Setting up RDS(Aurora Serverless) as Data Source for AppSync
AppSync allows you to select a data source from the following services
- Lambda
- DynamoDB
- OpenSearch
- None
- HTTP endpoint
- RDS
This time we will check the configuration with RDS as the data source.
The resource that can be specified as RDS is Aurora Serverless.
For a basic explanation of AppSync and the configuration with DynamoDB as the data source, please refer to the following page.

Environment
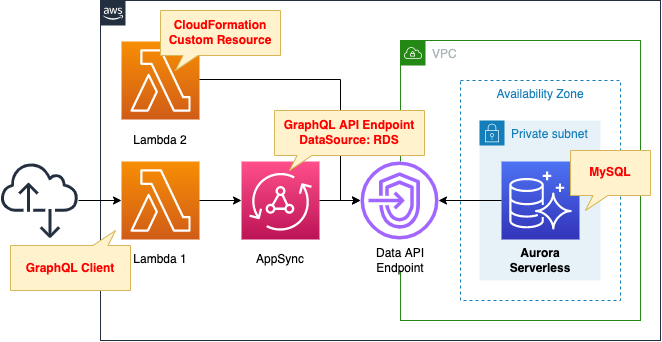
Create Aurora Serverless to act as a data source.
Define a schema resolver to operate Aurora Serverless from AppSync.
This page will proceed with reference to the following official AWS page.
https://docs.aws.amazon.com/appsync/latest/devguide/tutorial-rds-resolvers.html
Create two Lambda functions.
The runtime environment for the functions will be Python 3.8.
The first function will be associated with a CloudFormation custom resource and configured to run when the stack is created.
The function’s function is to initialize the Aurora Serverless DB.
The second function is configured as a client to run the GraphQL API.
Enable the Function URL so that the URL query parameter can specify the operation to be performed.
CloudFormation template files
Build the above configuration with CloudFormation.
The CloudFormation templates are located at the following URL
https://github.com/awstut-an-r/awstut-fa/tree/main/061
Explanation of key points of the template files
This page focuses on how to specify Aurora Serverless as the data source for AppSync.
For more information on creating Aurora Serverless, please refer to the following page

For information on how to activate the Data API of Aurora Serverless, please refer to the following page

Data Source
Resources:
DataSource:
Type: AWS::AppSync::DataSource
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
Name: DataSource
RelationalDatabaseConfig:
RdsHttpEndpointConfig:
AwsRegion: !Ref AWS::Region
AwsSecretStoreArn: !Ref SecretArn
DatabaseName: !Ref DBName
DbClusterIdentifier: !Ref DBClusterArn
RelationalDatabaseSourceType: RDS_HTTP_ENDPOINT
ServiceRoleArn: !GetAtt DataSourceRole.Arn
Type: RELATIONAL_DATABASE
Code language: YAML (yaml)The key point is the Type property.
When Aurora Serverless is used as the data source, specify “RDS_HTTP_ENDPOINT”.
Also, set the details in RelationalDatabaseConfig property.
Specify the ARN of the Aurora Serverless cluster, the Secrets Manager secret used to connect to the cluster, etc.
IAM Roles for Data Source
Resources:
DataSourceRole:
Type: AWS::IAM::Role
Properties:
AssumeRolePolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action: sts:AssumeRole
Principal:
Service: appsync.amazonaws.com
Policies:
- PolicyName: !Sub "${Prefix}-DataSourcePolicy"
PolicyDocument:
Version: 2012-10-17
Statement:
- Effect: Allow
Action:
- rds-data:DeleteItems
- rds-data:ExecuteSql
- rds-data:ExecuteStatement
- rds-data:GetItems
- rds-data:InsertItems
- rds-data:UpdateItems
Resource:
- !Ref DBClusterArn
- !Sub "${DBClusterArn}:*"
- Effect: Allow
Action:
- secretsmanager:GetSecretValue
Resource:
- !Ref SecretArn
- !Sub "${SecretArn}:*"
Code language: YAML (yaml)IAM role for AppSync to connect to Aurora Serverless and execute SQL statements.
It was created with reference to the policy introduced on the official AWS website.
Schema
Resources:
GraphQLSchema:
Type: AWS::AppSync::GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
Definition: |
type Mutation {
createPet(input: CreatePetInput!): Pet
updatePet(input: UpdatePetInput!): Pet
deletePet(input: DeletePetInput!): Pet
}
input CreatePetInput {
type: PetType
price: Float!
}
input UpdatePetInput {
id: ID!
type: PetType
price: Float!
}
input DeletePetInput {
id: ID!
}
type Pet {
id: ID!
type: PetType
price: Float
}
enum PetType {
dog
cat
fish
bird
gecko
}
type Query {
getPet(id: ID!): Pet
listPets: [Pet]
listPetsByPriceRange(min: Float, max: Float): [Pet]
}
schema {
query: Query
mutation: Mutation
}
Code language: YAML (yaml)Define the schema with reference to the official AWS page.
Resolver
Resolvers are also created with reference to the official AWS page.
The following is a reference of a resolver for createPet mutation.
Resources:
CreatePetResolver:
Type: AWS::AppSync::Resolver
DependsOn:
- GraphQLSchema
Properties:
ApiId: !GetAtt GraphQLApi.ApiId
DataSourceName: !GetAtt DataSource.Name
FieldName: createPet
Kind: UNIT
RequestMappingTemplate: |
#set($id=$utils.autoId())
{
"version": "2018-05-29",
"statements": [
"insert into Pets VALUES ('$id', '$ctx.args.input.type', $ctx.args.input.price)",
"select * from Pets WHERE id = '$id'"
]
}
ResponseMappingTemplate: |
$utils.toJson($utils.rds.toJsonObject($ctx.result)[1][0])
TypeName: Mutation
Code language: YAML (yaml)Describe the template mappings introduced on the official page in the RequestMappingTemplate and ResponseMappingTemplate properties.
(Reference) GraphQL Client Lambda Function
Create a Lambda function as a client to execute GraphQL API by AppSync.
Enable the Function URL for this function.
For more information on Function URL, please refer to the following page.

The following is the Python code to be executed by the function.
import json
import os
import time
from gql import Client, gql
from gql.transport.aiohttp import AIOHTTPTransport
api_key = os.environ['API_KEY']
graphql_url = os.environ['GRAPHQL_URL']
transport = AIOHTTPTransport(
url=graphql_url,
headers={
'x-api-key': api_key
})
client = Client(transport=transport, fetch_schema_from_transport=True)
CREATE_PET = 'createPet'
UPDATE_PET = 'updatePet'
DELETE_PET = 'deletePet'
GET_PET = 'getPet'
LIST_PETS = 'listPets'
LIST_PETS_BY_PRICE_RANGE = 'listPetsByPriceRange'
def lambda_handler(event, context):
operation = ''
document = None
result = None
if not 'queryStringParameters' in event or (
not 'operation' in event['queryStringParameters']):
operation = LIST_PETS
else:
operation = event['queryStringParameters']['operation']
if operation == CREATE_PET:
document = gql(
"""
mutation add($type: PetType!, $price: Float!) {
createPet(input: {
type: $type,
price: $price
}){
id
type
price
}
}
"""
)
params = {
'type': event['queryStringParameters']['type'],
'price': event['queryStringParameters']['price']
}
result = client.execute(document, variable_values=params)
elif operation == UPDATE_PET:
document = gql(
"""
mutation update($id: ID!, $type: PetType!, $price: Float!) {
updatePet(input: {
id: $id,
type: $type,
price: $price
}){
id
type
price
}
}
"""
)
params = {
'id': event['queryStringParameters']['id'],
'type': event['queryStringParameters']['type'],
'price': event['queryStringParameters']['price']
}
result = client.execute(document, variable_values=params)
elif operation == DELETE_PET:
document = gql(
"""
mutation delete($id: ID!) {
deletePet(input: {
id: $id
}){
id
type
price
}
}
"""
)
params = {
'id': event['queryStringParameters']['id']
}
result = client.execute(document, variable_values=params)
elif operation == GET_PET:
document = gql(
"""
query get($id: ID!) {
getPet(id: $id){
id
type
price
}
}
"""
)
params = {
'id': event['queryStringParameters']['id']
}
result = client.execute(document, variable_values=params)
elif operation == LIST_PETS:
document = gql(
"""
query allpets {
listPets {
id
type
price
}
}
"""
)
result = client.execute(document)
elif operation == LIST_PETS_BY_PRICE_RANGE:
document = gql(
"""
query list($min: Float!, $max: Float!) {
listPetsByPriceRange(min: $min, max: $max) {
id
type
price
}
}
"""
)
params = {
'min': event['queryStringParameters']['min'],
'max': event['queryStringParameters']['max']
}
result = client.execute(document, variable_values=params)
return {
'statusCode': 200,
'body': json.dumps(result, indent=2)
}
Code language: Python (python)This is the code for the Lambda function that executes the GraphQL query.
In this case, we will use GQL as the GraphQL client library for Python.
https://github.com/graphql-python/gql
We will use GQL to execute the query mutations defined in the schema.
In Python, you can use event[‘queryStringParameters’] to retrieve URL query parameters.
The URL query parameters are used to pass the necessary parameters.
The operation parameter specifies the GraphQL query to be executed.
(Reference) CloudFormation Custom Resources
CloudFormation custom resources are used to perform the initialization process of Aurora Serverless.
For more information on how to initialize Aurora Serverless using CloudFormation custom resources, please refer to the following page

The following is a Lambda function to be executed as a custom resource.
Resources:
Function2:
Type: AWS::Lambda::Function
Properties:
Environment:
Variables:
DBCLUSTER_ARN: !Ref DBClusterArn
DBNAME: !Ref DBName
DBTABLE: !Ref DBTableName
REGION: !Ref AWS::Region
SECRET_ARN: !Ref SecretArn
Code:
ZipFile: |
import boto3
import cfnresponse
import json
import os
dbcluster_arn = os.environ['DBCLUSTER_ARN']
dbname = os.environ['DBNAME']
dbtable = os.environ['DBTABLE']
region = os.environ['REGION']
secret_arn = os.environ['SECRET_ARN']
sql1 = 'create table {table}(id varchar(200), type varchar(200), price float)'.format(table=dbtable)
client = boto3.client('rds-data', region_name=region)
schema = 'mysql'
CREATE = 'Create'
response_data = {}
def lambda_handler(event, context):
try:
if event['RequestType'] == CREATE:
response1 = client.execute_statement(
database=dbname,
resourceArn=dbcluster_arn,
schema=schema,
secretArn=secret_arn,
sql=sql1
)
print(response1)
cfnresponse.send(event, context, cfnresponse.SUCCESS, response_data)
except Exception as e:
print(e)
cfnresponse.send(event, context, cfnresponse.FAILED, response_data)
FunctionName: !Sub "${Prefix}-function2"
Handler: !Ref Handler
Runtime: !Ref Runtime
Role: !GetAtt FunctionRole2.Arn
Code language: YAML (yaml)Architecting
Using CloudFormation, we will build this environment and check its actual behavior.
Preliminary Preparation
Make the following two preparations
- Prepare a deployment package for the Lambda function and upload it to the S3 bucket
- Prepare a deployment package for the Lambda layer and upload it to the S3 bucket.
The command to create a package for the Lambda layer is as follows
$ sudo pip3 install --pre gql[all] -t python
zip -r layer.zip python
Code language: Bash (bash)For more information on Lambda layer, please refer to the following page

Create CloudFormation stacks and check resources in stacks
Create a CloudFormation stacks.
For more information on creating stacks and checking each stack, please refer to the following page

After checking the resources in each stack, information on the main resources created this time is as follows
- AppSync API: fa-061-GraphQLApi
- ID of Aurora Serverless: fa-061-dbcluster
- Function URL for GraphQL client Lambda function: https://dzmbqhvhyhkzm4pyufkzmketsy0gdoxt.lambda-url.ap-northeast-1.on.aws/
Check AppSync from the AWS Management Console.
First is the data source.
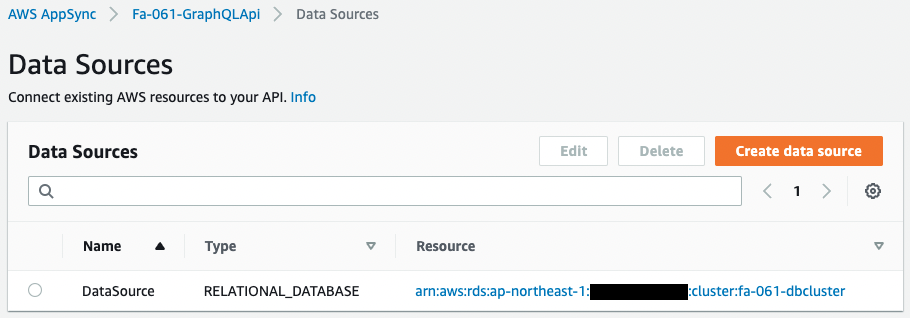
Looking at the data source, the Type is “RELATIONAL_DATABASE”.
Aurora Serverless is successfully set as the data source.
Next, check the schema resolver.
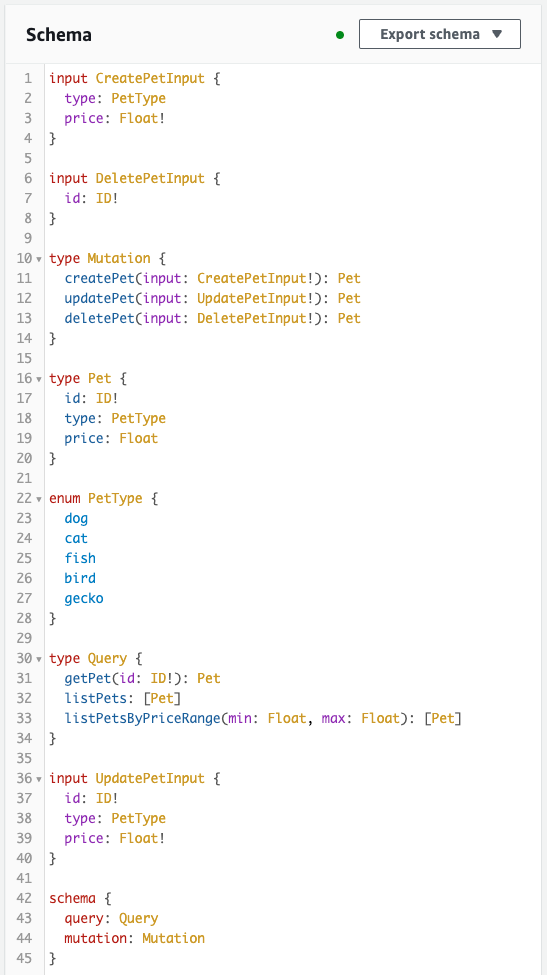
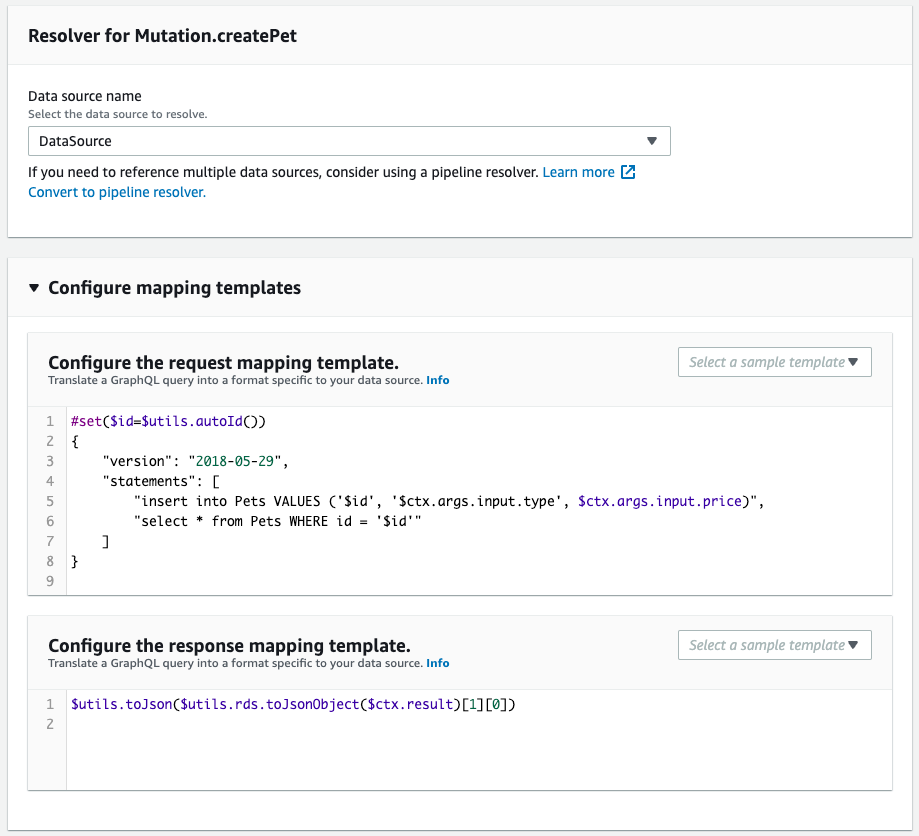
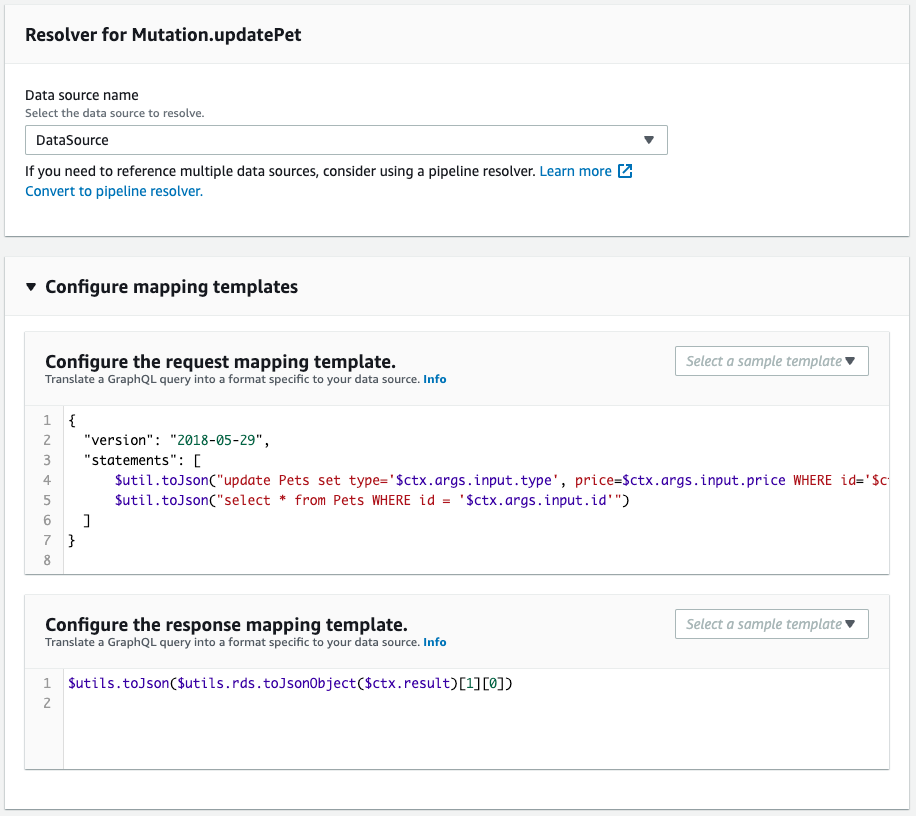
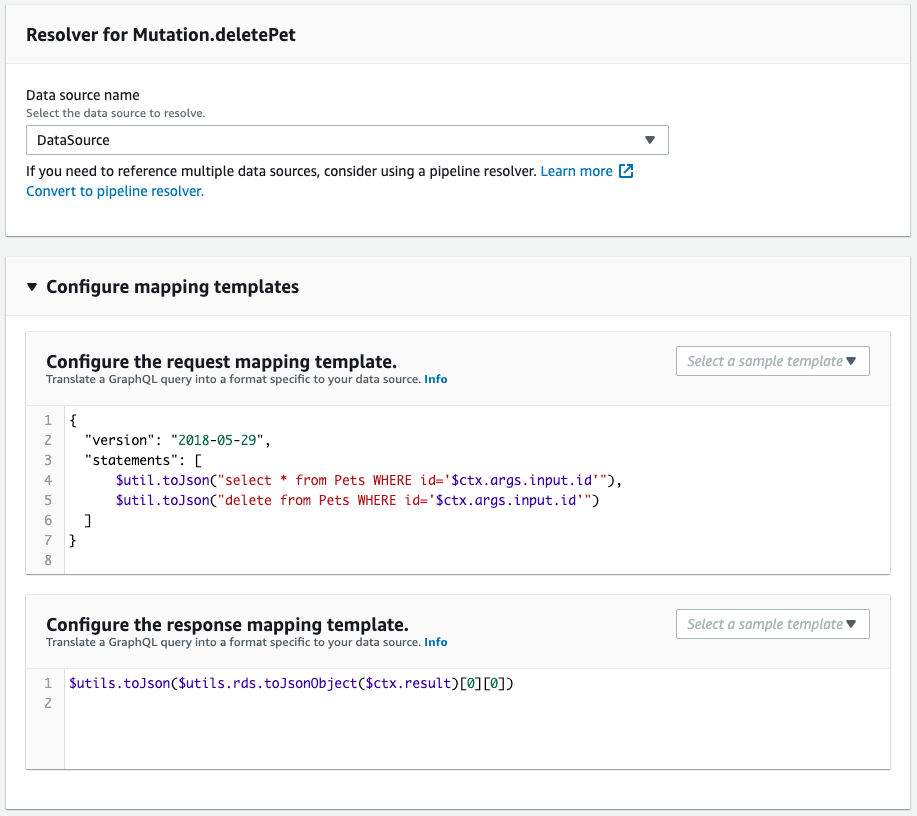
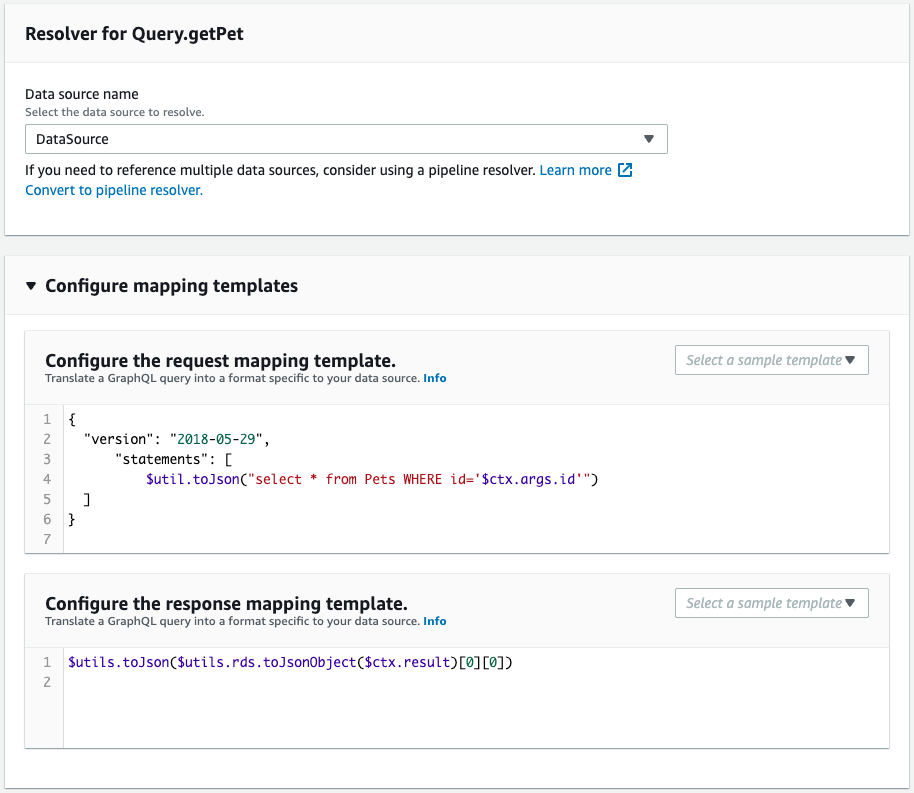
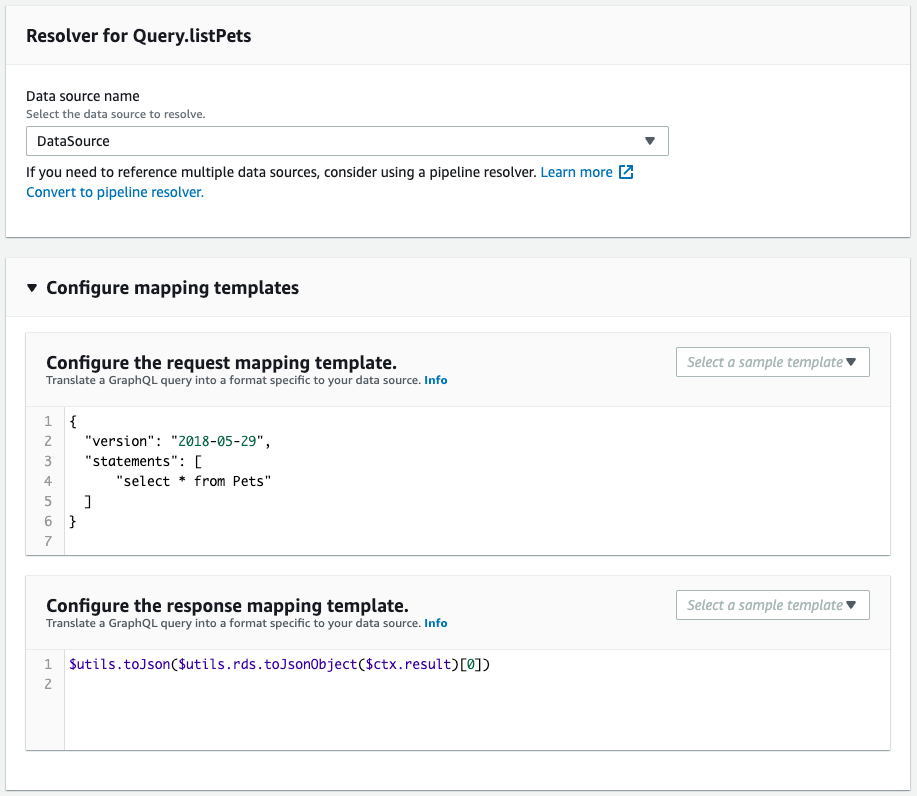
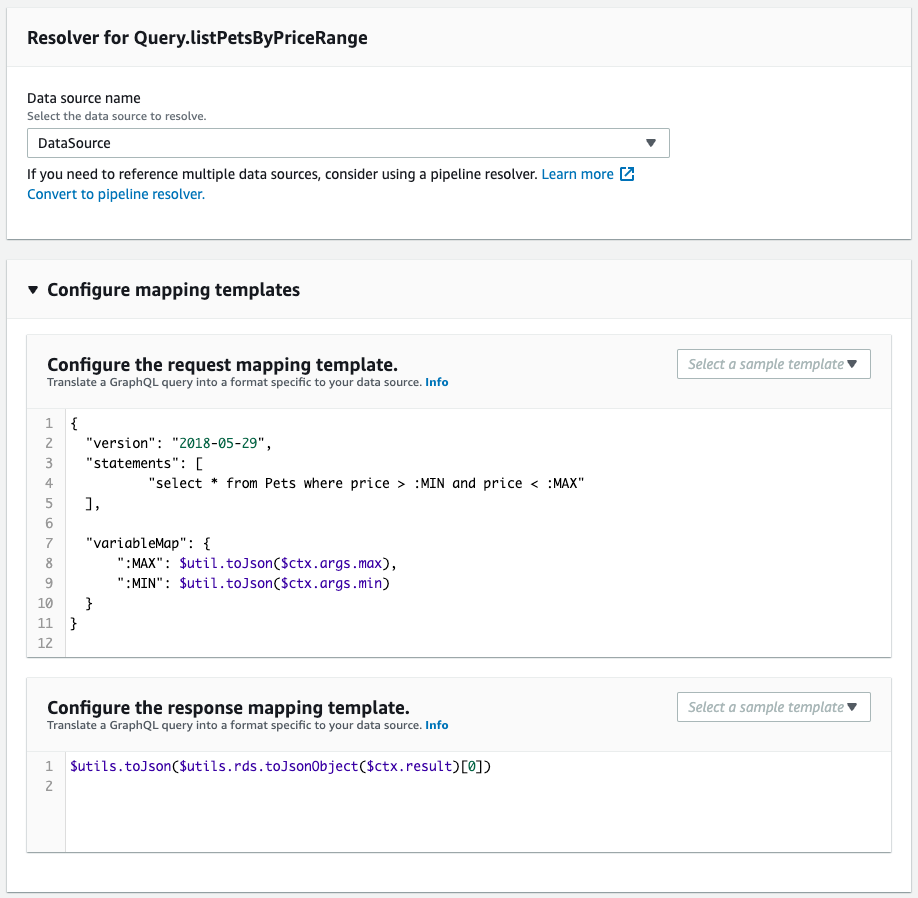
It is created as defined in the CloudFormation template file.
Next, check Aurora Serverless.
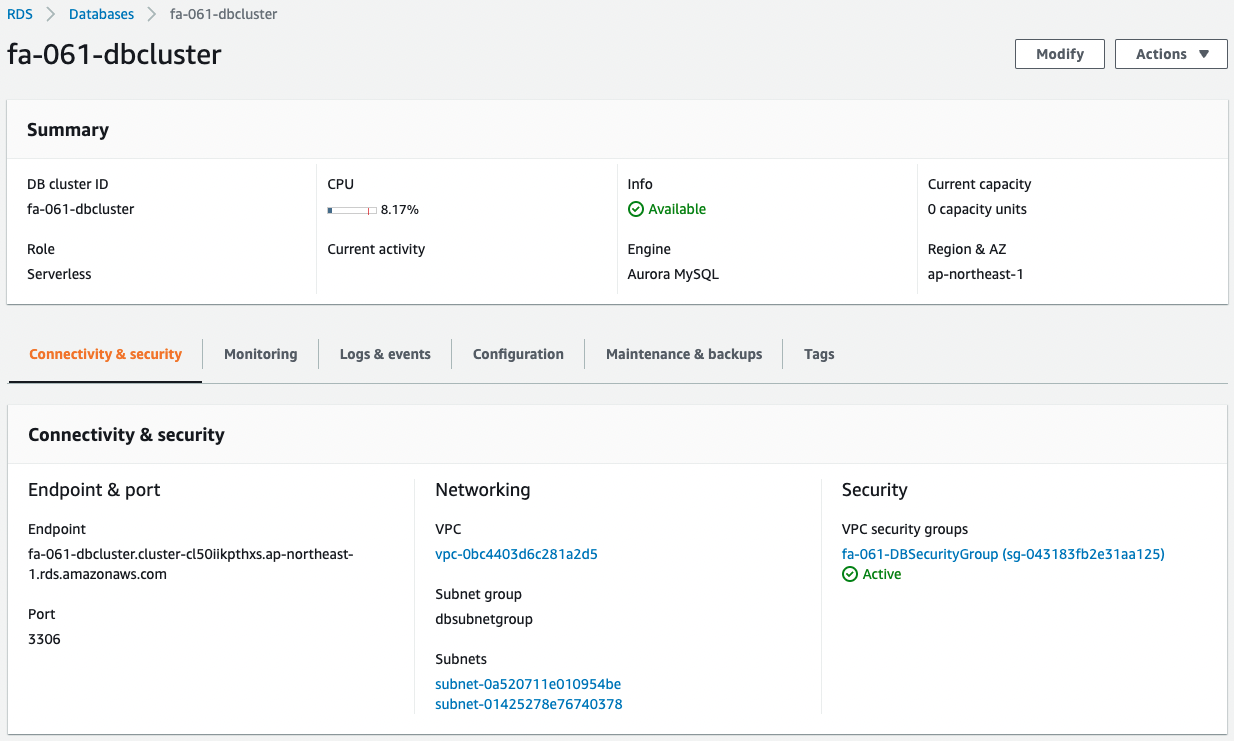
This is also successfully created.
Checking Action
Now that everything is ready, access the Function URL of the GraphQL client Lambda function.
createPet
First, save the data.
Specify “createPet” as the operation value in the URL query, and any values for type and price.
This will execute the following GraphQL query
mutation add($type: PetType!, $price: Float!) {
createPet(input: {
type: $type,
price: $price
}){
id
type
price
}
}
Code language: plaintext (plaintext)The following is the result of the execution.

Data was successfully added.
getPet
Next, data is acquired by specifying an ID.
Specify “getPet” in the operation value of the URL query and the ID we just checked.
This will execute the following GraphQL query
query get($id: ID!) {
getPet(id: $id){
id
type
price
}
}
Code language: plaintext (plaintext)The following is the result of the execution.

The data just saved is returned.
updatePet
Next, we update the data by specifying the ID.
Set “updatePet” to the operation value in the URL query, the ID we just checked to id, and any value to type and price.
This will result in the following GraphQL query
mutation update($id: ID!, $type: PetType!, $price: Float!) {
updatePet(input: {
id: $id,
type: $type,
price: $price
}){
id
type
price
}
}
Code language: plaintext (plaintext)The following is the execution result.

The type value has been updated from “fish” to “bird” and the price value from “10.0” to “50.0”.
listPets
Before executing listPets, run getPet again to add data.
Get a list of stored data.
Specify “listPets” as the operation value in the URL query.
This will execute the following GraphQL query
query allpets {
listPets {
id
type
price
}
}
Code language: plaintext (plaintext)The following is the result of the execution.
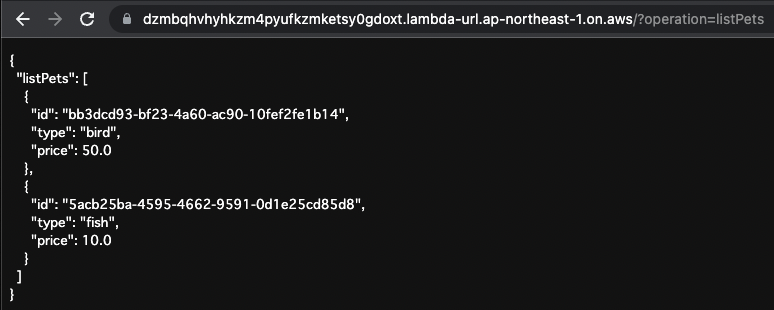
Two stored data were returned.
listPetsByPriceRange
Retrieves stored data after conditioning on the value of price.
Set “listPetsByPriceRange” to the operation value in the URL query and any values for min and max.
This will execute the following GraphQL query
query list($min: Float!, $max: Float!) {
listPetsByPriceRange(min: $min, max: $max) {
id
type
price
}
}
Code language: plaintext (plaintext)The following is the execution result.
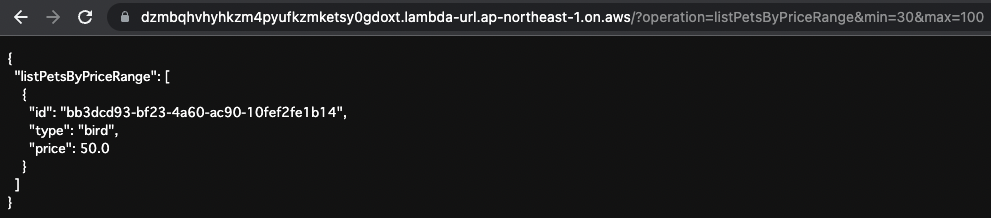
Data for “bird” satisfying the condition 30<=price<=100 was returned.
deletePet
Deletes data by specifying an ID.
Set “deletePet” to the operation value of the URL query and the ID of the stored data to the id.
This will execute the following GraphQL query
mutation delete($id: ID!) {
deletePet(input: {
id: $id
}){
id
type
price
}
}
Code language: plaintext (plaintext)The following is the result of the execution.

The “bird” data has been deleted.
Execute listPets again.
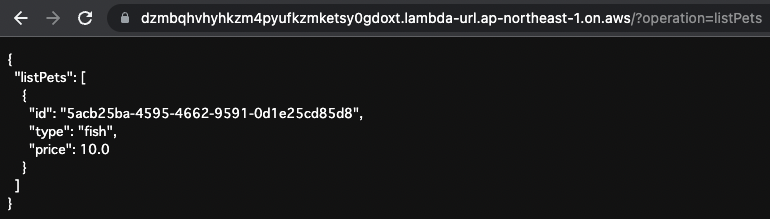
Only the data for “fish” was returned.
You can see that “bird” has been deleted.
Summary
We have introduced the configuration of Aurora Serverless as a data source for AppSync.