaRole.Arn
Runtime: !Ref Runtime
Timeout: !Ref Timeout
Code language: YAML (yaml)Define the code to be executed by the Lambda function in inline notation.
For more information, please see the following page.

The content of the code to be executed is based on the following official AWS page.
One change is to set an upper limit on the data to be generated.
This time we generate 10 pieces of data.
The following is the IAM role for this function.
Resources:
DataSourceLambdaRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service:
- lambda.amazonaws.com
Policies:
- PolicyName: DataSourceLambdaPolicy
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- kinesis:PutRecord
Resource:
- !Ref KinesisDataStreamArn
Code language: YAML (yaml)Grant permission to access Kinesis Data Streams from Lambda.
Specifically, allow the kinesis:PutRecord action.
Kinesis Data Streams
Resources:
KinesisDataStream:
Type: AWS::Kinesis::Stream
Properties:
Name: !Sub "${Prefix}-DataStream"
ShardCount: !Ref ShardCount
Code language: YAML (yaml)Create Data Streams.
No special settings are required.
Set the number of shards to “1”.
Kinesis Data Firehose
Resources:
KinesisFirehoseDeliveryStream:
Type: AWS::KinesisFirehose::DeliveryStream
Properties:
DeliveryStreamName: !Ref KinesisFirehoseDeliveryStreamName
DeliveryStreamType: KinesisStreamAsSource
KinesisStreamSourceConfiguration:
KinesisStreamARN: !GetAtt KinesisDataStream.Arn
RoleARN: !GetAtt KinesisStreamSourceRole.Arn
S3DestinationConfiguration:
BucketARN: !Ref BucketArn
CloudWatchLoggingOptions:
Enabled: true
LogGroupName: !Ref LogGroup
LogStreamName: !Ref LogStream
CompressionFormat: UNCOMPRESSED
Prefix: firehose/
RoleARN: !GetAtt KinesisS3DestinationRole.Arn
Code language: YAML (yaml)Create a Data Firehose.
In this case, Data Streams will be used as the data source, so two properties will be set.
The first is the DeliveryStreamType property.
Specify “KinesisStreamAsSource” for this property.
The second point is the KinesisStreamSourceConfiguration property.
Specify the Data Streams mentioned above.
Then set the S3DestinationConfiguration property, this time using the S3 bucket as the data destination.
Specify the destination bucket in the BucketARN property.
The following are the two IAM roles related to Data Firehose.
Refer to the example of setting access rights covered on the official AWS page.
First is the IAM role used to receive data from Data Streams.
Resources:
KinesisStreamSourceRole:
Type: AWS::IAM::Role
DeletionPolicy: Delete
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service:
- firehose.amazonaws.com
Policies:
- PolicyName: KinesisStreamSourcePolicy
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- kinesis:DescribeStream
- kinesis:GetShardIterator
- kinesis:GetRecords
- kinesis:ListShards
Resource:
- !GetAtt KinesisDataStream.Arn
Code language: YAML (yaml)Grant the necessary permissions to access Data Streams and retrieve data (records).
Next is the IAM role used to send data to the S3 bucket.
Resources:
KinesisS3DestinationRole:
Type: AWS::IAM::Role
DeletionPolicy: Delete
Properties:
AssumeRolePolicyDocument:
Version: "2012-10-17"
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service:
- firehose.amazonaws.com
Policies:
- PolicyName: KinesisS3DestinationPolicy
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- s3:AbortMultipartUpload
- s3:GetBucketLocation
- s3:GetObject
- s3:ListBucket
- s3:ListBucketMultipartUploads
- s3:PutObject
Resource:
- !Ref BucketArn
- !Sub "${BucketArn}/*"
- Effect: Allow
Action:
- logs:PutLogEvents
Resource:
- !GetAtt LogGroup.Arn
Code language: YAML (yaml)Grant the necessary permissions to upload objects to the S3 bucket.
S3
Resources:
Bucket:
Type: AWS::S3::Bucket
Properties:
AccessControl: Private
BucketName: !Ref Prefix
Code language: YAML (yaml)Create an S3 bucket.
No special settings are required.
Architecting
Use CloudFormation to build this environment and check its actual behavior.
Create CloudFormation stacks and check the resources in the stacks
Create CloudFormation stacks.
For information on how to create stacks and check each stack, please see the following page.

After reviewing the resources in each stack, information on the main resources created in this case is as follows
- Lambda function: saa-04-003-LambdaStack-T6C4JQMN9F-DataSourceLambda-zPRZbuXE1gEC
- Kinesis Data Streams:saa-04-003-DataStream
- Kinesis Data Firehose: saa-04-003-FirehoseDeliveryStream
- S3 bucket: saa-04-003
Check each resource from the AWS Management Console.
Check the Lambda function.
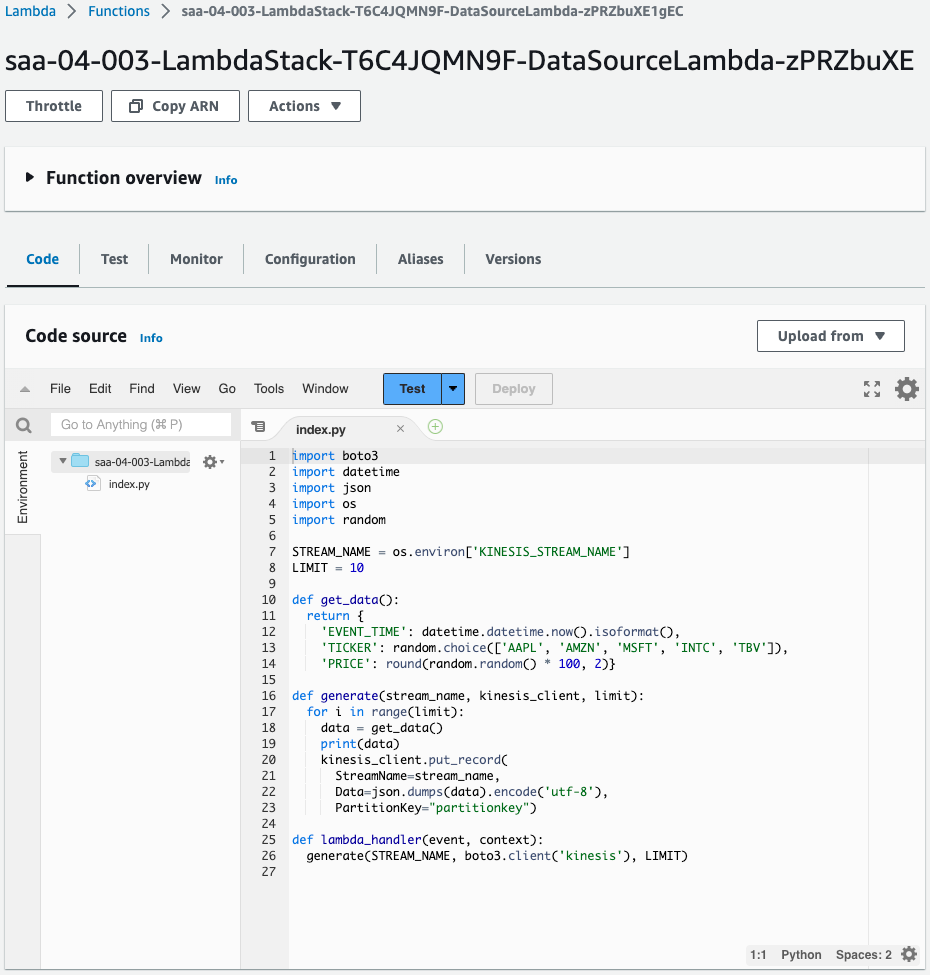
The function is successfully created.
Check Data Streams.
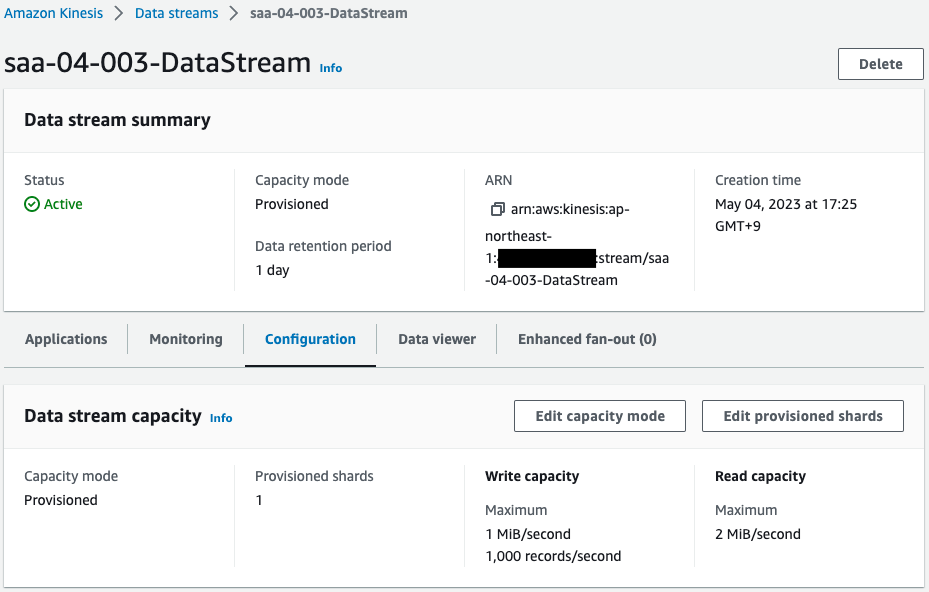
Data Streams are also successfully created.
You can see that the number of shards provisioned is “1”.
Check Data Firehose.
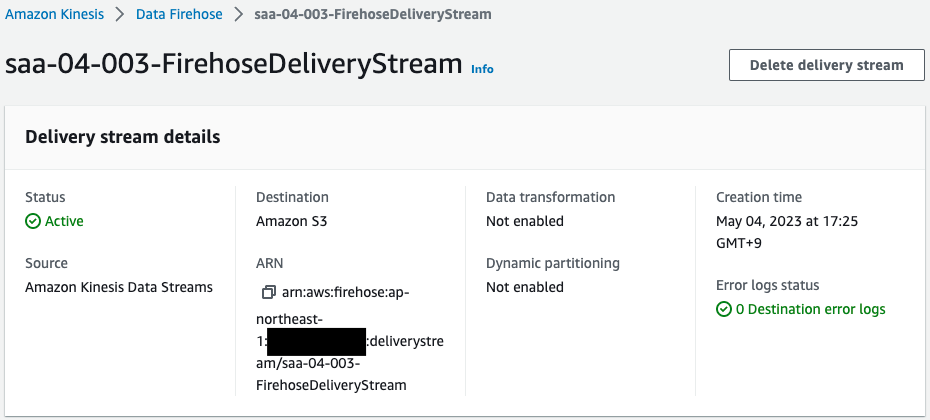

Data Firehose is also created successfully.
The settings (size, interval) for sending (buffer) to S3 bucket are default values.
Check the S3 bucket.
The bucket has been successfully created.
The bucket is empty at this time.
Action Check
Now that we are ready, we run the Lambda function to generate test data.
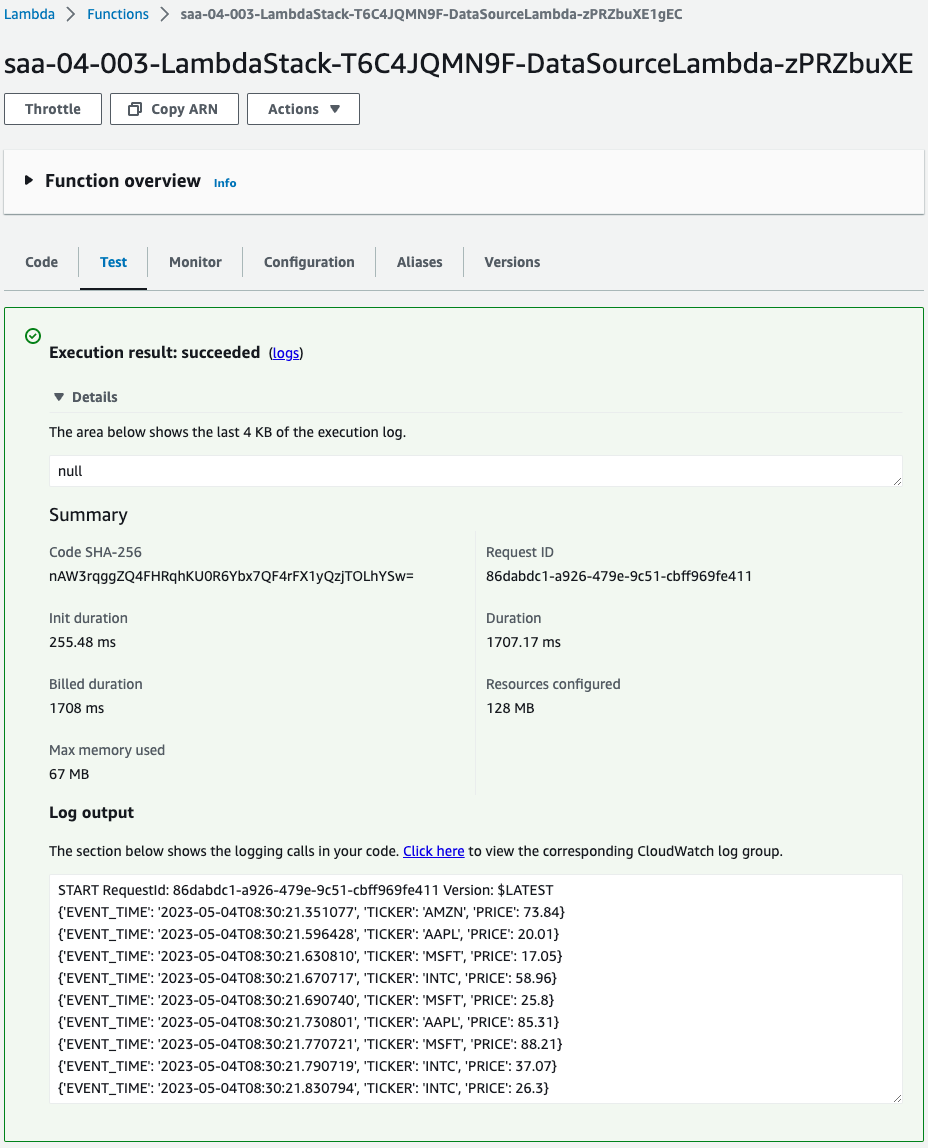
Indeed, 10 pieces of test data were generated.
The generated data should be delivered to Kinesis Data Streams.
Check Data Streams again.
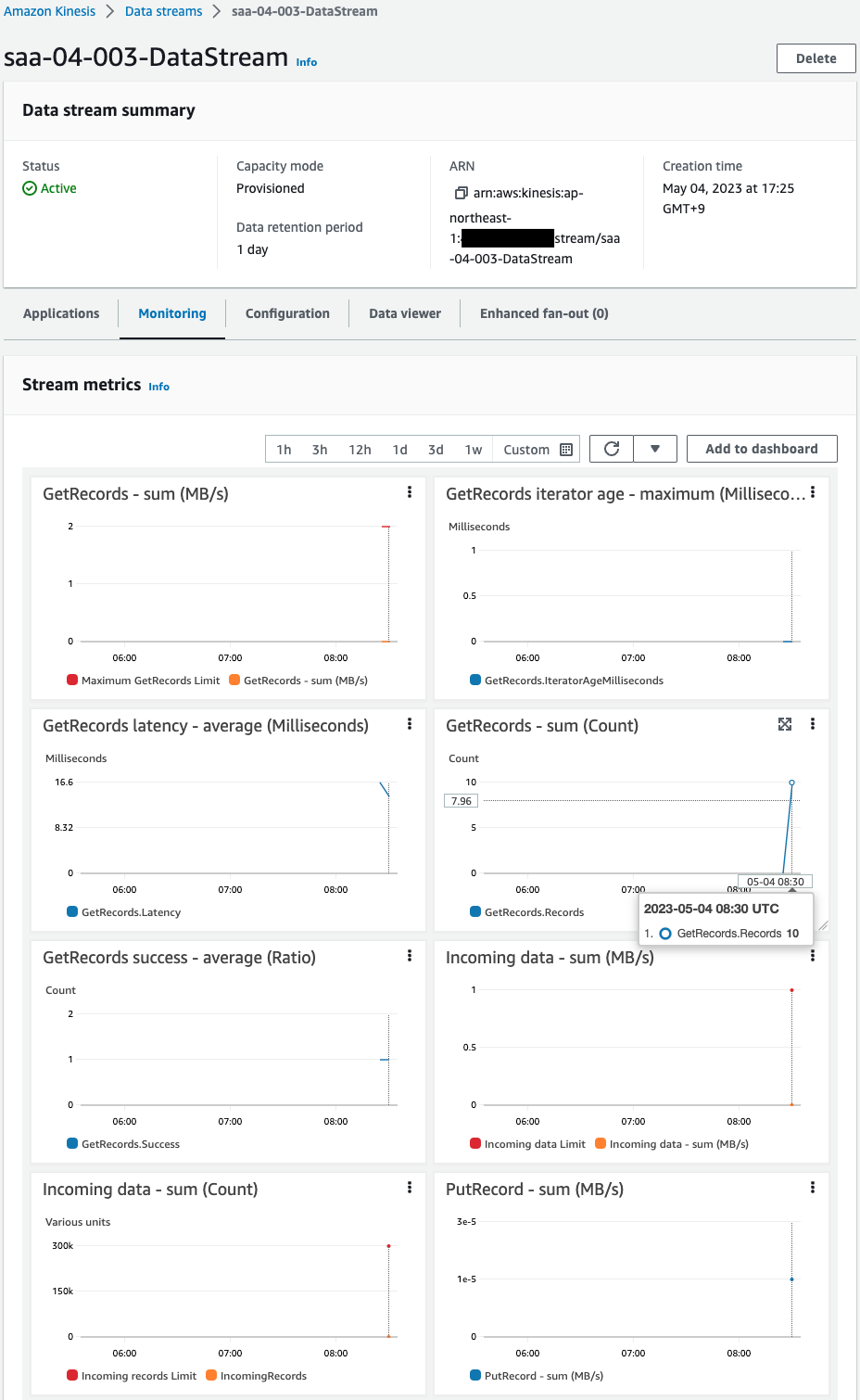
Checking the monitoring values, the GetRecords value is “10”.
This means that Data Streams has indeed received the data generated by the Lambda function.
Then check Kinesis Data Firehose.
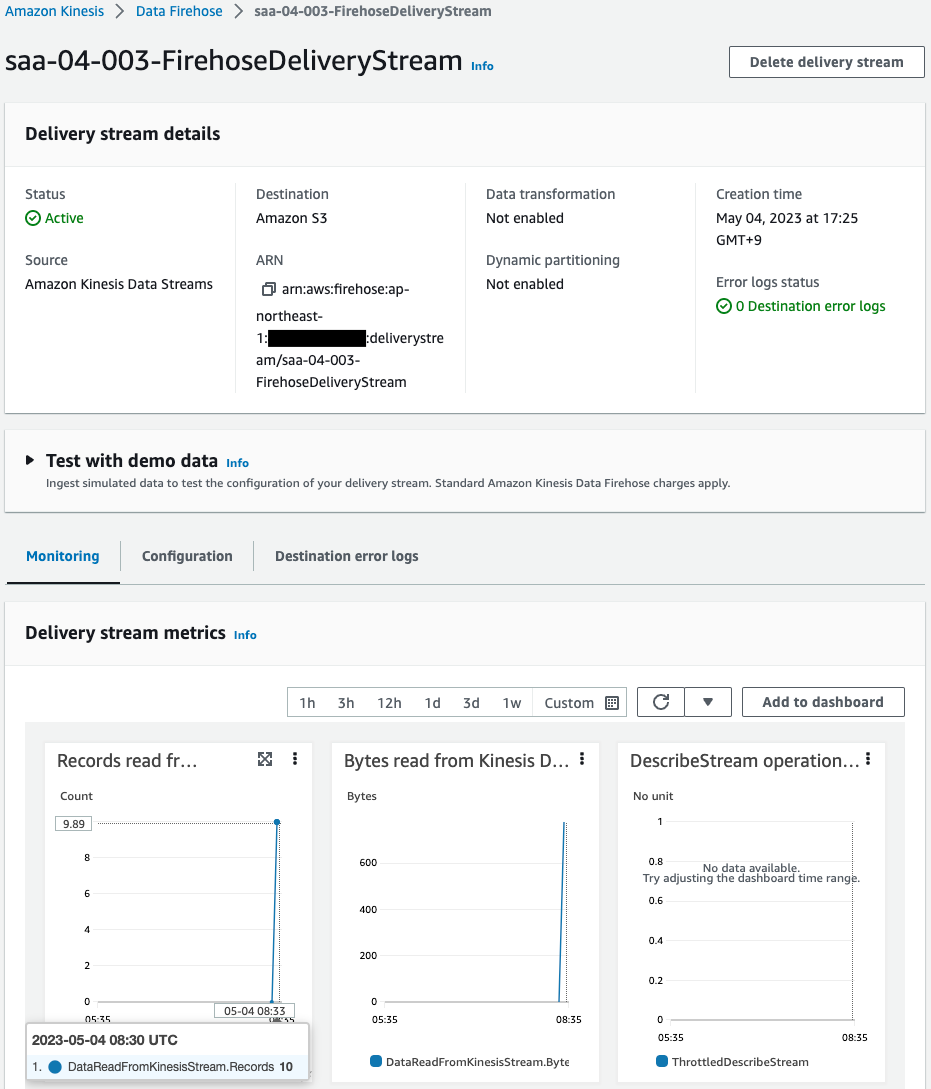
Checking the monitoring values, the Records read from Kinesis Data Streams (Sum) has a value of “10”.
This means that we have indeed received data from Data Streams.
Finally, check the S3 bucket.
Indeed, the file is placed in the bucket.
Check the contents.
{"EVENT_TIME": "2023-05-04T08:30:21.351077", "TICKER": "AMZN", "PRICE": 73.84}{"EVENT_TIME": "2023-05-04T08:30:21.596428", "TICKER": "AAPL", "PRICE": 20.01}{"EVENT_TIME": "2023-05-04T08:30:21.630810", "TICKER": "MSFT", "PRICE": 17.05}{"EVENT_TIME": "2023-05-04T08:30:21.670717", "TICKER": "INTC", "PRICE": 58.96}{"EVENT_TIME": "2023-05-04T08:30:21.690740", "TICKER": "MSFT", "PRICE": 25.8}{"EVENT_TIME": "2023-05-04T08:30:21.730801", "TICKER": "AAPL", "PRICE": 85.31}{"EVENT_TIME": "2023-05-04T08:30:21.770721", "TICKER": "MSFT", "PRICE": 88.21}{"EVENT_TIME": "2023-05-04T08:30:21.790719", "TICKER": "INTC", "PRICE": 37.07}{"EVENT_TIME": "2023-05-04T08:30:21.830794", "TICKER": "INTC", "PRICE": 26.3}{"EVENT_TIME": "2023-05-04T08:30:21.850728", "TICKER": "TBV", "PRICE": 96.26}Code language: JSON / JSON with Comments (json)This is the data that was just generated by the Lambda function.
Thus, stream data received by Kinesis Data Streams can be stored in S3 buckets via Firehose.
Summary
We have identified how stream data delivered to Kinesis Data Streams can be stored in S3 buckets using Kinesis Data Firehose.